텍스트 분석이란?
[머신러닝] 텍스트 분석
이전 내용 [머신러닝] 군집화 (Clustering)군집화(Clustering) [군집]군집은 비슷한 샘플을 클러스터 또는 비슷한 샘플의 그룹으로 할당하는 작업으로, 데이터 분석, 고객 분류, 추천 시스템, 검색 엔
puppy-foot-it.tistory.com
이전 내용
[머신러닝] 텍스트 분석: 한글 텍스트 처리
텍스트 분석이란? [머신러닝] 텍스트 분석이전 내용 [머신러닝] 군집화 (Clustering)군집화(Clustering) [군집]군집은 비슷한 샘플을 클러스터 또는 비슷한 샘플의 그룹으로 할당하는 작업으로, 데이
puppy-foot-it.tistory.com
실습 - 캐글 Mercari Price Suggestion Challenge
◆ Mercari Price Suggestion Challenge:
일본의 대형 온라인 쇼핑몰인 Mercari사의 제품에 대해 가격을 예측하는 캐글에서 진행된 Challenge이다. 제공되는 데이터 세트는 제품에 대한 여러 속성 및 제품 설명 등의 텍스트 데이터로 구성되며, Mercari사는 이러한 데이터를 기반으로 제품 예상 가격을 판매자들에게 제공하고자 한다.
해당 프로세스를 구현하기 위해 판매자는 제품명, 브랜드 명, 카테고리, 제품 설명 등 다양한 속성 정보를 입력하게 되고, ML 모델은 이 속성에 따라 제품의 예측 가격을 판매자에게 자동으로 제공할 수 있다.
https://www.kaggle.com/c/mercari-price-suggestion-challenge
Mercari Price Suggestion Challenge
Can you automatically suggest product prices to online sellers?
www.kaggle.com
상단 링크에 접속하여 'train.tsv.7z' 파일을 다운로드 한다. (캐글 로그인 및 규칙 준수 필수)
[데이터 세트의 속성]
이 파일은 탭으로 구분되어 있다.
- train_id: 목록의 ID
- name: 목록의 제목. 누출을 방지하기 위해 가격(예: $20)처럼 보이는 텍스트를 제거하기 위해 데이터를 정리했다는 점에 유의. 이러한 제거된 가격은 다음과 같이 표시된다.[rm]
- item_condition_id: 판매자가 제공한 품목의 상태
- category_name-: 리스트의 카테고리 명
- brand_name: 브랜드 이름
- price: 품목이 판매된 가격이다. 이것은 당신이 예측할 대상 변수이며, 단위는 USD이다.
- shipping: 판매자가 배송비를 지불한 경우 1, 구매자가 배송비를 지불한 경우 0
- item_description: 품목의 전체 설명. 유출을 방지하기 위해 가격처럼 보이는 텍스트(예: $20)를 제거하기 위해 데이터를 정리했다는 점에 유의. 이러한 제거된 가격은 다음과 같이 표시된다.[rm]
▶ 회귀로 피처를 학습한 뒤 price를 예측하는 문제이며, 이번 실습이 기존 회귀 예제와 다른 점은 item_description 과 같은 텍스트 형태의 비정형 데이터와 다른 정형 속성을 같이 적용해 회귀를 수행한다는 점이다.
데이터 전처리
[데이터, 라이브러리 로딩]
from sklearn.linear_model import Ridge, LogisticRegression
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
import pandas as pd
mercari_df = pd.read_csv("C:/Users/niceq/Documents/DataScience/Python ML Guide/Data/08. mercari_train.tsv", sep='\t')
print(mercari_df.shape)
mercari_df.head()
▶ 1482535개의 레코드를 가지고 있는 데이터 세트이다.
