수행 내용 및 목표
파이썬을 이용하여 네이버 뉴스의 댓글 작성자 데이터를 모아
1. 댓글을 분석하여 워드 클라우드를 생성
2. 작성자 중 한 명 (또는 그 이상)을 추첨하는 프로그램을 만든다.
뉴스 선정
뉴스는 현재 기준 네이버 뉴스 상 댓글이 가장 많은 뉴스(수집하는 데이터 - 댓글 가 많을수록 유용하므로) 중 아무거나 하나를 고른다. (특정 단체, 정치 색 등과 아무 관련이 없음을 말씀 드립니다.)

네이버 뉴스 - 랭킹 - 댓글 많은 뉴스 중 정치색이 담겨있지 않고, 최대한 자극적이지 않은 기사를 선정하도록 한다.
그렇게 선정된 기사
임영웅, 차승원·유해진과 '삼시세끼' 짓는다.. 나영석이 꾸린 '깜짝 밥상'
가수 임영웅이 올 하반기 방송 예정인 tvN 새 예능프로그램 '삼시세끼' 새 시즌에 출연한다. 지난해 홀로 KBS '마이 리틀 히어로'에 출연한 적은 있지만, 임영웅이 여러 연예인과 함께 리얼 버라이
n.news.naver.com
▶ 차세대 가왕으로 떠오른 가수 임영웅님 관련 기사이다.
분석 수행
댓글이라는 자연어를 처리하는 프로젝트이니, 댓글을 모아서 빈도수 분석을 하고, 워드 클라우드로 시각화 하는 작업도 추가해보는 것이 좋을 거 같다.
먼저 jupyter notebook 을 켜고 관련 모듈, 라이브러리 등을 import 하여 초기 세팅을 한다.
해당 작업들은 기존에 진행했던 '파이썬 뉴스 분석' 프로젝트 + '한남동, 이태원 맛집' 프로젝트를 최대한 참고하여 진행한다.
[파이썬] 자연어 처리 (NLP) - 네이버 뉴스 텍스트 분석
분석 내용(목표) 를 통해 익혔던 텍스트 분석 방법을 활용하여네이버 뉴스에서 '파이썬' 이라는 키워드로 기사를 검색해서 빈도수를 분석하고,워드 클라우드를 생성, gensim 으로 유사도 파악 모
puppy-foot-it.tistory.com
[파이썬] 웹 스크래핑: 한남동, 이태원 맛집 분석 - 1
프로젝트 수행 내용 및 목표 웹스크래핑으로 이태원과 한남동에 위치한 맛집 리스트를 받아와 DataFrame 으로 만들고,지도 정보를 받아 folium을 통해 시각화 하는 것을 목표로 한다. 맛집 리스트
puppy-foot-it.tistory.com
1) 모듈, 라이브러리 등을 import 하여 초기 세팅
# from tqdm import tqdm_notebook 변경됨
from tqdm.notebook import tqdm
import urllib.request
import time
import requests
from bs4 import BeautifulSoup
from wordcloud import WordCloud
from konlpy.tag import Okt
import numpy as np
import pandas as pd
import platform
import matplotlib.pyplot as plt
%matplotlib inline
# wordcloud 라이브러리에서 WordCloud 클래스와 STOPWORDS 세트가져오기
from wordcloud import WordCloud, STOPWORDS
# Python 이미징 라이브러리(PIL) 가져오기
from PIL import Image
#한글 폰트 문제 해결
path = "c:/Windows/Fonts/malgun.ttf"
from matplotlib import font_manager, rc
if platform.system() == 'Windows':
font_name = font_manager.FontProperties(fname=path).get_name()
rc('font', family=font_name)
else:
print('Sorry')
# 마이너스 기호가 깨지는 문제를 해결
plt.rcParams['axes.unicode_minus'] = False
# 상태 진행 바 설치
!pip show ipywidgets
!pip install ipywidgets --upgrade
2) 뉴스 댓글을 크롤링할 코드 입력 (article_replies_text 변수에 저장)
from selenium import webdriver
from selenium.webdriver.common.by import By
import pandas as pd
import time
from bs4 import BeautifulSoup
# 웹 드라이버 경로 설정
driver = webdriver.Chrome()
# 크롤링할 네이버 뉴스 기사 URL
url = "https://n.news.naver.com/article/comment/469/0000809305"
driver.get(url)
# 페이지 로딩 대기
time.sleep(1)
# BeautifulSoup 라이브러리를 사용하여 HTML 파싱을 수행
soup = BeautifulSoup(driver.page_source, 'html.parser')
# 댓글 작성자와 내용 크롤링
writers = []
comments = []
list_soup = soup.find_all('div', 'u_cbox_area')
for item in list_soup:
writer_tag = item.find(class_='u_cbox_nick')
comment_tag = item.find(class_='u_cbox_contents')
if writer_tag and comment_tag: # 요소가 존재하는 경우에만 처리
writer = writer_tag.get_text()
comment = comment_tag.get_text()
writers.append(writer)
comments.append(comment)
# DataFrame으로 변환 및 저장
df = pd.DataFrame({'작성자': writers, '내용': comments})
df.to_csv('comments.csv', index=False)
driver.quit()
▶ 작성자와 댓글이 잘 불러와지는 것을 알 수 있다.
