★ 시작에 앞서 ★
해당 내용은 '<현대통계학-제6판>, 다산출판사, 2024' 에 나와있는 챕터별 연습문제를 교재를 응용하여 풀이하고, 수학적인 문제에 대한 답변을 파이썬으로 구현해보기 위해 작성하는 글이다.
해당 답변을 구현하는 방식은 답안지 없이 필자가 스스로 구현하는 것이므로, 정확한 (혹은 가장 효과적인) 답변이 아닐 수 있다. 이 글의 목적은 통계학 공부와 파이썬 프로그래밍 언어 공부를 동시에 하고자 함이며, 통계학을 공부하고 싶으신 분들은 해당 교재를 구매하는 것을 추천한다.
또한, 연습문제 번호 및 문제 내용은 필자가 임의대로 작성하였으며, 교재와는 다를 수 있다.
이전 내용
[파이썬+통계학] 현대통계학 연습문제 파이썬 구현(ch.2) - 2
★ 시작에 앞서 ★ 해당 내용은 ', 다산출판사, 2024' 에 나와있는 챕터별 연습문제를 교재를 응용하여 풀이하고, 수학적인 문제에 대한 답변을 파이썬으로 구현해보기 위해 작성하는 글이다.해
puppy-foot-it.tistory.com
챕터2 주요 개념: 도수분포표, 상대빈도수, 누적 빈도, 누적백분율
챕터2 연습문제 5
Q. 금은방에서 새로 반입된 30개의 금반지 순도를 조사한 데이터를 이용하여
1) 등급의 수를 5개로 하고 아래의 데이터를 포함한 도수분포표를 작성하라
- 중간점
- 누적빈도
- 상대적 빈도
- 상대적 누적빈도
2) 해당 도수분포표를 이용하여 막대그래프와 꺾은선그래프를 그려라
3) 해당 도수분포표를 이용하여 누적백분율곡선을 그려라
◆ 도수분포표 생성하기
# 금은방 문제 (순도, 단위: %)
import pandas as pd
import numpy as np
gold = [99.55, 99.43, 99.60, 99.38, 99.57, 99.80, 99.61, 99.94,
99.79, 99.51, 99.29, 99.57, 99.83, 99.80, 99.53, 99.89,
99.84, 99.64, 99.68, 99.40, 99.49, 99.54, 99.99, 99.70,
99.68, 99.59, 99.73, 99.65, 99.71, 99.64]
# 데이터프레임 생성
df_6 = pd.DataFrame(gold)
# 등급의 수를 5개로 하여 나누기
bins = np.linspace(min(gold), max(gold), 6)
# 도수분포표 생성
freq, bin_edges = np.histogram(gold, bins=bins)
# 각 등급별 중간점 구하기
midpoints = (bin_edges[:-1] + bin_edges[1:]) / 2
# 누적 빈도 구하기
cumulative_freq = np.cumsum(freq)
# 상대적 빈도 구하기
relative_freq = freq / len(gold)
# 상대적 누적 빈도 구하기
relative_cumulative_freq = np.cumsum(relative_freq)
# 순도 데이터 프레임 생성하기
df_7 = pd.DataFrame({
'purity_grade': [f'{round(bin_edges[i], 2)} - {round(bin_edges[i+1], 2)}' for i in range(len(bin_edges)-1)],
'Midpoint': midpoints,
'Frequency': freq,
'Cumulative Frequency': cumulative_freq,
'Relative Frequency': relative_freq,
'Cumulative Relative Frequency': relative_cumulative_freq
})
# 합계 행 추가
total_row = pd.DataFrame({
'purity_grade': ['Total'],
'Midpoint': ['-'],
'Frequency': df_7['Frequency'].sum(),
'Cumulative Frequency': ['-'],
'Relative Frequency': df_7['Relative Frequency'].sum(),
'Cumulative Relative Frequency': ['-']
})
# 합계 행 빈도도수표에 붙여주기
df_8 = pd.concat([df_7, total_row], ignore_index=True)
# 표 출력하기
print(df_8)
★ 코드 설명 ★
1) Bins: 데이터를 5등급으로 구분.
np.linspace를 사용하여 데이터 범위 내에서 최소값과 최대값을 기준으로 5개의 구간을 만듦.
