시작에 앞서
해당 내용은 '<파이썬 머신러닝 완벽 가이드> 권철민 지음. 위키북스' 를 토대로 작성되었습니다. 보다 자세한 내용은 해당 서적에 상세히 나와있으니 서적을 참고해 주시기 바랍니다.
네이버 도서
책으로 만나는 새로운 세상
search.shopping.naver.com
이전 내용
[파이썬] 판다스 (Pandas) - 2
시작에 앞서해당 내용은 ' 권철민 지음. 위키북스' 를 토대로 작성되었습니다. 보다 자세한 내용은 해당 서적에 상세히 나와있으니 서적을 참고해 주시기 바랍니다. 네이버 도서책으로 만나는
puppy-foot-it.tistory.com
데이터 셀렉션 및 필터링
넘파이의 데이터 핸들링은 데이터 분석용으로 사용하기에는 편의성이 떨어지기 때문에 판다스는 이를 개선하는 과정에서 넘파이의 기능을 일부 계승하기도 하고, 넘파이와는 완전히 다른 기능을 제공하기도 한다.
판다스의 DataFrame과 Series 끼리도 이러한 데이터 셀력신 기능이 달라지는 부분이 있어 주의가 필요하다.
- 넘파이: [ ] 연산자 내 단일 값 추출, 슬라이싱, 팬시 인덱싱, 불린 인덱싱을 통해 데이터를 추출
- 판다스: iloc[ ], loc[ ] 연산자를 통해 동일 작업 수행
DataFrame의 [ ] 연산자
넘파이에서 [ ] 연산자는 행의 위치, 열의 위치, 슬라이싱 범위 등을 지정해 데이터를 가져올 수 있었으나, DataFrame 바로 뒤에 있는 [ ] 안에 들어갈 수 있는 것은 칼럼명 문자(또는 리스트 객체), 또는 인덱스로 변환 가능한 표현식이다.
여러 개의 칼럼에서 데이터를 추출: DataFrame명['칼럼1', '칼럼2']와 같이 리스트 객체 이용
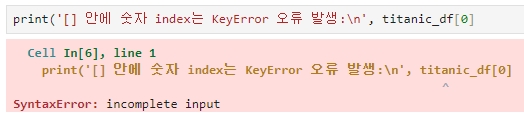
단, DataFrame명[0], 또는 [0, 1, 2] 와 같은 표현식은 칼럼명이 아니기 때문에 오류를 발생한다.
이를 직접 수행해보면,

◆ 슬라이싱
DataFrame의 [ ] 내에 숫자 값을 입력할 경우 오류가 발생하는데, 판다스는 인덱스 형태로 변환 가능한 표현식은 [ ] 내에 입력할 수 있다.
예를들어, DataFrame 의 처음 3개 데이터를 추출하고자 슬라이싱을 이용한다면

◆ 불린 인덱싱

[ ] 내의 불린 인덱싱 기능은 원하는 데이터를 편리하게 추출해주므로 매우 자주 사용된다,
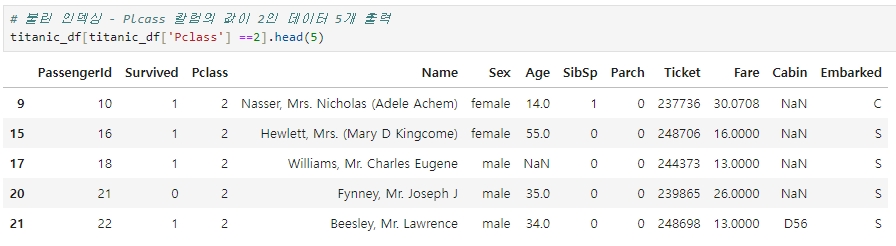
예를들어, 다음 DataFrame에서 Pclass 칼럼 값이 2인 데이터를 5개만 추출하고자 한다면,
★ DataFrame[ ] 연산자 관련 정리 (with Chat GPT)
- DataFrame[ ] 바로 뒤의 [ ] 연산자: 넘파이의 [ ] 나 Series[ ] 와 다르다.