작성자와 댓글이 DataFrame으로 잘 저장된 것도 확인할 수 있다.

댓글 '더보기' 기능 추가 구현
하지만, 중요한 문제를 발견했다.

현재 댓글은 67개가 달려있는데, 스크래핑한 댓글은
len(writers), len(comments)
19개 밖에 안 된다.. 이는 댓글의 '더보기' 버튼을 눌러야 다음 댓글들이 나타나고, 해당 댓글 데이터를 가져올 수 있기 때문이다.

따라서, 더보기 버튼을 클릭하고 나타나는 댓글들도 다 수집할 수 있는 기능을 추가해줘야 할 거 같다.
from selenium import webdriver
from selenium.webdriver.common.by import By
import pandas as pd
import time
from bs4 import BeautifulSoup
# 웹 드라이버 경로 설정
driver = webdriver.Chrome()
# 크롤링할 네이버 뉴스 기사 URL
url = "https://n.news.naver.com/article/comment/469/0000809305"
driver.get(url)
# 페이지 로딩 대기
time.sleep(3)
# BeautifulSoup 라이브러리를 사용하여 HTML 파싱을 수행
soup = BeautifulSoup(driver.page_source, 'html.parser')
# 댓글 작성자와 내용 크롤링
writers = []
comments = []
list_soup = soup.find_all('div', 'u_cbox_area')
# 댓글 더보기 클릭 기능 추가
while True:
try:
more_comments = driver.find_element(By.CLASS_NAME,'u_cbox_page_more')
more_comments.click()
time.sleep(1)
for item in list_soup:
writer_tag = item.find(class_='u_cbox_nick')
comment_tag = item.find(class_='u_cbox_contents')
if writer_tag and comment_tag: # 요소가 존재하는 경우에만 처리
writer = writer_tag.get_text()
comment = comment_tag.get_text()
writers.append(writer)
comments.append(comment)
except:
for item in list_soup:
writer_tag = item.find(class_='u_cbox_nick')
comment_tag = item.find(class_='u_cbox_contents')
if writer_tag and comment_tag: # 요소가 존재하는 경우에만 처리
writer = writer_tag.get_text()
comment = comment_tag.get_text()
writers.append(writer)
comments.append(comment)
break
# DataFrame으로 변환 및 저장
df = pd.DataFrame({'작성자': writers, '내용': comments})
df.to_csv('comments.csv', index=False)
driver.quit()len(writers), len(comments)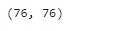
▶ 금세 댓글이 76개로 늘었다.
※ 만약 except: 에서 그냥 break 를 해버리면, 마지막 더보기를 한 뒤에 나오는 댓글은 수집이 안 된다.
(해당 내용을 생략하고 그냥 break만 넣어서 해봤더니 50여 개로 나와서 while문을 이리저리 수정해보고
별 짓을 다 하다가 갑자기 유레카! 하고 떠올라서 해보니 다행히도 전부 수집되었다.)
형태소 분석 및 토큰화
comments.csv 파일에서 '내용' 컬럼만 불러와서 텍스트 파일로 저장한다.
