이전 내용
[파이썬] 프로젝트 : 대시보드 웹 페이지 구축하기 - 4
이전 내용 [파이썬] 프로젝트 : 대시보드 웹 페이지 구축하기 - 3이전 내용 [파이썬] 프로젝트 : 대시보드 웹 페이지 구축하기 - 2이전 내용 [파이썬] 프로젝트 : 대시보드 웹 페이지 구축하기 -
puppy-foot-it.tistory.com
머신러닝 진행해보기
1. 어떤 학습을 진행해야 하는가?
이번엔 오프라인 데이터셋으로 머신러닝을 진행해 보려고 한다.
필자가 생각한 이 데이터를 활용한 머신러닝 분석은
- 시계열 분석을 통한 방문자 또는 참여자 예측 (회귀)
- 데이터를 가지고 성별, 연령대, 지역을 분류해보기 (분류)
- 마찬가지로 성별, 연령대, 지역으로 군집을 나눠보기 (군집분석)
정도가 있는데, 핵심은 마케팅 자료로 활용하기 위한 분석을 해야 한다는 것이다. (마케터에 빙의)
그래서 어떤 분석을 해야 효과적일지 우리의 챗gpt 선생님께 여쭤보기로 한다.
그리하여 gpt 선생님께 받은 답변은 다음과 같다.
1. 고객 세분화 (Customer Segmentation)
- 기법: 군집화 (Clustering)
- 적용 방법:
- K-평균 군집화(K-Means) 또는 계층적 군집화(Hierarchical Clustering)를 통해 고객을 비슷한 특성을 가진 그룹으로 분류합니다.
- 마케팅 활용:
- 특정 세분화된 그룹에 맞춤형 마케팅 캠페인을 설계할 수 있습니다.
- 고객의 행동 패턴을 이해하여 타겟 마케팅을 통해 ROI를 극대화할 수 있습니다.
2. 전환 예측 (Conversion Prediction)
- 기법: 분류 (Classification)
- 적용 방법:
- 로지스틱 회귀(Logistic Regression), 서포트 벡터 머신(SVM), 랜덤 포레스트(Random Forest) 등을 이용하여 고객이 특정 이벤트에 참여할 가능성을 예측합니다.
- 마케팅 활용:
- 전환이 높은 고객군을 타겟으로 하여 더 집중적인 프로모션을 진행할 수 있습니다.
- 고객의 특성에 따라 맞춤형 콘텐츠를 제공하여 참여를 유도할 수 있습니다.
3. 캠페인 성과 분석 (Campaign Performance Analysis)
- 기법: 회귀 분석 (Regression Analysis)
- 적용 방법:
- 선형 회귀(Linear Regression) 모델을 사용하여 캠페인 효과에 대한 방문자 수 또는 참여자 수를 예측합니다.
- 마케팅 활용:
- 지난 캠페인의 데이터를 바탕으로 향후 캠페인에서 기대할 수 있는 방문자 수나 참여자 수를 예측하여 자원 배분을 최적화할 수 있습니다.
- 어떤 변수(예: 연령대, 성별)가 마케팅 캠페인에서 효과적인지를 분석할 수 있습니다.
4. 고객 이탈 예측 (Churn Prediction)
- 기법: 분류 (Classification)
- 적용 방법:
- 특정 변수(예: 참여자 수, 방문자 수)를 기반으로 고객의 이탈 가능성을 예측합니다.
- 마케팅 활용:
- 이탈 가능성이 높은 고객을 사전에 식별하여, 그들에게 맞춤형 혜택이나 프로모션을 제공하여 유지할 수 있습니다.
5. 추천 시스템 (Recommendation System)
- 기법: 추천 알고리즘
- 적용 방법:
- 협업 필터링(Collaborative Filtering) 또는 콘텐츠 기반 필터링(Content-Based Filtering)을 통해 고객에게 적합한 이벤트나 프로모션을 추천합니다.