- DataFrame[ ] 바로 뒤의 [ ] 내 입력값: 칼럼명(또는 칼럼의 리스트)을 지정해 칼럼 지정 연산에 사용하거나 불린 인덱스 용도로만 사용해야 한다.
- DataFrame[0:2] 와 같은 슬라이싱 연산으로 데이터를 추출하는 방법은 사용하지 않는 게 좋다.

DataFrame iloc[ ] 연산자
판다스는 DataFrame의 로우나 칼럼을 지정하여 데이터를 선택할 수 있는 인덱싱 방식으로 iloc[ ] 와 loc[ ] 를 제공한다.
- iloc[ ] : 위치(Location) 기반 인덱싱 방식으로 동작. 행과 열 위치를, 0을 출발점으로 하는 세로축, 가로축 좌표 정숫값으로 지정하는 방식. (위치 기반 인덱싱)
- loc[ ] : 명칭(Label) 기반 인덱싱 방식으로 동작. 데이터 프레임의 인덱스 값으로 행 위치를, 칼럼의 명칭으로 열 위치를 지정하는 방식. (명칭 기반 인덱싱)
iloc[ ] 는 위치 기반 인덱싱만 허용하기 때문에 행과 열의 좌표 위치에 해당하는 값으로 정숫값 또는 정수형의 슬라이싱, 팬시 리스트 값을 입력해줘야 한다. 또한, 슬라이싱과 팬시 인덱싱은 제공하나 명확한 위치 기반 인덱싱이 사용되어야 하는 제약으로 인해 불린 인덱싱은 제공하지 않는다.
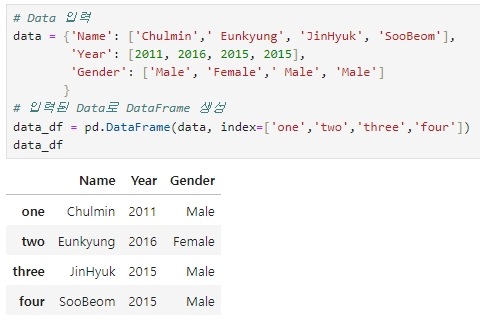
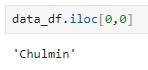
먼저 위 예제의 DataFrame인 data_df의 첫 번째 행, 첫 번째 열의 데이터를 iloc[ ] 를 통해 추출
▶ DataFrame명.iloc[행, 열]
위치 기반 인덱싱이기 때문에 인덱스 값이나 칼럼명을 입력하면 오류가 발생한다.
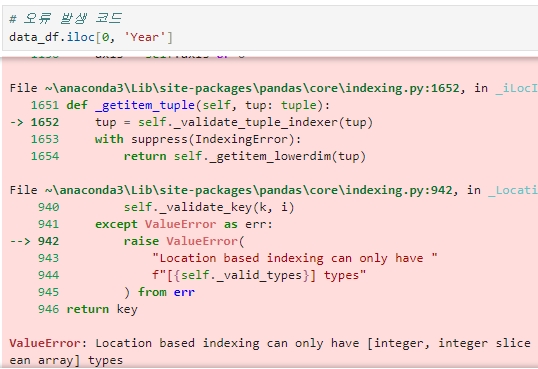
★ iloc[ : , -1] & iloc[ : , :-1]
iloc[ ] 는 열 위치에 -1을 입력하여 DataFrame의 가장 마지막 열 데이터를 가져오는 데 자주 사용한다.
넘파이와 마찬가지로 판다스의 인덱싱에서도 -1은 맨마지막 데이터 값을 의미한다.