※ np.linspace(min(gold), max(gold), 6) 코드에서 5등급인데, 5가 아니라 6이 되는 이유
6 대신 5레벨을 얻는 이유는 결국 linspace 작동 방식에 달려 있다.
np.linspace(start, stop, num)은 start와 stop 사이에 균등한 간격의 숫자 num을 생성한다.
num=6을 사용하면 범위를 5개의 간격으로 나누지만 6 bin edge(각 간격의 경계)를 반환한다. 즉, 5개의 간격을 만들려면 6개의 경계가 필요하다.
각 간격은 두 개의 가장자리(시작에 하나, 끝에 하나)로 정의되기 때문이다. 첫 번째 숫자는 첫 번째 Bin의 시작을 나타내고, 마지막 숫자는 마지막 Bin의 끝을 나타낸다.
|---|---|---|---|---|0 1 2 3 4 5
이렇게 하면 5가지 간격이 제공된다.
1등급: 0~1
2등급: 1~2
3등급: 2~3
4등급: 3~4
5등급: 4~5
요약하자면, 'np.linspace'는 빈 자체가 아닌 빈 가장자리를 제공하므로 5개의 간격을 제공하려면 숫자 '6'이 필요하다.
2) midpoint(중간점): 빈 가장자리의 평균으로 계산.
구간의 경계값(bin_edges)을 이용해 각 구간의 중간값을 계산. ▶ (bin_edges[:-1] + bin_edges[1:]) / 2
3) Cumulative Frequency(누적 빈도): 빈도의 누적.
누적 빈도는 각 구간까지의 빈도를 차례로 더해 계산. ▶ np.cumsum(freq)
4) Relative Frequency(상대적 빈도): 각 등급별 발생 비율.
각 구간의 빈도를 전체 데이터 수로 나누어 상대적 빈도 계산. ▶ freq / len(gold)
5) Cumlative Relative Frequency(상대적 누적빈도): 상대도수의 누적합.
상대적 누적 빈도는 상대적 빈도를 차례로 더한 값. ▶ cumsum 을 사용하여 계산.
6) 도수분포표 생성
np.histogram을 사용하여 각 구간에 속하는 데이터의 빈도 수를 계산
freq는 각 구간에 해당하는 데이터의 빈도 수를 나타내고, bin_edges는 각 구간의 경계값.
◆ 도수분포표를 이용하여 막대그래프 그리기
# 막대그래프 그리기
import pandas as pd
import matplotlib.pyplot as plt
gold = [99.55, 99.43, 99.60, 99.38, 99.57, 99.80, 99.61, 99.94,
99.79, 99.51, 99.29, 99.57, 99.83, 99.80, 99.53, 99.89,
99.84, 99.64, 99.68, 99.40, 99.49, 99.54, 99.99, 99.70,
99.68, 99.59, 99.73, 99.65, 99.71, 99.64]
# 데이터프레임 생성
df_6 = pd.DataFrame(gold)
# 등급의 수를 5개로 하여 나누기
bins = np.linspace(min(gold), max(gold), 6)
# 도수분포표 생성
freq, bin_edges = np.histogram(gold, bins=bins)
# 각 등급별 중간점 구하기
midpoints = (bin_edges[:-1] + bin_edges[1:]) / 2
# 누적 빈도 구하기
cumulative_freq = np.cumsum(freq)