- 마케팅 활용:
- 개인화된 추천을 통해 고객의 참여를 유도하고, 전환율을 높일 수 있습니다.
하지만, 중요한 것은 머신러닝 분석을 진행한 뒤 스트림릿으로 개발한 웹페이지에 띄워 이해관계자들이 볼 수 있도록 해야하기 때문에 이 추천 내에서 마케팅에 효과적으로 사용될 수 있고, 시각화도 잘 되는 두 가지 조건을 만족하는 기법을 다시 추천 받았다.
이는 챗gpt의 두 번째 추천이다.
- 회귀 분석 (Regression Analysis)
- 목표: 연속적인 값을 예측하고 그 관계를 이해합니다.
- 적용 방법:
- 선형 회귀(Linear Regression) 또는 다항 회귀(Polynomial Regression)를 사용하여 시간에 따른 방문자 수나 참여자 수를 예측합니다.
- 시각화:
- 예측 결과를 선 그래프나 산점도로 시각화하여 실제 값과 예측된 값을 비교할 수 있습니다.
- 마케팅 활용:
- 특정 시기에 고객이 증가하거나 감소할 이유를 분석하여 효율적인 마케팅 전략을 세울 수 있습니다.
- 이동 평균 (Moving Average) 및 시계열 분해 (Time Series Decomposition)
- 목표: 시간에 따른 데이터의 Trends와 Seasonality를 분석합니다.
- 적용 방법:
- 이동 평균 기법을 사용하여 과거의 데이터를 기반으로 미래 방문자 수나 참여자 수를 예측합니다.
- 시계열 분해를 통해 데이터의 추세, 계절성, 잔차성을 시각화할 수 있습니다.
- 시각화:
- 시계열 데이터의 변화를 선 그래프 형태로 나타내어 이해관계자에게 쉽게 설명할 수 있습니다.
- 추세선과 계절적 변화를 함께 표시하여 마케팅 전략 수립에 도움을 줄 수 있습니다.
- ARIMA (AutoRegressive Integrated Moving Average)
- 목표: 시간에 따른 데이터를 보다 정교하게 예측합니다.
- 적용 방법:
- ARIMA 모델을 사용하여 과거 데이터로부터 미래의 방문자 수나 참여자 수를 예측합니다.
- 시각화:
- 예측 결과를 시계열 그래프로 표현하여 실제 값과 예측값의 차이를 쉽게 비교할 수 있습니다.
- 마케팅 활용:
- 특정 시즌이나 연도 별 패턴을 파악하고 미래의 마케팅 광고 및 캠페인 계획에 반영할 수 있습니다.
머신러닝 진행해보기
2. 시계열분석
시계열 분석을 위해 날짜별로 방문자수와 참여자수를 집계해서 날짜를 인덱스로 지정하고 방문자수가 표시되는 vistitor_data를 만든다.
# 시계열 분석
# 날짜를 datetime 형식으로 변환
off_df['날짜'] = pd.to_datetime(off_df['날짜'])
# 데이터 집계 및 병합
off_df_day = off_df.groupby(['날짜']).agg({'방문자수': 'sum', '참여자수': 'sum'}).reset_index()
# 컬럼 이름 변경
off_df_day.rename(columns={'날짜': 'DATE', '방문자수': 'VISITORS', '참여자수': 'PART'}, inplace=True)
# 날짜를 인덱스로 설정
off_df_day.set_index('DATE', inplace=True)
# 방문자 수 데이터 추출
visitor_data = off_df_day['VISITORS']
print(visitor_data.head())
seasonal_decompose 를 통해 계절성을 확인해 보도록 한다.