- iloc[:, -1] : 맨 마지막 칼럼의 값 (타깃 값) 가져오기
- iloc[ : , :-1] : 처음부터 맨 마지막 칼럼을 제외한 모든 칼럼의 값 (피처 값) 가져오기
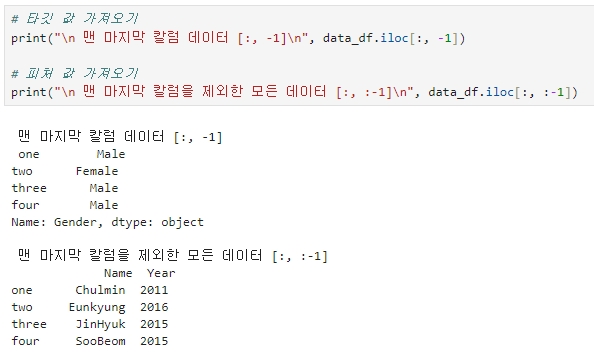
▶ 첫번째 코드는 맨 마지막 칼럼인 성별만 가져오고, 두번째 코드는 맨 마지막 칼럼인 성별을 제외한 나머지 칼럼(이름, 연도) 를 가져온다.
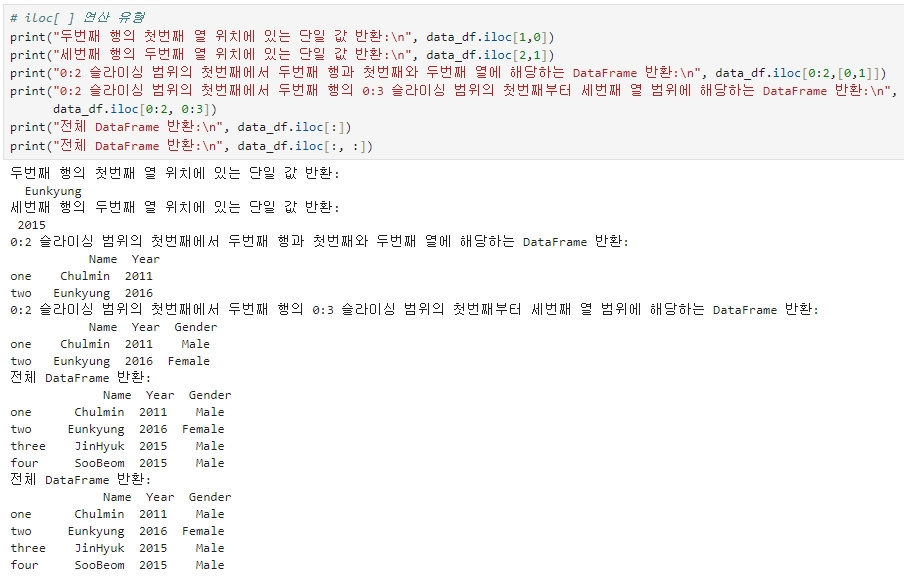
★ iloc[ ] 연산 유형
DataFrame loc[ ] 연산자
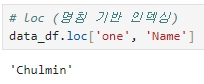
loc[ ] 는 명칭(Label) 기반으로 데이터를 추출한다.
행 위치에는 인덱스 값을, 열 위치에는 칼럼명을 입력해서 loc[인덱스값, 칼럼명]와 같은 형식으로 데이터를 추출할 수 있다.
iloc[ ] 가 위치 기반 인덱싱이라 인덱스 값 또는 칼럼명 값이 들어가면 오류가 발생했던 것과는 반대로 loc[ ] 는 명칭 기반 인덱싱이므로 loc[ ] 내에 정숫값을 입력하면 오류가 발생한다.
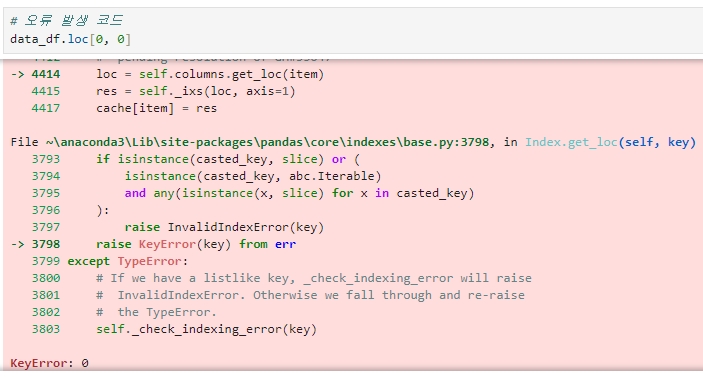
★ loc[ ] 에 슬라이싱 기호 ':' 를 적용할 때 유의할 점
일반적으로 슬라이싱을 '시작값 : 종료 값'과 같이 지정하면 시작 값 ~ 종료 값 -1 까지의 범위를 의미하는데,
(예. 0:3 ▶ 0부터 2까지) loc[ ] 슬라이싱 기호를 적용하면 종료 값-1이 아니라 종료 값까지 포함한다. (예. 0:3 ▶ 0부터 3까지)
이는 명칭 기반 인덱싱의 특성 때문이며, 명칭은 숫자형이 아닐 수 있기 때문에 -1을 할 수가 없다.