# 상대적 빈도 구하기
relative_freq = freq / len(gold)
# 상대적 누적 빈도 구하기
relative_cumulative_freq = np.cumsum(relative_freq)
# 순도 데이터 프레임 생성하기
df_7 = pd.DataFrame({
'purity_grade': [f'{round(bin_edges[i], 2)} - {round(bin_edges[i+1], 2)}' for i in range(len(bin_edges)-1)],
'Midpoint': midpoints,
'Frequency': freq,
'Cumulative Frequency': cumulative_freq,
'Relative Frequency': relative_freq,
'Cumulative Relative Frequency': relative_cumulative_freq
})
# 합계 행 추가
total_row = pd.DataFrame({
'purity_grade': ['Total'],
'Midpoint': ['-'],
'Frequency': df_7['Frequency'].sum(),
'Cumulative Frequency': ['-'],
'Relative Frequency': df_7['Relative Frequency'].sum(),
'Cumulative Relative Frequency': ['-']
})
# 합계 행 빈도도수표에 붙여주기
df_8 = pd.concat([df_7, total_row], ignore_index=True)
# 막대 그래프 그리기
plt.figure(figsize=(10, 6))
plt.bar(df_7['purity_grade'], df_7['Frequency'], color='red')
# 라벨과 제목 추가
plt.xlabel('Purity Grade')
plt.ylabel('Frequency')
plt.title('Frequency Distribution of Gold Purity')
# 더 나은 가독성을 위해 X 라벨을 회전시킴
plt.xticks(rotation=45)
# 차트 출력
plt.show()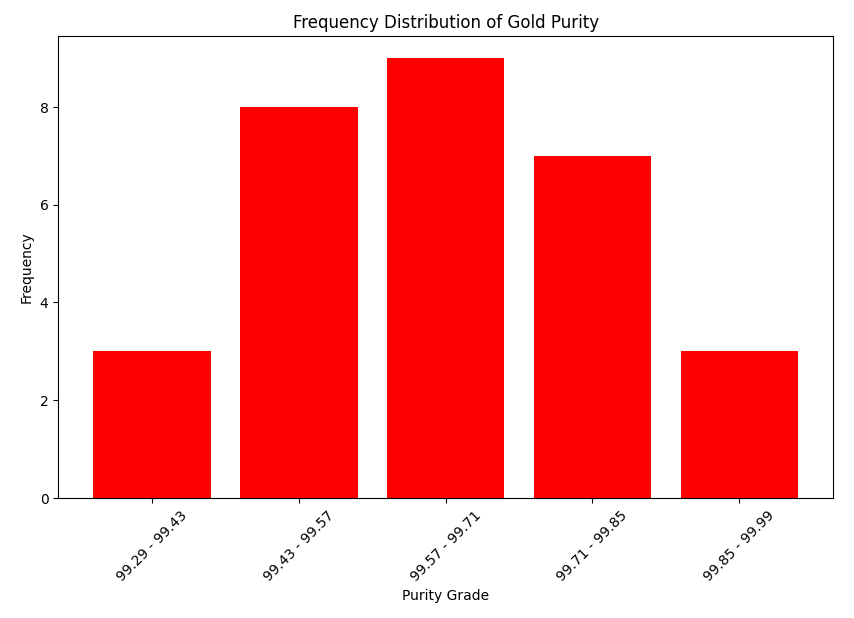
◆ 도수분포표를 이용하여 꺾은선그래프 그리기
# 꺾은선그래프 그리기
# 막대그래프 그리기
import pandas as pd
import matplotlib.pyplot as plt
gold = [99.55, 99.43, 99.60, 99.38, 99.57, 99.80, 99.61, 99.94,
99.79, 99.51, 99.29, 99.57, 99.83, 99.80, 99.53, 99.89,
99.84, 99.64, 99.68, 99.40, 99.49, 99.54, 99.99, 99.70,
99.68, 99.59, 99.73, 99.65, 99.71, 99.64]
# 데이터프레임 생성
df_6 = pd.DataFrame(gold)
# 등급의 수를 5개로 하여 나누기
bins = np.linspace(min(gold), max(gold), 6)
# 도수분포표 생성
freq, bin_edges = np.histogram(gold, bins=bins)
