프로젝트 수행 내용 및 목표
웹스크래핑으로 이태원과 한남동에 위치한 맛집 리스트를 받아와 DataFrame 으로 만들고,
지도 정보를 받아 folium을 통해 시각화 하는 것을 목표로 한다.
맛집 리스트는 '디너의 여왕' 사이트에서 가져오도록 한다.
'디너의 여왕' 사이트에서 맛집 리스트 얻기
https://dinnerqueen.net/restaurant/area/4.
디너의여왕 - 이태원&한남동 맛집랭킹
오늘 뭐 먹을지 고민된다면, 디너의여왕만의 빅데이터 맛집 랭킹을 찾아주세요.
dinnerqueen.net
리스트로 저장된 맛집 리스트 문자열로 바꾸기 (실패)
다른 방식으로의 접근
위의 과정을 거쳐 texts라는 변수에 식당 이름, 주소, 리뷰 등의 정보가 잘 저장되었으나,
문제는 해당 값이 리스트 형으로 저장되어 있어 분할을 해줘야 한다는 문제가 있다.
따라서, 해당 코드 실행 후 데이터를 저장할 때 리스트가 아닌 문자열로 저장할 수 있게 코드를 수정 및 보완해야 할 거 같다.
기존에 했던 작업에서는 해당 정보를 텍스트 파일 형태로 저장하였으나,
여러 줄로 되어있는 식당 정보들을 각 식당 당 한 줄에 다 나오게끔 만들어 csv 파일로 저장하려는 작업을 수행하려고 했으나, 십여 번 (혹은 몇 십번)의 코드 수정을 통해서도 해결하지 못했다.
[파이썬] 웹 스크래핑: 한남동, 이태원 맛집 분석(실패)
프로젝트 수행 내용 및 목표 웹스크래핑으로 이태원과 한남동에 위치한 맛집 리스트를 받아와 DataFrame 으로 만들고,지도 정보를 받아 folium을 통해 시각화 하는 것을 목표로 한다. 맛집 리스트
puppy-foot-it.tistory.com
그래서 예전에 공부했던 <파이썬으로 데이터 주무르기> 의 책을 찾아봤고,
그 중에 힌트가 될 만한 방법을 찾아 진행했고, 각 요소별 리스트를 저장하는데 성공했다.
그 코드는
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
from bs4 import BeautifulSoup
driver = webdriver.Chrome()
try:
# 웹사이트 열기
driver.get('https://dinnerqueen.net/restaurant/area/4')
# 페이지 하단까지 스크롤 내리기
def scroll_to_bottom():
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
# 스크롤 아래로 내리기
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# 새로운 콘텐츠 로딩 대기
time.sleep(1)
# 새로운 스크롤 길이 계산하고 앞의 스크롤 길이와 비교하기
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
break
last_height = new_height
# 스크롤 내리기 함수 호출
scroll_to_bottom()
# BeautifulSoup 라이브러리를 사용하여 HTML 파싱을 수행
soup = BeautifulSoup(driver.page_source, 'html.parser')
# 필요한 작업 수행
# 돌면서 식당 리스트 가져오기
# dq-area-card__text 클래스의 값을 저장하기
rank_name = []
add = []
review = []
hashtag = []
list_soup = soup.find_all('div', 'dq-area-card__text')
for item in list_soup:
rank_name.append(item.find(class_='dq-area-card__text__title').get_text())
add.append(item.find(class_='dq-area-card__text__area').get_text())
review.append(item.find(class_='dq-area-card__text__script').get_text())
hashtag.append(item.find(class_='dq-area-card__text__hashtag').get_text())
finally:
# 브라우저 닫기
driver.quit()▶ 코드에 대한 설명은 우선 스크롤 내리기 함수를 적용하는 거 까지는 전과 동일하나,
그 후에 BeautifulSoup 라이브러리를 사용하여 HTML 파싱을 수행하고,
for 반복문을 이용하여 각 항목별로 리스트를 저장하였다.
개발자도구를 통해 보면 dq-area-card__text 라는 기본 클래스에

▶ 가게명은 _title / 주소는 __area / 리뷰는 __script / 태그는 __hashtag 의 클래스가 붙어있는 것을 볼 수 있다.
이를 힌트로 얻어서 반복문을 통해 각각의 정보를 .append 명령으로 빈 리스트에 수행하도록 했다.
그 결과로 각 요소들은 아래와 같은 변수에 저장되었고,
- 순위와 가게명: rank_name
- 주소: add
- 리뷰: review
- 태그: hashtag
이를 조회해보면

잘 구분되어 나오는 것을 알 수 있다.
len(rank_name), len(add), len(review), len(hashtag)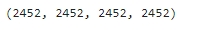
네 개 변수의 길이도 동일한 것을 보니 잘 저장된 거 같다.
판다스를 통해 DataFrame으로 만들기
# 판다스로 DF 만들기
import pandas as pd
data = {'Rank_Name':rank_name, 'Add':add, 'Review':review, 'Hashtag':hashtag}
df = pd.DataFrame(data)
df.head()
CSV 로 파일 저장하기
추가적인 분석 전에 파일을 저장하도록 한다.
# CSV 저장하기
df.to_csv('C:/Users/niceq/Documents/DataScience/Practice/Source_code/Yongsan_Res_list.csv', sep=',',
encoding='UTF-8')
파일이 잘 저장되었다.
다음 내용
[파이썬] 데이터분석: 한남동, 이태원 맛집 분석 - 2
프로젝트 수행 내용 및 목표 웹스크래핑으로 이태원과 한남동에 위치한 맛집 리스트를 받아와 DataFrame 으로 만들고,지도 정보를 받아 folium을 통해 시각화 하는 것을 목표로 한다. 맛집 리스트
puppy-foot-it.tistory.com
'[파이썬 Projects] > <파이썬 데이터 분석>' 카테고리의 다른 글
| [파이썬] 자연어처리(NLP): 한남동, 이태원 맛집 분석 - 3 (6) | 2024.06.25 |
|---|---|
| [파이썬] 데이터 전처리: 한남동, 이태원 맛집 분석 - 2 (1) | 2024.06.25 |
| [파이썬] 웹 스크래핑: 한남동, 이태원 맛집 분석(실패) (0) | 2024.06.24 |
| [파이썬] 자연어 처리 (NLP) - 네이버 뉴스 텍스트 분석 (0) | 2024.05.16 |
| [파이썬] 자연어 처리(NLP) - 여자친구 선물 고르기 : 3(진행불가) (0) | 2024.05.15 |