[피처의 타입과 Null 여부 확인]
print(mercari_df.info())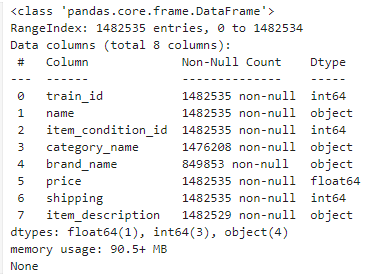
▶ brand_name의 경우가격에 영향을 미치는 중요 요인으로 판단되나, 매우 많은 수의 Null 값을 가지고 있다.
그 외에도 category_name과 item_description 에도 Null 값이 있다. 해당 Null 데이터는 이후에 적절한 문자열로 치환한다.
[Target 값인 price 칼럼의 데이터 분포도 확인, 로그 변환]
회귀에서 Target 값의 정규 분포도는 매우 중요한데, 왜곡돼 있을 경우 보통 로그를 씌워서 변환하면 대부분 정규 분포의 형태를 가지게 된다.
import matplotlib.pyplot as plt
import seaborn as sns
y_train_df = mercari_df['price']
plt.figure(figsize=(6,4))
sns.histplot(y_train_df, bins=100)
plt.show()
▶ price 값이 비교적 적은 가격을 가진 데이터 값에 왜곡돼 분포돼 있어, Price 칼럼을 로그 값으로 변환한 뒤 분포도를 다시 확인해 본다.
import numpy as np
y_train_df = np.log1p(y_train_df)
sns.histplot(y_train_df, bins=50)
plt.show()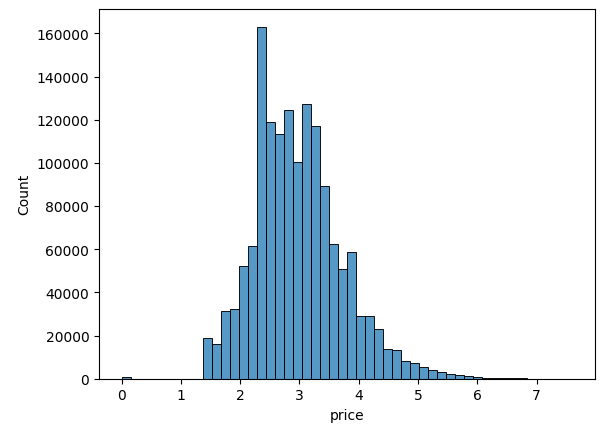
▶ 로그 값으로 변환하면 price 값이 비교적 정규 분포에 가까운 데이터를 이루게 된다. 따라서 데이터 세트의 price 칼럼 값을 원래 값에서 로그로 변환된 값으로 변경한다.
mercari_df['price'] = np.log1p(mercari_df['price'])
mercari_df['price'].head()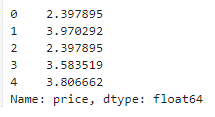
[다른 피처들의 값 유형 확인]
shipping과 item_condition_id 피처 값의 유형 확인
print('Shipping 값 유형:\n', mercari_df['shipping'].value_counts())
print('Item_condition_id 값 유형:\n', mercari_df['item_condition_id'].value_counts())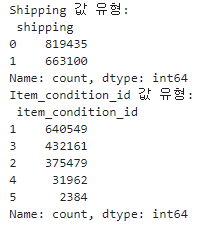
- Shipping (배송비 유무): 값이 비교적 균일
- item_condition_id (판매자가 제공하는 제품 상태): 1, 2, 3 값이 주를 이루고 있음.
item_description 칼럼
item_description 칼럼의 경우, Null 값이 별로 없으나, description에 별도의 설명이 없는 경우 'No description yet' 값으로 돼 있다. 이러한 값이 얼마나 있는지 확인해 본다.
boolean_cond = mercari_df['item_description'] == 'No description yet'
mercari_df[boolean_cond]['item_description'].count()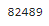
▶ 'No description yet' 로 되어있는 로우는 82489 건인데, 이 경우도 Null과 마찬가지로 의미 있는 속성값으로 사용될 수 없으므로 적절한 값으로 변경해야 한다.
category_name
category_name 은 '/'로 분리된 카테고리를 하나의 문자열로 나타내고 있는데, 텍스트이므로 피처 추출 시 tokenizer를 '/'로 하여 단어를 분리해 벡터화할 수도 있지만, 여기서는 category_name 의 '/' 를 기준으로 단어를 토큰화해 각각 별도의 피처로 저장하고 이를 이용해 알고리즘을 학습시킨다.