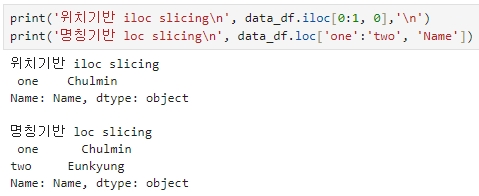
▶ 위치기반 iloc는 0번째 행 위치에 해당하는 1개의 행 반환
▶ 명칭기반 loc는 0~1번째 행 2개의 행 반환
★ loc[ ] 연산의 다양한 수행 사례

[ ] , iloc[ ] , loc[ ] 의 특징과 주의할 점 정리
- 개별 또는 여러 칼럼 값 전체를 추출하고자 한다면 iloc[ ] 나 loc[ ] 를 사용하지 않고 DataFrame명['칼럼명']만으로 충분하다. (예. data_df['Name']) 하지만 행과 열을 함께 사용하여 데이터를 추출해야 한다면 iloc[ ] 나, loc[ ] 를 사용해야 한다.
- iloc[ ] 와 loc[ ] 를 이해하기 위해서는 명칭 기반 인덱싱과 위 치 기반 인덱싱의 차이를 먼저 이해해야 한다. DataFrame의 인덱스나 칼럼명으로 데이터에 접근하는 것은 명칭 기반 인덱싱이며, 0부터 시작하는 행, 열의 위치 좌표에만 의존하는 것이 위치 기반 인덱싱이다.
- iloc[ ] 는 위치 기반 인덱싱만 가능하다. 따라서 행과 열 위치 값으로 정수형 값을 지정해 원하는 데이터를 반환하며, [ ] 내에 칼럼명 또는 인덱스를 넣으면 오류가 발생한다.
- loc[ ] 는 명칭 기반 인덱싱만 가능하다. 따라서 행 위치에 DataFrame 인덱스가, 열 위치에 칼럼명을 지정해 원하는 데이터를 반환한다.
- 명칭 기반 인덱싱에서 슬라이싱을 '시작점:종료점' 으로 지정할 때 시작점에서 종료점을 포함한 위치에 있는 데이터를 반환한다.
- iloc[ ] 는 불린 인덱싱이 불가하며, loc[ ] 는 가능하다. 불린 인덱싱은 특정 조건에 해당하는 인덱스 위치에 있는 데이터를 반환하는 것을 말한다.
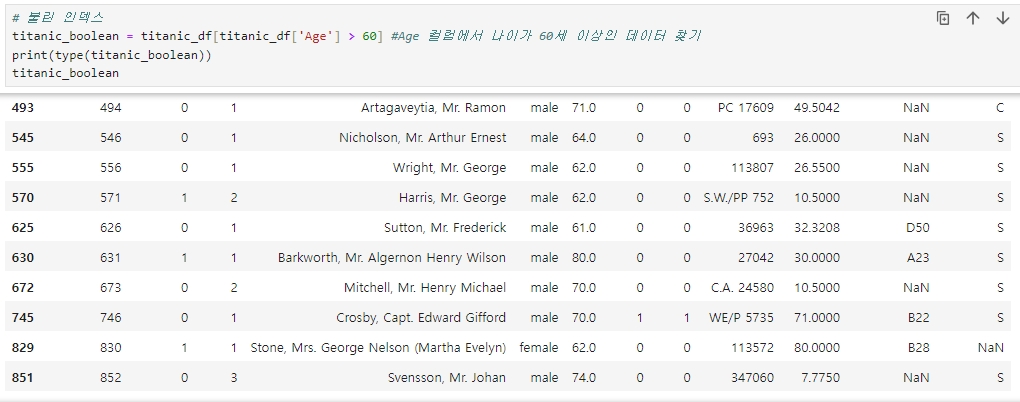
불린 인덱싱
불린 인덱싱은 매우 편리한 데이터 필터링 방식이다. iloc나 loc와 같이 명확히 인덱싱을 지정하는 방식보다는 처음부터 가져올 값을 조건으로 [ ] 내에 입력하면 자동으로 원하는 값을 필터링 하기 때문에 불린 인덱싱에 의존해 데이터를 가져오는 경우가 더 많다.