# 각 등급별 중간점 구하기
midpoints = (bin_edges[:-1] + bin_edges[1:]) / 2
# 누적 빈도 구하기
cumulative_freq = np.cumsum(freq)
# 상대적 빈도 구하기
relative_freq = freq / len(gold)
# 상대적 누적 빈도 구하기
relative_cumulative_freq = np.cumsum(relative_freq)
# 순도 데이터 프레임 생성하기
df_7 = pd.DataFrame({
'purity_grade': [f'{round(bin_edges[i], 2)} - {round(bin_edges[i+1], 2)}' for i in range(len(bin_edges)-1)],
'Midpoint': midpoints,
'Frequency': freq,
'Cumulative Frequency': cumulative_freq,
'Relative Frequency': relative_freq,
'Cumulative Relative Frequency': relative_cumulative_freq
})
# 합계 행 추가
total_row = pd.DataFrame({
'purity_grade': ['Total'],
'Midpoint': ['-'],
'Frequency': df_7['Frequency'].sum(),
'Cumulative Frequency': ['-'],
'Relative Frequency': df_7['Relative Frequency'].sum(),
'Cumulative Relative Frequency': ['-']
})
# 합계 행 빈도도수표에 붙여주기
df_8 = pd.concat([df_7, total_row], ignore_index=True)
# 꺾은선 그래프 그리기
plt.figure(figsize=(10, 6))
plt.plot(df_7['purity_grade'], df_7['Frequency'], marker='o', color='red')
# 라벨과 제목 추가
plt.xlabel('Purity Grade')
plt.ylabel('Frequency')
plt.title('Frequency Distribution of Gold Purity')
# 더 나은 가독성을 위해 X 라벨을 회전시킴
plt.xticks(rotation=45)
# 차트 출력
plt.show()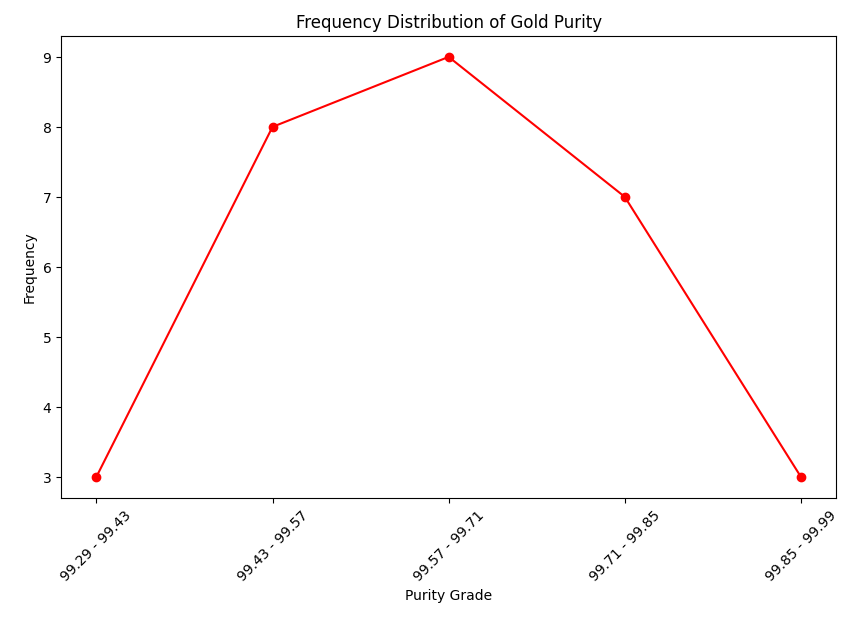
◆ 도수분포표를 이용하여 누적백분율곡선 그리기
# 누적백분율곡선 그리기
import pandas as pd
import matplotlib.pyplot as plt
gold = [99.55, 99.43, 99.60, 99.38, 99.57, 99.80, 99.61, 99.94,
99.79, 99.51, 99.29, 99.57, 99.83, 99.80, 99.53, 99.89,
99.84, 99.64, 99.68, 99.40, 99.49, 99.54, 99.99, 99.70,
99.68, 99.59, 99.73, 99.65, 99.71, 99.64]
# 데이터프레임 생성
df_6 = pd.DataFrame(gold)
# 등급의 수를 5개로 하여 나누기
bins = np.linspace(min(gold), max(gold), 6)