이를 위해 '/'를 기준으로 효과적으로 분리해내기 위해 별도의 split_cat() 함수를 생성하고 이를 DataFrame의 apply lambda 식에 적용한다.
split_cat() 함수
- category_name이 Null 이 아닌 경우 split('/')을 이용해 대, 중, 소 분류를 분리
- category_name이 Null 인 경우 split 함수가 에러를 발생하므로 이 Error를 except catch 하여 대, 중, 소 분류 모두 'Other Null' 값 부여
- 대, 중, 소 칼럼은 mercari_df 에서 cat_dae, cat_jung, cat_so로 부여
- zip과 *를 apply lambda 식에 적용하여 판다스의 apply lambda로 반환되는 리스트 요소를 가지고 있는 데이터 세트를 칼럼으로 분리해야 하는 작업을 보다 간단하게 할 수 있다.
# apply lambda에서 호출되는 대, 중, 소 분할 함수 생성, 해당 값을 리스트로 반환
def split_cat(category_name):
try:
return category_name.split('/')
except:
return ['Other_Null', 'Other_Null', 'Other_Null']
# 위의 split_cat()을 apply lambda에서 호출해 대, 중, 소 칼럼을 mercari_df에 생성
mercari_df['cat_dae'], mercari_df['cat_jung'], mercari_df['cat_so'] = zip(*mercari_df['category_name'].apply(lambda x : split_cat(x)))
# 대분류만 값의 유형과 건수를 살펴보고, 중분류, 소분류는 값의 유형이 많으므로 분류 개수만 추출
print('대분류 유형 :\n', mercari_df['cat_dae'].value_counts())
print('중분류 개수 :', mercari_df['cat_jung'].nunique())
print('소분류 개수 :', mercari_df['cat_so'].nunique())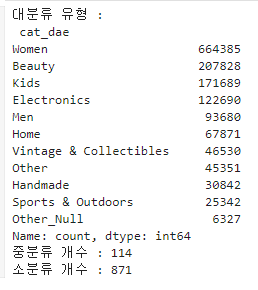
[Null 값 처리]
brand_name, category_name, item_description 칼럼의 Null 값은 일괄적으로 'Other_Null'로 동일하게 변경.
fillna()를 적용한 뒤에 각 칼럼별로 Null 값이 없는지 mercari_df.isnull().sum()을 호출해 확인하여 모든 칼럼에서 Null 건수 확인.
mercari_df['brand_name'] = mercari_df['brand_name'].fillna(value='Other_Null')
mercari_df['category_name'] = mercari_df['category_name'].fillna(value='Other_Null')
mercari_df['item_description'] = mercari_df['item_description'].fillna(value='Other_Null')
# 각 칼럼별로 Null 값 건수 확인
mercari_df.isnull().sum()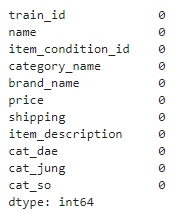
▶ 모두 0이 나와야 한다.
피처 인코딩과 피처 벡터화
문자열 칼럼 중 테이블 또는 원-핫 인코딩을 수행하거나 피처 벡터화로 변환할 칼럼을 선별한다.
Mercari Price Suggestion Challenge에서 예측 모델은 price 값을 예측해야 하므로 회귀 모델을 기반으로 하는데, 선형 회귀 모델과 회귀 트리 모델을 모두 적용할 예정이다.
