시작에 앞서
해당 내용은 '<파이썬 머신러닝 완벽 가이드> 권철민 지음. 위키북스' 를 토대로 작성되었습니다. 보다 자세한 내용은 해당 서적에 상세히 나와있으니 서적을 참고해 주시기 바랍니다.
네이버 도서
책으로 만나는 새로운 세상
search.shopping.naver.com
이전 내용
[파이썬] 판다스 (Pandas) - 1
시작에 앞서해당 내용은 ' 권철민 지음. 위키북스' 를 토대로 작성되었습니다. 보다 자세한 내용은 해당 서적을 참고해 주시기 바랍니다. 네이버 도서책으로 만나는 새로운 세상search.shopping.naver
puppy-foot-it.tistory.com
DataFrame과 리스트, 딕셔너리, 넘파이 ndarray 상호 변환
기본적으로 DataFrame은 파이썬의 리스트, 딕셔너리 그리고 넘파이 ndarray 등으로 변환될 수 있으며, 특히 사이킷런의 많은 API는 DataFrame을 인자로 입력받을 수 있으나 보통 넘파이 ndarray를 입력 인자로 사용하는 경우가 대부분이다.
따라서 DataFrame과 넘파이 ndarray 상호 간의 변환은 매우 빈번하게 발생한다.
[넘파이 ndarray, 리스트, 딕셔너리 → DataFrame]
DataFrame은 리스트와 넘파이 ndarray와 다르게 칼럼명을 가지고 있어 상대적으로 편하게 데이터 핸들링이 가능하다.
◆ 1차원 형태의 리스트와 넘파이 ndarray를 DataFrame으로 변환하기

◆ 2차원 형태의 데이터를 기반으로 DataFrame을 생성하기 (2행 3열 형태의 리스트와 ndarray를 기반으로 DataFrame을 생성하므로 칼럼명은 3개 필요)

◆ 딕셔너리를 DataFrame으로 변환하기 (딕셔너리의 키는 칼럼명으로, 딕셔너리의 값은 키에 해당하는 칼럼 데이터로 변환 > 키의 경우는 문자열, 값의 경우 리스트 (또는 ndarray) 형태로 딕셔너리를 구성)

[DataFrame → 넘파이 ndarray, 리스트, 딕셔너리]
◆ DataFrame 을 ndarray로 변환하기

◆ DataFrame을 리스트, 딕셔너리로 변환하기
(리스트 변환: values로 얻은 ndarray에 tolist( )로 호출)
(딕셔너리 변환: DataFrame 객체의 to_dict( ) 메서드를 호출, ※ 인자로 'list' 입력하게 되면 리스트형으로 반환)

DataFrame의 칼럼 데이터 세트 생성 & 수정
DataFrame 칼럼 데이터 세트 생성과 수정 역시 [ ] 연산자를 이용해 쉽게 할 수 있다.
◆ Titanic DataFrame의 새로운 칼럼 Age_0 추가 (값은 일괄적으로 0 할당)

