프로젝트 수행 내용 및 목표
웹스크래핑으로 이태원과 한남동에 위치한 맛집 리스트를 받아와 데이터 전처리를 수행하여 DataFrame 으로 만들고,
지도 정보를 받아 folium을 통해 시각화 하는 것을 목표로 한다.
맛집 리스트는 '디너의 여왕' 사이트에서 가져오도록 한다.
이전 내용
[파이썬] 웹 스크래핑: 한남동, 이태원 맛집 분석 - 1
프로젝트 수행 내용 및 목표 웹스크래핑으로 이태원과 한남동에 위치한 맛집 리스트를 받아와 DataFrame 으로 만들고, 지도 정보를 받아 folium을 통해 시각화 하는 것을 목표로 한다. 맛집 리스트는
puppy-foot-it.tistory.com
csv 파일 불러오기
지난 시간에 저장했던 csv 파일을 불러오고, 필요한 모듈들을 import
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
from bs4 import BeautifulSoup
import pandas as pd# CSV 불러오기
df = pd.read_csv('C:/Users/niceq/Documents/DataScience/Practice/Source_code/Yongsan_Res_list.csv', sep=',',
encoding='UTF-8')
df.head()
순위(rank)와 가게명(name) 분리하기
불러온 파일을 보면, 몇가지 수정 및 보완해야 할 점들이 보인다.
첫 번째로 'Unnamed: 0' 컬럼을 삭제해주고,
두 번째로 'Rank_Name' 컬럼을 분리한 뒤,
마지막으로 'Rank' 컬럼을 index로 지정하는 작업을 해야 할 거 같다.
['Unnamed: 0' 컬럼 삭제]
# unnamed 칼럼 삭제하기
df_edit1 = df.drop(['Unnamed: 0'], axis=1)
df_edit1.head()
[Rank_Name 컬럼 분리]
# Rank, Name 분리하기
df_edit1[['Rank', 'Name']] = df_edit1['Rank_Name'].str.extract(r'(\d+)\.\s*(.*)')
df_edit1.head()
[컬럼 순서 변경]
# 컬럼 순서 바꾸기
df_edit1 = df_edit1[['Rank', 'Name', 'Add', 'Review', 'Hashtag']]
df_edit1
[Rank 컬럼을 Index로 지정]
# Rank 컬럼을 Index로 지정
df_edit1.set_index('Rank', inplace=True)
df_edit1.head()
해당 결과를 다시 csv로 저장
# csv 저장
df_edit1.to_csv('C:/Users/niceq/Documents/DataScience/Practice/Source_code/Yongsan_Res_list1.csv', sep=',',
encoding='UTF-8')불필요한 가게 삭제하기
데이터가 정리된 df_edit1 변수를 불러오면
df_edit1
상단의 가게들은 상세 주소가 잘 나와 있는데, 하단의 주소는 '서울 용산구 한남동' 또는 '서울 용산구 이태원동' 처럼 상세 주소가 없다. 따라서 해당 가게 정보는 허위일 가능성이 높으므로, 해당 가게 정보를 삭제하는 작업을 한다.
# 허위 가게 리스트 정리하기
df_edit1 = df_edit1[df_edit1.Add != '서울 용산구 이태원동']
df_edit1
▶ 기존의 2,452 행에서 1,979행으로 줄어들기는 하나,
이보다는 뒤에 상세 주소가 없이 '~동' 또는 '~로' 로 끝나는 행을 모두 삭제하는 방법이 더 효율적이라고 보여 코드를 다시 작성했다.
# 허위 가게 리스트 정리하기
# 주소가 '동', '로', '가', '구'로 끝나는 행을 제외
df_edit1 = df_edit1[~df_edit1['Add'].str.strip().str.endswith(('동', '로', '가', '구'))]
# 결과 출력
df_edit1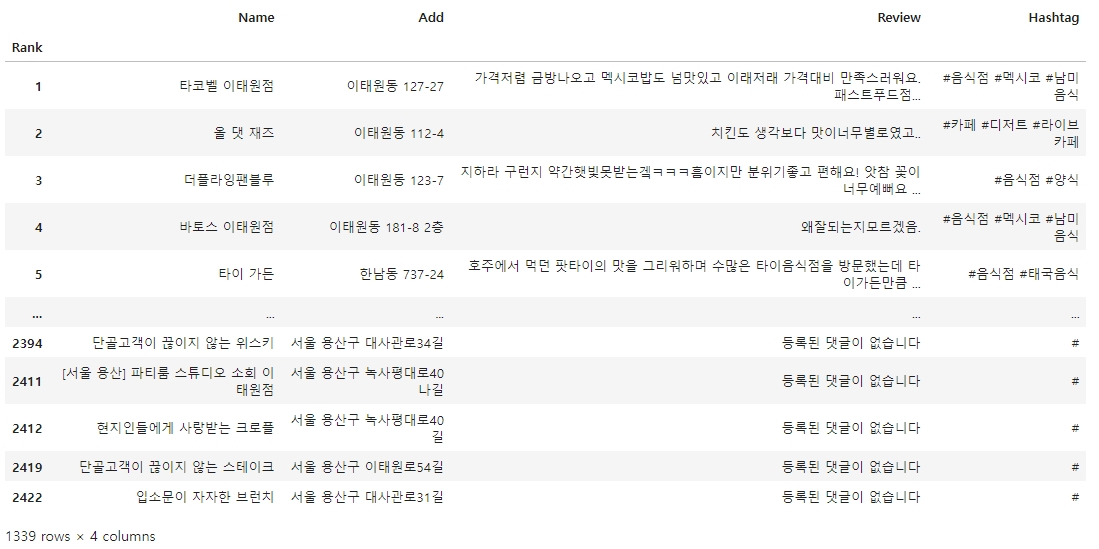
▶ 기존 코드에서 600여 개의 행이 삭제되었다.
최종 파일을 csv 파일로 저장
csv 파일
다음글
[파이썬] 자연어처리(NLP): 한남동, 이태원 맛집 분석 - 3
프로젝트 수행 내용 및 목표 웹스크래핑으로 이태원과 한남동에 위치한 맛집 리스트를 받아와 DataFrame 으로 만들고, 그 중 'Hashtag' 컬럼 내용을 텍스트 파일로 저장하여 불용어 처리 등의 자연
puppy-foot-it.tistory.com
'[파이썬 Projects] > <파이썬 데이터 분석>' 카테고리의 다른 글
| [파이썬] 지도시각화: 한남동, 이태원 맛집 분석 - 4 (1) | 2024.06.26 |
|---|---|
| [파이썬] 자연어처리(NLP): 한남동, 이태원 맛집 분석 - 3 (6) | 2024.06.25 |
| [파이썬] 웹 스크래핑: 한남동, 이태원 맛집 분석 - 1 (1) | 2024.06.24 |
| [파이썬] 웹 스크래핑: 한남동, 이태원 맛집 분석(실패) (0) | 2024.06.24 |
| [파이썬] 자연어 처리 (NLP) - 네이버 뉴스 텍스트 분석 (0) | 2024.05.16 |