선형 회귀의 경우 원-핫 인코딩 적용이 훨씬 선호되므로 인코딩할 피처는 모두 원-핫 인코딩을 적용한다.
피처 벡터화의 경우는 비교적 짧은 텍스트의 경우는 Count 기반 벡터화를, 긴 텍스트의 경우는 TF-IDF 기반의 벡터화를 적용한다.
[brand_name 칼럼]
먼저 상품 브랜드명이 어떤 유형인지 유형 건수와 대표적인 브랜드명을 5개 정도만 확인해 본다.
print('brand name의 유형 건수:', mercari_df['brand_name'].nunique())
print('brand name sample 5건: \n', mercari_df['brand_name'].value_counts()[:5])
▶ brand_name의 경우 대부분 명료한 문자열로 되어 있어, 별도의 피처 벡터화 형태로 만들 필요 없이 인코딩 변환을 적용하면 된다. (원-핫 인코딩)
[name 칼럼]
상품명을 의미하는 name 속성이 어떤 유형으로 돼 있는지 유형 건수와 상품명 7개만 출력
print('name의 종류 개수:', mercari_df['name'].nunique())
print('name sample 7건: \n', mercari_df['name'][:7])
▶ name 속성의 경우 종류가 매우 많고 (1,225,273가지), 개별적으로 거의 고유한 상품명을 가지고 있다. 따라서 유형이 매우 많고, 적은 단어 위주의 텍스트 형태로 되어 있으므로 Count 기반으로 피처 벡터화 변환을 적용한다.
[category_name 칼럼]
category_name 칼럼은 전처리를 통해 대, 중, 소 분류 세 개의 칼럼으로 분류되었으므로 해당 칼럼들을 원-핫 인코딩을 적용한다.
[shipping 칼럼, item_condition_id 칼럼]
shipping 칼럼은 0과 1, 두 가지 유형을 가지고 있고, item_condition_id 칼럼은 1, 2, 3, 4, 5의 다섯 가지 유형을 가지고 있다. 이 두 칼럼 모두 원-핫 인코딩을 적용한다.
[item_description 칼럼]
item_description 칼럼은 데이터 세트에서 가장 긴 텍스트를 가지고 있다.
pd.set_option('max_colwidth', 200)
# item_description의 평균 문자열 크기
print('item_description 평균 문자열 크기:', mercari_df['item_description'].str.len().mean())
mercari_df['item_description'][:2]
▶ 해당 칼럼의 2개 정도의 텍스트만 추출하고, 평균 문자열 크기를 확인한 결과 약 145자로 비교적 커 TF-IDF 로 변환한다.
[주요 칼럼 인코딩 및 피처 벡터화 진행]
- name 칼럼: 피처 벡터화 (CountVectorizer, 기본 파라미터)
- item_description 칼럼: 피처 벡터화 (TfidfVectorizer, max_features=5000, n_gram=(1,3), stop_words='english')
# name 속성에 대한 피처 벡터화 변환
cnt_vec = CountVectorizer()
X_name =cnt_vec.fit_transform(mercari_df.name)
# item_description에 대한 피처 벡터화 변환
tfidf_descp = TfidfVectorizer(max_features=50000, ngram_range=(1,3), stop_words='english')
X_descp = tfidf_descp.fit_transform(mercari_df['item_description'])
print('name vectorization shape:', X_name.shape)
print('item_description vectorization shape:', X_descp.shape)
[인코딩 대상 칼럼 희소 행렬 형태로 인코딩 적용]
CountVectorizer, TfidfVectorizer가 fit_transform()을 통해 반환하는 데이터는 희소 행렬 형태이다.
희소 행렬 객체 변수인 X_name, X_descp를 새로 결합해 새로운 데이터 세트로 구성해야 하고, 앞으로 인코딩될 칼럼 모두 X_name, X_descp와 결합돼 ML 모델을 실행하는 기반 데이터 세트로 재구성돼야 한다.
