프로젝트 수행 내용 및 목표
웹스크래핑으로 이태원과 한남동에 위치한 맛집 리스트를 받아와 DataFrame 으로 만들고,
그 중 'Hashtag' 컬럼 내용을 텍스트 파일로 저장하여 불용어 처리 등의 자연어 처리 작업을 거쳐
워드 클라우드를 통해 해당 지역 맛집의 특징을 전달한다.
지도 정보를 받아 folium을 통해 시각화 하는 것을 목표로 한다.
맛집 리스트는 '디너의 여왕' 사이트에서 가져오도록 한다.
이전 내용
[파이썬] 데이터분석: 한남동, 이태원 맛집 분석 - 2
프로젝트 수행 내용 및 목표 웹스크래핑으로 이태원과 한남동에 위치한 맛집 리스트를 받아와 DataFrame 으로 만들고,지도 정보를 받아 folium을 통해 시각화 하는 것을 목표로 한다. 맛집 리스트
puppy-foot-it.tistory.com
DataFrame에서 'Hashtag' 컬럼 내용 텍스트 파일로 저장하기
먼저 csv 파일을 부르되, 'Hashtag' 컬럼만 불러오도록 한다.
# hashtag 컬럼만 가져오기
df_tag = pd.read_csv('C:/Users/niceq/Documents/DataScience/Practice/Source_code/Yongsan_Res_list1.csv',
header=0,
usecols=["Hashtag"])
print(df_tag)
[텍스트 파일 저장하기]
# 텍스트 파일로 저장하기
df_tag.to_csv('hashtag.txt', sep='\t')
▶ 해시태그 내용들이 텍스트 파일로 잘 저장되었다.
해시태그 자연어 처리하기
# 해시태그 한글 자연어 처리하기
import nltk
from konlpy.tag import Okt; o = Okt()
텍스트 파일을 불러와 토큰화를 시켜준다. (토큰화 전에 '#'을 삭제한다.)
# 텍스트 파일 불러오기
f = open("C:/Users/niceq/Documents/DataScience/Practice/Source_code/hashtag.txt", 'r', encoding='utf-8')
data = f.read()
print(data)
f.close()data = str(data.replace('#',''))
data
# 토큰화
tokens_ko = o.morphs(data)
tokens_ko
총 단어수와 중복을 제외한 단어수를 조회
# 총 단어수와 중복을 제외한 단어수를 조회
ko = nltk.Text(tokens_ko, name='이태원')
print(len(ko.tokens))
print(len(set(ko.tokens)))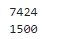
빈도수 확인
그리고 자연어 처리 (NLP)를 사용하여 텍스트 데이터에서 가장 자주 등장하는 단어들을 추출해보면
ko = nltk.Text(tokens_ko, name='이태원')
ko.vocab().most_common(300)
불용어 처리 후 빈도수 그래프 그리기
# 불용어처리(여러 번 수행)
stop_words = [',','#','\t','\n',]
#용어가 제거된 텍스트를 기반으로 nltk 라이브러리의 Text 객체를 생성
tokens_ko = [each_word for each_word in tokens_ko if each_word not in stop_words]
ko = nltk.Text(tokens_ko, name='이태원')
ko.vocab().most_common(50)
빈도수 그래프와 워드 클라우드를 그리기 위한 모듈을 import 하고 (한글 문제도 해결)