# 도수분포표 생성
freq, bin_edges = np.histogram(gold, bins=bins)
# 각 등급별 중간점 구하기
midpoints = (bin_edges[:-1] + bin_edges[1:]) / 2
# 누적 빈도 구하기
cumulative_freq = np.cumsum(freq)
# 상대적 빈도 구하기
relative_freq = freq / len(gold)
# 상대적 누적 빈도 구하기
relative_cumulative_freq = np.cumsum(relative_freq)
# 순도 데이터 프레임 생성하기
df_7 = pd.DataFrame({
'purity_grade': [f'{round(bin_edges[i], 2)} - {round(bin_edges[i+1], 2)}' for i in range(len(bin_edges)-1)],
'Midpoint': midpoints,
'Frequency': freq,
'Cumulative Frequency': cumulative_freq,
'Relative Frequency': relative_freq,
'Cumulative Relative Frequency': relative_cumulative_freq
})
# 합계 행 추가
total_row = pd.DataFrame({
'purity_grade': ['Total'],
'Midpoint': ['-'],
'Frequency': df_7['Frequency'].sum(),
'Cumulative Frequency': ['-'],
'Relative Frequency': df_7['Relative Frequency'].sum(),
'Cumulative Relative Frequency': ['-']
})
# 합계 행 빈도도수표에 붙여주기
df_8 = pd.concat([df_7, total_row], ignore_index=True)
# 누적백분율곡선 그리기
plt.figure(figsize=(10, 6))
# 누적 상대 빈도를 백분율로 변환
plt.plot(df_7['purity_grade'], df_7['Cumulative Relative Frequency'] * 100, marker='o')
plt.title('Cumulative Percentage Curve of Gold Purity')
plt.xlabel('purity_grade')
plt.ylabel('Cumulative Relative Frequency (%)')
plt.xticks(rotation=45)
plt.grid()
# 100% 선 추가 (1에 해당하는 위치로 변경)
plt.axhline(100, color='red', linestyle='--', label='100% Line')
plt.legend()
plt.tight_layout()
plt.show()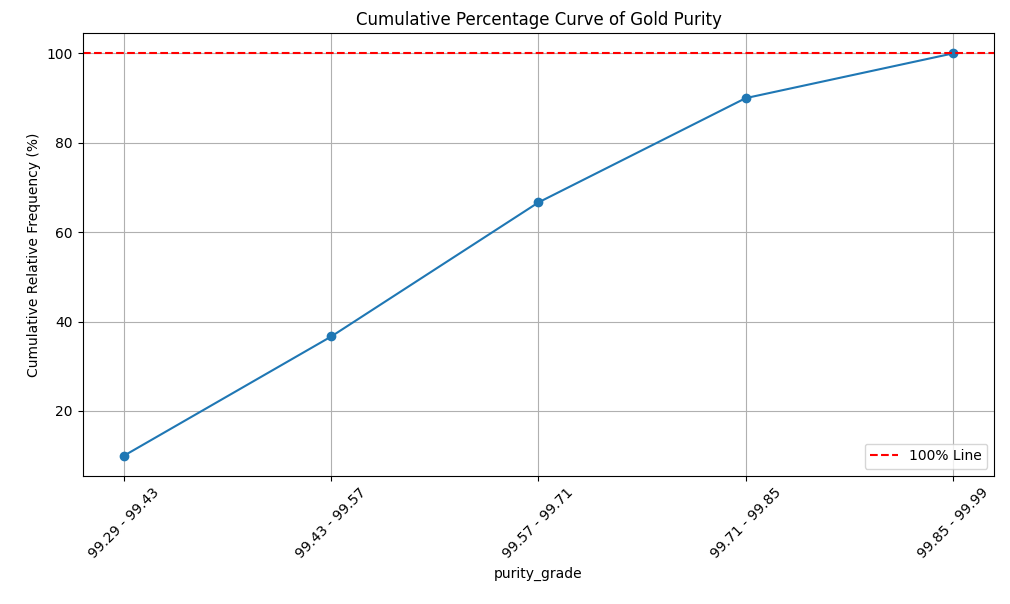
챕터2 연습문제 6
Q. 어느 도시의 5월 1일부터 5월 31일까지의 낮 최고기온을 측정하였다. (단위 ℃)
1) 등급의 수를 5개로 하여 도수분포표를 작성하라
2) 도수분포표를 기초로 하여 막대그래프와 꺾은선그래프를 작성하라
◆ 도수분포표 생성하기