이를 위해 이 인코딩 대상 칼럼도 밀집 행렬 형태가 아닌 희소 행렬 형태로 인코딩을 적용한 뒤, 함께 결합한다.
사이킷런은 원-핫 인코딩을 위해 OneHotEncoder와 LabelBinarizer 클래스를 제공하는데, 이 중 LabelBinarizer 클래스는 희소 행렬 형태의 원-핫 인코딩 변환을 지원하며, 생성 시 sparse_output=True로 파라미터롤 설정해주기만 하면 된다.
모든 인코딩 대상 칼럼은 LabelBinarizer를 이용해 희소 행렬 형태의 원-핫 인코딩으로 변환하는데, 개별 칼럼으로 만들어진 희소 행렬은 사이파이 패키지 sparse 모듈의 hstack() 함수를 이용해 결합한다.
hstack() 함수는 희소 행렬을 손쉽게 칼럼 레벨로 결합할 수 있게 해준다.
from sklearn.preprocessing import LabelBinarizer
# brand_name, item_condition_id, shipping 각 피처들을 희소 행렬 원-핫 인코딩 변환
lb_brand_name = LabelBinarizer(sparse_output=True)
X_brand = lb_brand_name.fit_transform(mercari_df['brand_name'])
lb_item_cond_id = LabelBinarizer(sparse_output=True)
X_item_cond_id = lb_item_cond_id.fit_transform(mercari_df['item_condition_id'])
lb_shipping = LabelBinarizer(sparse_output=True)
X_shipping = lb_shipping.fit_transform(mercari_df['shipping'])
# cat_dae, cat_jung, cat_so 각 피처들을 희소 행렬 원-핫 인코딩 변환
lb_cat_dae = LabelBinarizer(sparse_output=True)
X_cat_dae = lb_cat_dae.fit_transform(mercari_df['cat_dae'])
lb_cat_jung = LabelBinarizer(sparse_output=True)
X_cat_jung = lb_cat_jung.fit_transform(mercari_df['cat_jung'])
lb_cat_so = LabelBinarizer(sparse_output=True)
X_cat_so = lb_cat_so.fit_transform(mercari_df['cat_so'])
제대로 변환됐는지 인코딩 데이터 세트의 타입과 shape 확인
print(type(X_brand), type(X_item_cond_id), type(X_shipping))
print('X_brand shape:{0}, X_item_cond_id shape:{1}'.format(X_brand.shape, X_item_cond_id.shape))
print('X_shipping shape:{0}, X_cat_dae shape:{1}'.format(X_shipping.shape, X_cat_dae.shape))
print('X_cat_jung shape:{0}, X_cat_so shape:{1}'.format(X_cat_jung.shape, X_cat_so.shape))
▶ 인코딩 변환된 데이터 세트가 CSR 형태로 변환된 csr_matrix 타입이다.
brand_name 칼럼의 경우 값의 유형이 4810개이므로 이를 원-핫 인코딩으로 변환한 X_brand_name의 경우 4810개의 인코딩 칼럼을 가지게 되었다.
피처 벡터화 변환한 데이터 세트, 희소 인코딩 변환된 데이터 세트를 hstack()을 이용해 모두 결합한다.
결합된 데이터는 비교적 많은 메모리를 잡아먹기 때문에 타입과 크기만 확인하고 삭제하도록 한다.
삭제는 del '객체 변수명'과 gc.collect()로 진행한다.
from scipy.sparse import hstack
import gc
sparse_matrix_list = (X_name, X_descp, X_brand, X_item_cond_id, X_shipping,
X_cat_dae, X_cat_jung, X_cat_so)
# hstack 함수를 이용해 인코딩과 벡터화를 수행한 데이터 세트 모두 결합
X_features_sparse = hstack(sparse_matrix_list).tocsr()
print(type(X_features_sparse), X_features_sparse.shape)
# 데이터 세트가 메모리를 많이 차지하므로 삭제
del X_features_sparse
gc.collect()
▶ 결합한 데이터 세트는 csr_matrix 타입이며, 총 161569 개의 피처를 가지게 되었다.