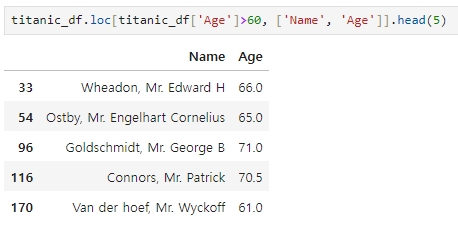
★ 조건에 맞는 데이터 중 일부 칼럼만 추출하기
예를들어, 60세 이상인 승객의 나이와 이름만 추출할 때 [ ] 연산자에 칼럼명을 입력하면 되는데, 칼럼이 두 개 이상이므로 [[ ]] 사용하면 된다.
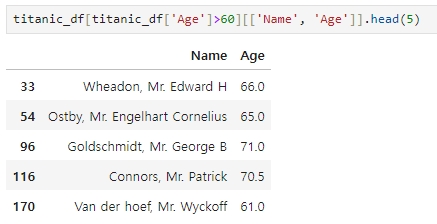
loc[ ] 를 이용해도 동일하게 적용할 수 있다. 단, ['Name', 'Age']는 칼럼 위치에 놓여야 한다.
★ 복합 조건 결합하여 적용하기
- and 조건일 때는 &
- or 조건일 때는 |
- Not 조건일 때는 ~
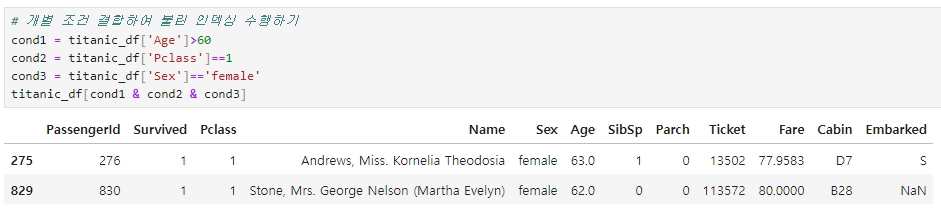
예를들어, 나이가 60세 이상이고 (Age > 60), 선실 등급이 1등급이며 (Pclass = 1), 성별이 여성인(Sex = female) 승객을 추출해야 한다면 개별 조건은 ( ) 로 묶고, 복합 조건 연산자를 사용하면 된다

또는, 아래와 같이 개별 조건을 변수에 할당하고 이들 변수를 결합해서 불린 인덱싱을 수행할 수도 있다.
다음글
[파이썬] 판다스 (Pandas) - 4
시작에 앞서해당 내용은 ' 권철민 지음. 위키북스' 를 토대로 작성되었습니다. 보다 자세한 내용은 해당 서적에 상세히 나와있으니 서적을 참고해 주시기 바랍니다. 네이버 도서책으로 만나는
puppy-foot-it.tistory.com
'[파이썬 Projects] > <파이썬 기초>' 카테고리의 다른 글
| [파이썬] 판다스 (Pandas) - 5 (0) | 2024.05.29 |
|---|---|
| [파이썬] 판다스 (Pandas) - 4 (1) | 2024.05.28 |
| [파이썬] 판다스 (Pandas) - 2 (0) | 2024.05.25 |
| [파이썬] 판다스 (Pandas) - 1 (0) | 2024.05.25 |
| [파이썬] 넘파이(NumPy) - 3 (0) | 2024.05.25 |