◆ 기존 칼럼 Series의 데이터를 이용해 새로운 칼럼 Series 만들기
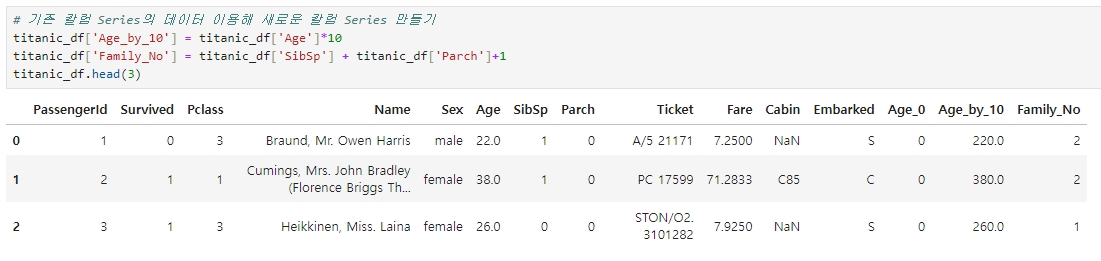
▶ 기존 칼럼 'Age'에 10을 곱한 'Age_by_10' 컬럼 생성
▶ 기존 칼럼 'SibSp' 와 'Parch' 을 더하고, 거기에 1을 더한 값인 'Family_No' 컬럼 생성
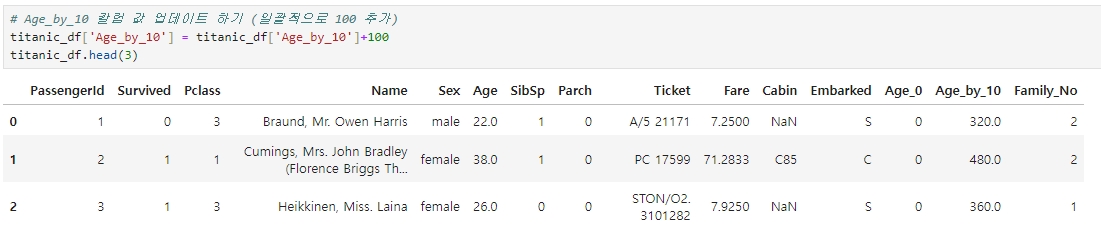
◆ 기존 칼럼 값 업데이트 하기
업데이트를 원하는 칼럼 Series를 DataFrame[ ] 내에 칼럼명으로 입력한 뒤 값을 할당해주면 된다.
DataFrame 삭제(feat. drop( ) 메서드)
★ drop ( ) 메서드의 원형
DataFrame.drop(labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors='raise')
[drop( ) 메서드에서 axis와 inplace 인자를 적용하여 DataFrame 변경하는 방법]
- axis 값에 따라 특정 칼럼 또는 특정 행 drop (axis 0은 로우 방향 축, axis 1은 칼럼 방향 축) axis=0 은 로우 방향을 드롭하겠다는 의미.
- labels에 원하는 칼럼명을 입력하고, axis=0 또는 1 을 입력하면 지정된 로우(또는 칼럼)을 드롭
- DataFrame에 특정 로우를 가리키는 것은 인덱스이며, 따라서 axis를 0으로 지정하면 DataFrame은 자동으로 labels에 오는 값을 인덱스로 간주
- inplace=False: inplace는 디폴트 값이 False 이므로 파라미터를 기재하지 않으면 자동으로 False가 된다. 또한, 이 경우 자기 자신의 DataFrame은 삭제하지 않으며, 삭제된 결과 DataFrame을 반환한다.▶ 즉, 원본 DataFrame은 유지하고 드롭된 DataFrame을 새롭게 객체 변수로 받고 싶다면 'inplace=False' 로 설정
- 원본 DataFrame에 드롭된 결과를 적용할 경우에는 'inplace=True'
- 원본 DataFrame에서 드롭된 DataFrame을 다시 원본 DataFrame 객체 변수로 할당하면 원본 DataFrame에서 드롭된 결과를 적용할 경우와 같음(단, 기존 원본 DataFrame 객체 변수는 메모리에서 추후 제거됨)
◆ 'Age_0' 칼럼 삭제하기
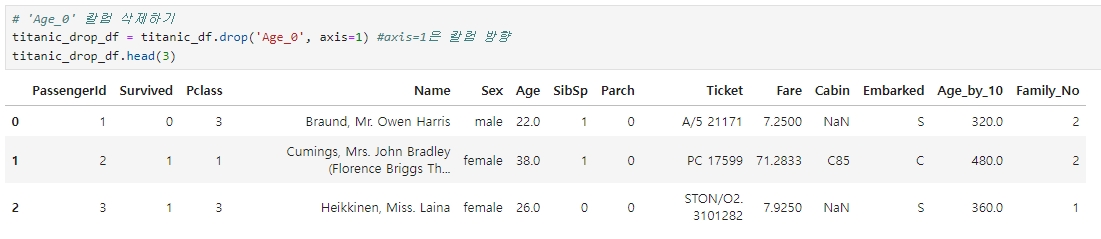
★ inplace=False/True