릿지 회귀 모델 구축 및 평가
여러 알고리즘 모델과 희소 행렬을 변환하고 예측 성능을 비교하면서 테스트를 수행하기 위해 수행에 필요한 로직을 함수화한다.
- 모델을 평가하는 평가(Evaluation) 로직 함수화: RMSLE(Root Mean Square Logarithmic Error) 방식
- 별도의 RMSLE 를 구하는 함수 rmsle((y, y_pred) 생성
- 학습 모델을 이용한 예측된 price 값은 다시 로그의 역변환인 지수 변환 수행: 학습이 모델에 사용할 price 값은 로그 값으로 변환된 값이므로 예측도 당연히 로그로 변환한 데이터 값 수준의 price 값 예측
- 원복된 데이터를 기반으로 RMSLE를 적용할 수 있도록 evaluate_org_price(y_test, preds) 함수 생성
※ RMSLE는 RMSE와 유사하나 오류 값에 로그를 취해 RMSE를 구하는 방식이며, 여기서는 낮은 가격보다 높은 가격에서 오류가 발생할 경우 오류 값이 더 커지는 것을 억제하기 위해 도입한다.
def rmsle(y, y_pred):
# underflow, overflow 막기 위해 log가 아닌 log1p로 rmsle 계산
return np.sqrt(np.mean(np.power(np.log1p(y) - np.log1p(y_pred), 2)))
def evaluate_org_price(y_test, preds):
# 원본 데이터는 log1p로 변환되었으므로 exmpm1로 원복 필요
preds_exmpm = np.expm1(preds)
y_test_exmpm = np.expm1(y_test)
# rmsle로 RMSLE 값 추출
rmsle_result = rmsle(y_test_exmpm, preds_exmpm)
return rmsle_result
학습용 데이터를 생성하고, 모델을 학습/예측하는 로직을 별도의 함수로 생성
- model_train_predict() 함수: model 인자로 사이킷런의 회귀 estimator 객체를, matrix_list 인자로 최종 데이터 세트로 결합할 희소 행렬 리스트를 가짐 (평가 데이터 세트는 train_test_split()을 이용해 전체의 20%)
import gc
from scipy.sparse import hstack
def model_train_predict(model, matrix_list):
# scipy.sparse 모듈의 hstack을 이용해 희소 행렬 결합
X = hstack(matrix_list).tocsr()
X_train, X_test, y_train, y_test = train_test_split(X, mercari_df['price'], test_size=0.2, random_state=156)
# 모델 학습 및 예측
model.fit(X_train, y_train)
preds = model.predict(X_test)
del X, X_train, y_train
gc.collect()
return preds, y_test
[Ridge를 이용해 Mercari Price의 회귀 예측 수행]
수행 전에 Mercari 상품 가격 예측에 item_description과 같은 텍스트 형태의 속성이 얼마나 영향을 미치는지 확인
(item_description 속성의 피처 벡터화 데이터 포함 여부에 따른 예측 성능)
linear_model = Ridge(solver = 'lsqr', fit_intercept=False)
sparse_matrix_list = (X_name, X_brand, X_item_cond_id, X_shipping,
X_cat_dae, X_cat_jung, X_cat_so)
linear_preds, y_test = model_train_predict(model=linear_model, matrix_list=sparse_matrix_list)
print('Item Description 제외 시 RMSLE 값:', evaluate_org_price(y_test, linear_preds))
sparse_matrix_list = (X_descp, X_name, X_brand, X_item_cond_id, X_shipping,
X_cat_dae, X_cat_jung, X_cat_so)
linear_preds, y_test = model_train_predict(model=linear_model, matrix_list=sparse_matrix_list)
print('Item Description 포함 시 RMSLE 값:', evaluate_org_price(y_test, linear_preds))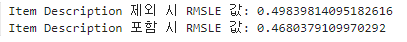
▶ Item Description 포함 시 RMSLE 값이 많이 감소했다.