# 도시의 낮기온 측정
city = [15.2, 11.0, 16.8, 23.2, 14.3, 21.9, 22.4, 20.5, 15.0, 17.0, 12.8, 21.0, 27.7, 28.0,
18.8, 16.4, 14.9, 20.0, 23.5, 23.9, 24.0, 13.2, 13.6, 24.1, 25.9, 30.8, 26.3, 32.1,
29.2, 31.5, 28.5]
# 데이터프레임 생성
df_9 = pd.DataFrame(city)
# 등급의 수를 5개로 하여 나누기
bins = np.linspace(min(city), max(city), 6)
# 도수분포표 생성
freq, bin_edges = np.histogram(city, bins=bins)
# 누적 빈도 구하기
cumulative_freq = np.cumsum(freq)
# 상대적 빈도 구하기
relative_freq = freq / len(city)
# 상대적 누적 빈도 구하기
relative_cumulative_freq = np.cumsum(relative_freq)
# 순도 데이터 프레임 생성하기
df_10 = pd.DataFrame({
'temperature_grade': [f'{round(bin_edges[i], 2)} - {round(bin_edges[i+1], 2)}' for i in range(len(bin_edges)-1)],
'Frequency': freq,
'Cumulative Frequency': cumulative_freq,
'Relative Frequency': relative_freq,
'Cumulative Relative Frequency': relative_cumulative_freq
})
# 합계 행 추가
total_row = pd.DataFrame({
'temperature_grade': ['Total'],
'Frequency': df_10['Frequency'].sum(),
'Cumulative Frequency': ['-'],
'Relative Frequency': df_10['Relative Frequency'].sum(),
'Cumulative Relative Frequency': ['-']
})
# 합계 행 빈도도수표에 붙여주기
df_11 = pd.concat([df_10, total_row], ignore_index=True)
# 빈도도수표 출력하기
print(df_11)
◆ 도수분포표를 사용하여 막대그래프 그리기
# 막대그래프 그리기
import pandas as pd
import matplotlib.pyplot as plt
city = [15.2, 11.0, 16.8, 23.2, 14.3, 21.9, 22.4, 20.5, 15.0, 17.0, 12.8, 21.0, 27.7, 28.0,
18.8, 16.4, 14.9, 20.0, 23.5, 23.9, 24.0, 13.2, 13.6, 24.1, 25.9, 30.8, 26.3, 32.1,
29.2, 31.5, 28.5]
# 데이터프레임 생성
df_9 = pd.DataFrame(city)
# 등급의 수를 5개로 하여 나누기
bins = np.linspace(min(city), max(city), 6)
# 도수분포표 생성
freq, bin_edges = np.histogram(city, bins=bins)