Titanic_drop_df에서 삭제됐던 'Age_0' 칼럼이 Titanic_df 에는 여전히 존재하는데, 이는 상단의 코드에서 'inplace=False'로 설정했기 때문이다. 만약 inplace=True 로 설정하면 자신의 DataFrame의 데이터를 삭제한다.
◆ 'lables'로 여러 개의 칼럼 삭제하기
또한 여러 개의 칼럼을 삭제하고 싶으면 리스트 형태로 삭제하고자 하는 칼럼명을 입력해 labels 파라미터로 입력하면 된다.
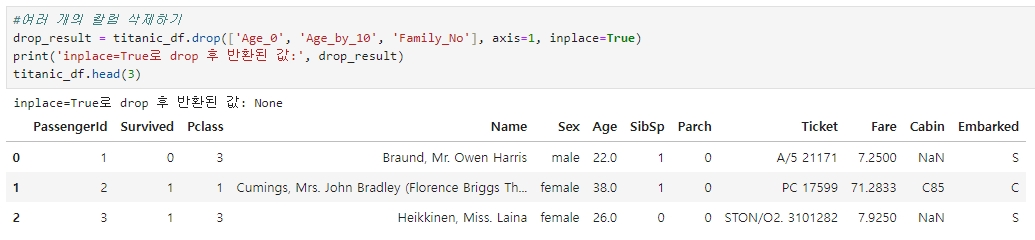
※ drop( ) 시 inplace=True 로 설정하면 반환 값이 None (아무 값도 아님) 이 된다. 따라서 다음 코드와 같이 inplace=True로 설정한 채로 반환 값을 다시 자신의 DataFrame에 객체로 할당하면 안 된다.
◆ 로우 삭제하기 (axis=0)
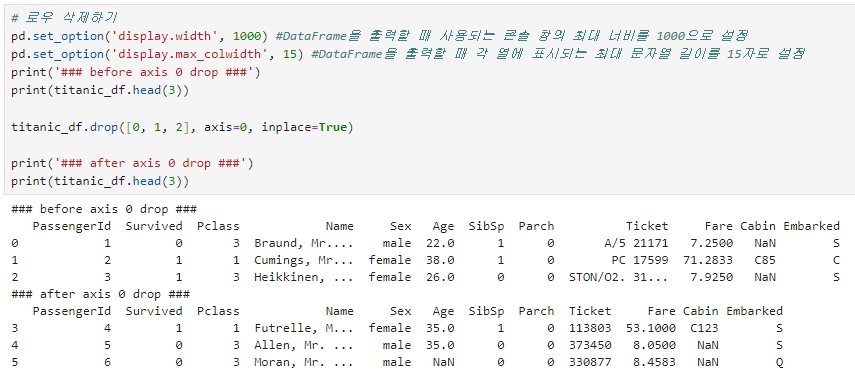
Index 객체
판다스의 Index 객체는 RDBMS의 PK와 유사하게 DataFrame, Series의 레코드를 고유하게 식별하는 객체이다.
DataFrame, Series에서 Index 객체만 추출하려면 .index 속성을 통해 가능.
※ 해당 코드 실행 전에, 원본 csv 데이터를 불러온 뒤 작업해야 한다.
(앞서 drop 메서드 파트에서 로우 세 개를 드롭하였기 때문에)
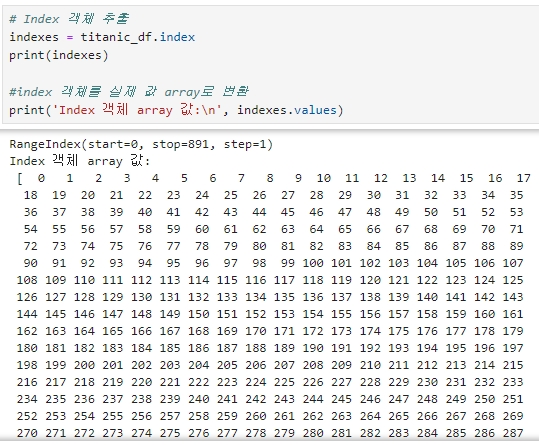
◆ Index 객체는 ndarray와 유사하게 단일 값 반환 및 슬라이싱도 가능하다