# comments.csv 파일에서 '내용' 컬럼만 불러와서 텍스트 파일로 저장
# 내용 컬럼만 가져오기
df = pd.read_csv('C:/Users/niceq/Documents/DataScience/Practice/Source_code/comments.csv',
header=0, usecols=["내용"])
# 텍스트 파일로 저장하기
df.to_csv('comments.txt', sep='\t')
그리고나서 필요한 모듈을 import 하고
# 댓글 한글 자연어 처리하기
import nltk
from konlpy.tag import Okt; o = Okt()
텍스트 파일을 불러와 토큰화를 시켜준다. (토큰화 전에 '#'을 삭제한다.)
# 텍스트 파일 불러오기
f = open("C:/Users/niceq/Documents/DataScience/Practice/Source_code/comments.txt", 'r', encoding='utf-8')
data = f.read()
print(data)
f.close()
▶ 여러분 댓글은 이렇게 쉽게 수집됩니다. 그러니 악플은 남기지 마세요...
불러온 텍스트를 토큰화 작업을 하고,
# 토큰화
tokens_ko = o.morphs(data)
tokens_ko
총 단어수와 중복을 제외한 단어수를 조회
# 총 단어수와 중복을 제외한 단어수를 조회
ko = nltk.Text(tokens_ko, name='임영웅')
print(len(ko.tokens))
print(len(set(ko.tokens)))
빈도수 확인
그리고 자연어 처리 (NLP)를 사용하여 텍스트 데이터에서 가장 자주 등장하는 단어들을 추출해보면
ko = nltk.Text(tokens_ko, name='임영웅')
ko.vocab().most_common(250)
▶ 불용어 처리가 필요해 보인다.
불용어 처리 후 빈도수 그래프 그리기
# 불용어처리(여러 번 수행)
stop_words = [',','#','\t','\n','"','의','도','삼','시세','끼','는','이','을','넘','에서','언제','!','과','ㅋㅋ','많이','...','가',
'..','.','요','됩니다','?','기','부터','하는지','싶네요','대에','들','준다거나','부른다고','진',',,','까지','한','!!!!','!!']
#용어가 제거된 텍스트를 기반으로 nltk 라이브러리의 Text 객체를 생성
tokens_ko = [each_word for each_word in tokens_ko if each_word not in stop_words]
ko = nltk.Text(tokens_ko, name='임영웅')
ko.vocab().most_common(50)# 빈도수 그래프 그리기
plt.figure(figsize=(15,6))
ko.plot(50)
plt.show()
워드 클라우드 생성
# 워드 클라우드
# 데이터 준비
data = ko.vocab().most_common(100)
# 워드클라우드 객체 생성 (폰트 지정)
wordcloud = WordCloud(font_path="c:/Windows/Fonts/malgun.ttf",
relative_scaling=0.5,
background_color='white',
width=800, height=400
)
# 텍스트 생성
text = "\n".join([f"{word}: {freq}" for word, freq in data])
# 워드클라우드 생성
wordcloud.generate(text)
# 이미지 출력
plt.figure(figsize=(16, 8))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()
▶ 댓글 수가 많지 않아서 예전의 워드클라우드 작업에 비해 조금 빈약한 편이긴 하나, 그래도 성공.
다음에는 댓글 추첨 프로그램을 생성하여 가상의 댓글 추첨 이벤트를 진행해 보겠다.
다음 글
[파이썬] 네이버 뉴스 댓글 추첨 (feat.임영웅) - 2
수행 내용 및 목표 파이썬을 이용하여 네이버 뉴스의 댓글 작성자 데이터를 모아1. 댓글을 분석하여 워드 클라우드를 생성2. 작성자 중 한 명 (또는 그 이상)을 추첨하는 프로그램을 만든다. 이
puppy-foot-it.tistory.com
'[파이썬 Projects] > <파이썬 데이터 분석>' 카테고리의 다른 글
| [워드클라우드] 코로나 뉴스 기사 (feat.주사기 마스킹) (2) | 2024.08.19 |
|---|---|
| [파이썬] 네이버 뉴스 댓글 추첨 (feat.임영웅) - 2 (0) | 2024.06.29 |
| [파이썬] 지도시각화: 한남동, 이태원 맛집 분석 - 4 (1) | 2024.06.26 |
| [파이썬] 자연어처리(NLP): 한남동, 이태원 맛집 분석 - 3 (6) | 2024.06.25 |
| [파이썬] 데이터 전처리: 한남동, 이태원 맛집 분석 - 2 (1) | 2024.06.25 |