# 누적 빈도 구하기
cumulative_freq = np.cumsum(freq)
# 상대적 빈도 구하기
relative_freq = freq / len(city)
# 상대적 누적 빈도 구하기
relative_cumulative_freq = np.cumsum(relative_freq)
# 순도 데이터 프레임 생성하기
df_10 = pd.DataFrame({
'temperature_grade': [f'{round(bin_edges[i], 2)} - {round(bin_edges[i+1], 2)}' for i in range(len(bin_edges)-1)],
'Frequency': freq,
'Cumulative Frequency': cumulative_freq,
'Relative Frequency': relative_freq,
'Cumulative Relative Frequency': relative_cumulative_freq
})
# 합계 행 추가
total_row = pd.DataFrame({
'temperature_grade': ['Total'],
'Frequency': df_10['Frequency'].sum(),
'Cumulative Frequency': ['-'],
'Relative Frequency': df_10['Relative Frequency'].sum(),
'Cumulative Relative Frequency': ['-']
})
# 합계 행 빈도도수표에 붙여주기
df_11 = pd.concat([df_10, total_row], ignore_index=True)
# 막대 그래프 그리기
plt.figure(figsize=(10, 6))
plt.bar(df_10['temperature_grade'], df_10['Frequency'], color='green')
# 라벨과 제목 추가
plt.xlabel('temperature Grade')
plt.ylabel('Frequency')
plt.title('Frequency Distribution of temperature')
# 더 나은 가독성을 위해 X 라벨을 회전시킴
plt.xticks(rotation=45)
# 차트 출력
plt.show()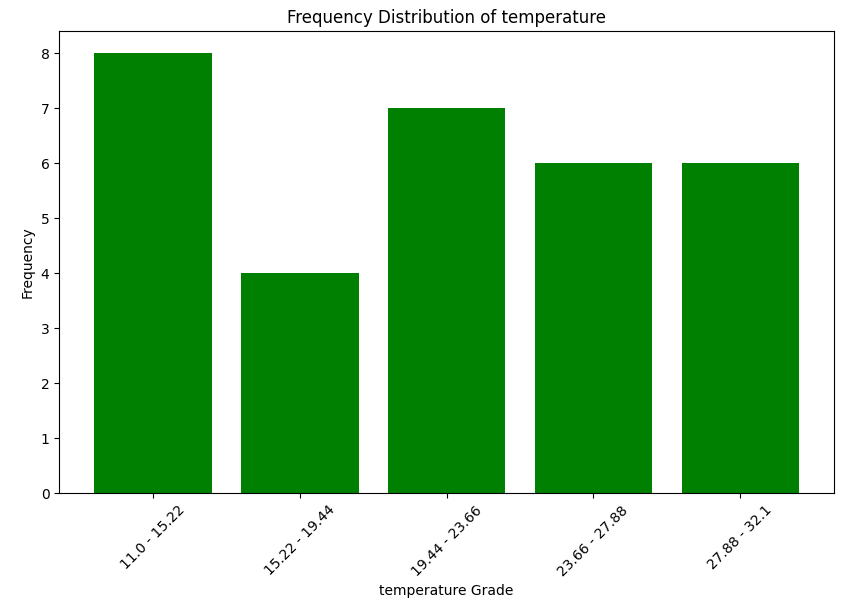
◆ 도수분포표를 사용하여 꺾은선그래프 그리기
# 꺾은선그래프 그리기
import pandas as pd
import matplotlib.pyplot as plt
city = [15.2, 11.0, 16.8, 23.2, 14.3, 21.9, 22.4, 20.5, 15.0, 17.0, 12.8, 21.0, 27.7, 28.0,
18.8, 16.4, 14.9, 20.0, 23.5, 23.9, 24.0, 13.2, 13.6, 24.1, 25.9, 30.8, 26.3, 32.1,
29.2, 31.5, 28.5]
# 데이터프레임 생성
df_9 = pd.DataFrame(city)
# 등급의 수를 5개로 하여 나누기
bins = np.linspace(min(city), max(city), 6)
# 도수분포표 생성
freq, bin_edges = np.histogram(city, bins=bins)
# 누적 빈도 구하기
cumulative_freq = np.cumsum(freq)