# 그래프 그리기, 워드 클라우드 위한 모듈 import
from bs4 import BeautifulSoup
from wordcloud import WordCloud
from konlpy.tag import Okt
import numpy as np
import pandas as pd
import platform
import matplotlib.pyplot as plt
%matplotlib inline
# wordcloud 라이브러리에서 WordCloud 클래스와 STOPWORDS 세트가져오기
from wordcloud import WordCloud, STOPWORDS
# Python 이미징 라이브러리(PIL) 가져오기
from PIL import Image
#한글 폰트 문제 해결
path = "c:/Windows/Fonts/malgun.ttf"
from matplotlib import font_manager, rc
if platform.system() == 'Windows':
font_name = font_manager.FontProperties(fname=path).get_name()
rc('font', family=font_name)
else:
print('Sorry')
빈도수 그래프 그리기 위한 코드를 입력하면
# 빈도수 그래프 그리기
plt.figure(figsize=(15,6))
ko.plot(50)
plt.show()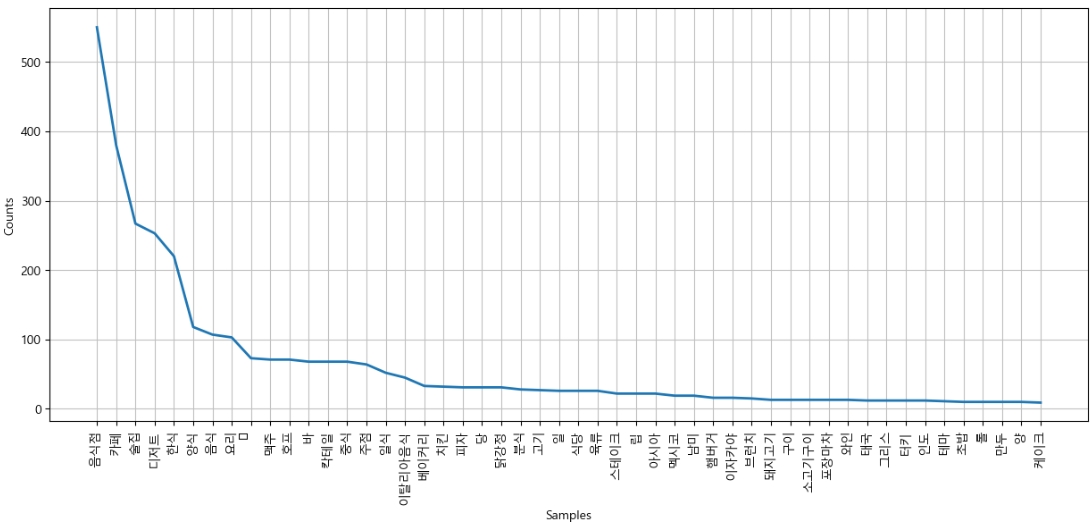
워드 클라우드 생성
워드 클라우드를 생성하기 위한 코드를 입력하면
# 워드 클라우드
# 데이터 준비
data = ko.vocab().most_common(300)
# 워드클라우드 객체 생성 (폰트 지정)
wordcloud = WordCloud(font_path="c:/Windows/Fonts/malgun.ttf",
relative_scaling=0.5, # 상대적인 크기 조정값 설정
background_color='white', # 배경은 흰색
width=800, height=400 # 이미지의 가로와 세로 크기 설정
)
# 텍스트 생성
text = "\n".join([f"{word}: {freq}" for word, freq in data])
# 워드클라우드 생성
wordcloud.generate(text)
# 이미지 출력
plt.figure(figsize=(16, 8))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()
▶ 이태원, 한남동 맛집 중 상당수가 술집, 카페 임을 알 수 있다.
다음글
[파이썬] 지도시각화: 한남동, 이태원 맛집 분석 - 4
프로젝트 수행 내용 및 목표 웹스크래핑으로 이태원과 한남동에 위치한 맛집 리스트를 받아와 DataFrame 으로 만들고, 그 중 'Hashtag' 컬럼 내용을 텍스트 파일로 저장하여 불용어 처리 등의 자연
puppy-foot-it.tistory.com
'[파이썬 Projects] > <파이썬 데이터 분석>' 카테고리의 다른 글
| [파이썬] 네이버 뉴스 댓글 분석(feat.임영웅) - 1 (0) | 2024.06.28 |
|---|---|
| [파이썬] 지도시각화: 한남동, 이태원 맛집 분석 - 4 (1) | 2024.06.26 |
| [파이썬] 데이터 전처리: 한남동, 이태원 맛집 분석 - 2 (1) | 2024.06.25 |
| [파이썬] 웹 스크래핑: 한남동, 이태원 맛집 분석 - 1 (1) | 2024.06.24 |
| [파이썬] 웹 스크래핑: 한남동, 이태원 맛집 분석(실패) (0) | 2024.06.24 |