LightGBM 회귀 모델 구축과 앙상블을 이용한 최종 예측 평가
LightGBM을 이용해 회귀를 수행한 뒤, 앞서 구한 릿지 모델 예측값과 LightGBM 모델 예측값을 간단한 앙상블(Ensemble) 방식으로 섞어서 최종 회귀 예측값을 평가한다.
[LightGBM 회귀 수행]
n_estimator를 1000 이상 증가시키면 예측 성능은 조금 좋아지나, 수행 시간이 너무 오래 걸리므로 200으로 작게 설정하고 예측 성능을 측정해 본다.
from lightgbm import LGBMRegressor
sparse_matrix_list = (X_descp, X_name, X_brand, X_item_cond_id, X_shipping,
X_cat_dae, X_cat_jung, X_cat_so)
lgbm_model = LGBMRegressor(n_estimators=200, learning_rate=0.5, num_leaves=125, random_state=156)
lgbm_preds, y_test = model_train_predict(model= lgbm_model, matrix_list=sparse_matrix_list)
print('LightGBM RMSLE 값:', evaluate_org_price(y_test, lgbm_preds))
[LightGBM 예측 결괏값과 Ridge의 예측 결괏값을 서로 앙상블해 최종 예측값 도출]
LightGBM 결괏값에 0.45를 곱하고 Ridge 결괏값에 0.55를 곱한 값을 서로 합해 최종 예측 결괏값으로 한다.
preds = lgbm_preds * 0.45 + linear_preds * 0.55
print('LightGBM과 Ridge를 ensemble한 최종 RMSLE 값:', evaluate_org_price(y_test, preds))
배율은 임의로 산정하였으니, 최적의 결괏값을 도출하도록 배합 비율을 여러 가지로 하여 수행해보는 것도 좋다.
preds_1 = lgbm_preds * 0.35 + linear_preds * 0.65
preds_2 = lgbm_preds * 0.50 + linear_preds * 0.50
preds_3 = lgbm_preds * 0.65 + linear_preds * 0.35
print('LightGBM 0.35 와 Ridge 0.65 를 ensemble한 최종 RMSLE 값:', evaluate_org_price(y_test, preds_1))
print('LightGBM 0.50 와 Ridge 0.50를 ensemble한 최종 RMSLE 값:', evaluate_org_price(y_test, preds_2))
print('LightGBM 0.65 와 Ridge 0.35 를 ensemble한 최종 RMSLE 값:', evaluate_org_price(y_test, preds_3))
▶ LightGBM 결괏값에 0.35, Ridge 결괏값에 0.65를 곱한 앙상블 값이 가장 좋다.
다음 내용
[머신러닝] 추천 시스템: 콘텐츠 기반 필터링
추천 시스템이란? [머신러닝] 추천시스템이전 내용 [머신러닝] 텍스트 분석이전 내용 [머신러닝] 군집화 (Clustering)군집화(Clustering) [군집]군집은 비슷한 샘플을 클러스터 또는 비슷한 샘플의
puppy-foot-it.tistory.com
[출처]
파이썬 머신러닝 완벽 가이드
'[파이썬 Projects] > <파이썬 머신러닝>' 카테고리의 다른 글
| [머신러닝] 추천 시스템: 콘텐츠 기반 필터링 (1) | 2024.11.01 |
|---|---|
| [머신러닝] 추천시스템 (0) | 2024.11.01 |
| [머신러닝] 텍스트 분석: 한글 텍스트 처리 (6) | 2024.10.31 |
| [머신러닝] 텍스트 분석: 문서 유사도 (6) | 2024.10.31 |
| [머신러닝] 텍스트 분석: 문서 군집화 (2) | 2024.10.31 |