# 상대적 빈도 구하기
relative_freq = freq / len(city)
# 상대적 누적 빈도 구하기
relative_cumulative_freq = np.cumsum(relative_freq)
# 순도 데이터 프레임 생성하기
df_10 = pd.DataFrame({
'temperature_grade': [f'{round(bin_edges[i], 2)} - {round(bin_edges[i+1], 2)}' for i in range(len(bin_edges)-1)],
'Frequency': freq,
'Cumulative Frequency': cumulative_freq,
'Relative Frequency': relative_freq,
'Cumulative Relative Frequency': relative_cumulative_freq
})
# 합계 행 추가
total_row = pd.DataFrame({
'temperature_grade': ['Total'],
'Frequency': df_10['Frequency'].sum(),
'Cumulative Frequency': ['-'],
'Relative Frequency': df_10['Relative Frequency'].sum(),
'Cumulative Relative Frequency': ['-']
})
# 합계 행 빈도도수표에 붙여주기
df_11 = pd.concat([df_10, total_row], ignore_index=True)
# 꺾은선 그래프 그리기
plt.figure(figsize=(10, 6))
plt.plot(df_10['temperature_grade'], df_10['Frequency'], marker='o', color='green')
# 라벨과 제목 추가
plt.xlabel('temperature Grade')
plt.ylabel('Frequency')
plt.title('Frequency Distribution of temperature')
# 더 나은 가독성을 위해 X 라벨을 회전시킴
plt.xticks(rotation=45)
# 차트 출력
plt.show()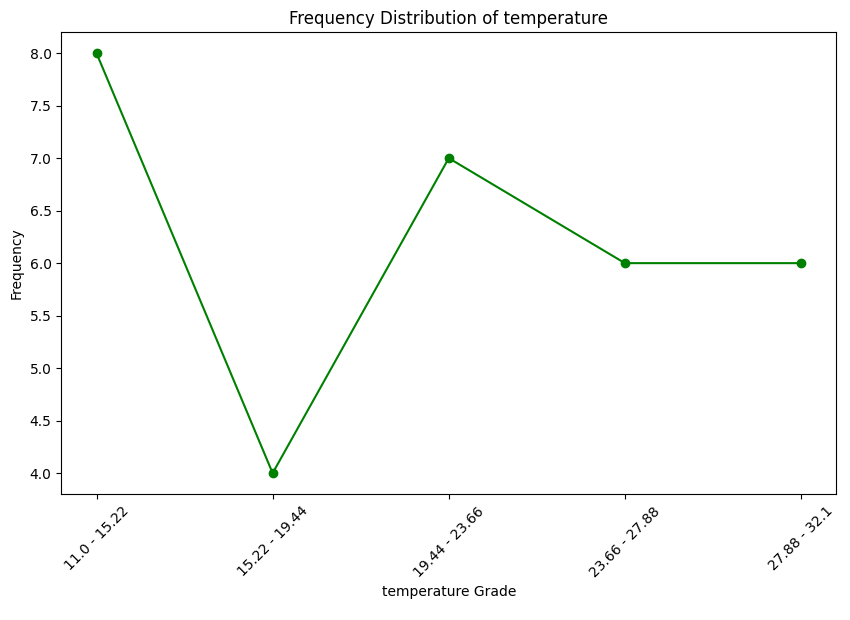
다음 내용
[파이썬+통계학] 현대통계학 연습문제 파이썬 구현(ch.3)-1
★ 시작에 앞서 ★ 해당 내용은 ', 다산출판사, 2024' 에 나와있는 챕터별 연습문제를 교재를 응용하여 풀이하고, 수학적인 문제에 대한 답변을 파이썬으로 구현해보기 위해 작성하는 글이다.해
puppy-foot-it.tistory.com
'[파이썬 Projects] > <파이썬 - 수학 | 통계학>' 카테고리의 다른 글
| [개발자를 위한 수학] 기술 통계: z 점수(+파이썬) (0) | 2024.10.06 |
|---|---|
| [개발자를 위한 수학] 기술 통계: 평균, 분산, 정규 분포(+파이썬) (2) | 2024.10.05 |
| [파이썬+통계학] 현대통계학 연습문제 파이썬 구현(ch.2) - 2 (0) | 2024.10.04 |
| [파이썬+통계학] 현대통계학 연습문제 파이썬 구현(ch.2) - 1 (0) | 2024.10.04 |
| [개발자를 위한 수학] 확률 - 이항 분포, 베타 분포 (+파이썬) (0) | 2024.10.04 |