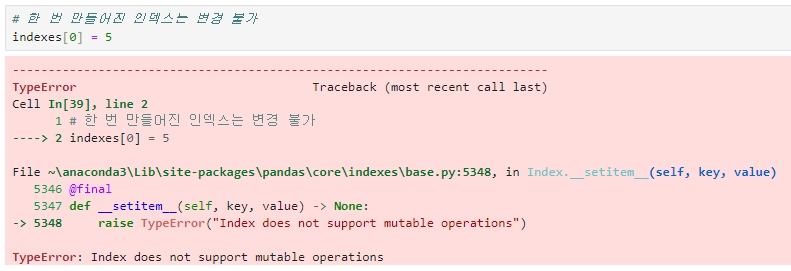
※ 한 번 만들어진 DataFrame 및 Series의 Index 객체는 함부로 변경할 수 없다.
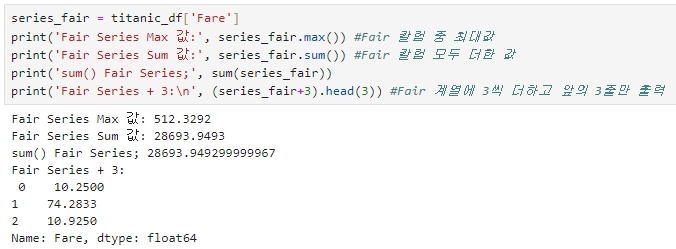
◆ Series 객체 연산
Series 객체는 Index 객체를 포함하지만 Series 객체에 연산 함수를 적용할 때 Index는 연산에서 제외된다.
(Index는 오직 식별용으로만 사용)
◆ reset_index( ) 메서드
DataFrame 및 Series에 reset_index( ) 메서드를 수헹하면 새롭게 인덱스를 연속 숫자 형으로 할당하며 기존 인덱스는 'index'라는 새로운 칼럼명으로 추가 된다.
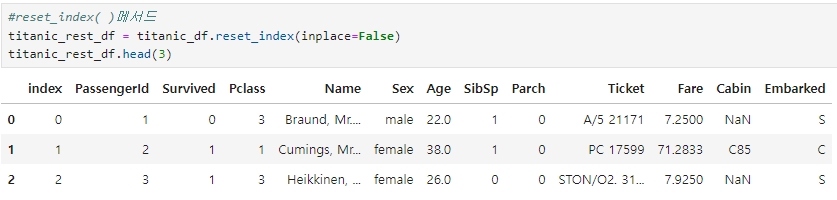
reset_index( )는 인덱스가 연속된 int 숫자형 데이터가 아닐 경우에 다시 이를 연속 int 숫자형 데이터로 만들 때 주로 사용한다.
Series에 reset_index( )를 적용하면 Series가 아닌 DataFrame이 반환된다. (기존 인덱스가 칼럼으로 추가돼 칼럼이 2개가 되므로)
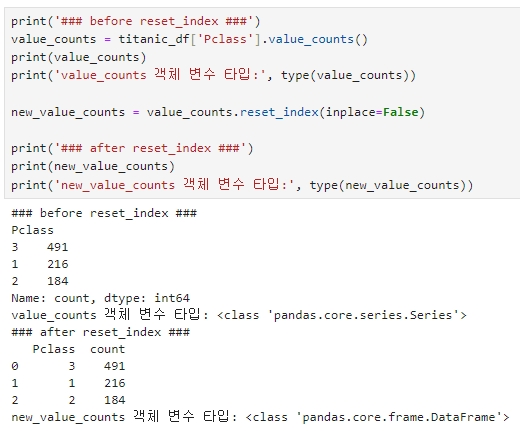
※ reset_index( )의 parameter 중 drop=True로 설정하면 기존 인덱스는 새로운 칼럼으로 추가되지 않고 삭제(Drop) 된다.
다음글
'[파이썬 Projects] > <파이썬 기초>' 카테고리의 다른 글
| [파이썬] 판다스 (Pandas) - 4 (1) | 2024.05.28 |
|---|---|
| [파이썬] 판다스 (Pandas) - 3 (0) | 2024.05.27 |
| [파이썬] 판다스 (Pandas) - 1 (0) | 2024.05.25 |
| [파이썬] 넘파이(NumPy) - 3 (0) | 2024.05.25 |
| [파이썬] 넘파이(NumPy) - 2 (0) | 2024.05.25 |