from statsmodels.tsa.seasonal import seasonal_decompose
# 시계열 데이터 분해
decomposition = seasonal_decompose(visitor_data, model='additive')
fig = decomposition.plot()
plt.show()
# 향후 30일를 예측
forecast = results.get_forecast(steps=30)
forecast_index = pd.date_range(start=visitor_data.index[-1] + pd.Timedelta(days=1), periods=30)
forecast_values = forecast.predicted_mean
# 신뢰구간 계산
confidence_intervals = forecast.conf_int()
# 예측 결과 시각화
plt.figure(figsize=(12, 6))
plt.plot(visitor_data.index, visitor_data, label='실제 방문자')
plt.plot(forecast_index, forecast_values, label='예측 방문자', color='red')
plt.fill_between(forecast_index, confidence_intervals.iloc[:, 0], confidence_intervals.iloc[:, 1], color='pink', alpha=0.3)
plt.title('방문자 예측')
plt.xlabel('날짜')
plt.ylabel('방문자수')
plt.legend(loc='best')
plt.show()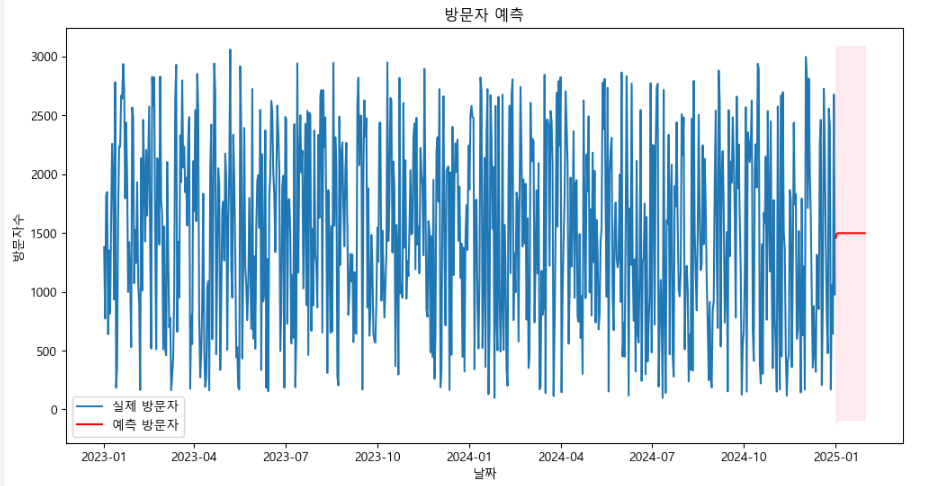
비슷한 방식으로 참여자수도 예측 및 분석해볼 수 있다.(데이터 시각화하느라 진이 빠진 상태라 추후 분석기법을 추가한다면 넣어보겠다.)
이제 이것들을 Streamlit으로 개발한 웹 페이지에 띄우는 작업을 해보도록 한다.
아마도 Streamlit으로 구현 시에는 이렇게 만든 코드들을 대부분 손봐야 할 듯 하다. 💔
다음 내용
[파이썬] 프로젝트 : 대시보드 웹 페이지 구축하기 - 6
이전 내용 [파이썬] 프로젝트 : 대시보드 웹 페이지 구축하기 - 5이전 내용 [파이썬] 프로젝트 : 대시보드 웹 페이지 구축하기 - 4이전 내용 [파이썬] 프로젝트 : 대시보드 웹 페이지 구축하기 - 3
puppy-foot-it.tistory.com
'[파이썬 Projects] > <파이썬 머신러닝>' 카테고리의 다른 글
| [파이썬] 프로젝트 : 웹 페이지 구축 - 12(보완 및 재배포) (1) | 2025.03.26 |
|---|---|
| [파이썬] 프로젝트 : 웹 페이지 구축 - 11(ML 모델 구현) (0) | 2025.03.25 |
| [머신러닝] UCI Wholesale Dataset: KMeans 군집 분석 (0) | 2025.02.16 |
| [머신러닝]텐서플로 모델 훈련과 배포: 버텍스 AI (실패 및 보류) (0) | 2024.12.07 |
| [머신러닝] 도커(Docker) 설치하기 (1) | 2024.12.07 |



