이전 내용
[파이썬] 프로젝트 : 대시보드 웹 페이지 구축하기 - 10
이전 내용 [파이썬] 프로젝트 : 대시보드 웹 페이지 구축하기 - 9이전 내용 [파이썬] 프로젝트 : 대시보드 웹 페이지 구축하기 - 8이전 내용 [파이썬] 프로젝트 : 대시보드 웹 페이지 구축하기 - 7이
puppy-foot-it.tistory.com
예측을 위한 데이터셋 생성하기
필자가 부족해서 기존의 데이터셋으로 머신러닝에 활용하기가 한계가 있다고 느껴 새로운 데이터셋을 생성하기로 결정했다. 회원 중 이벤트에 참여한 1000명의 임의의 회원정보를 추출하여 해당 정보로
- 나이 별로 어떤 유입 경로로 회원 가입을 많이 했는지 ▶ 타겟의 연령별 마케팅 채널 추천
- 어떤 이벤트 진행 후 서비스 가입이 많아졌는지
- 특정 정보를 입력했을 때 이 사람이 서비스 구독을 할지 여부를 예측
등등 보다 다양한 분석과 예측을 할 수 있을거라는 생각이 들었다.
먼저 이를 위해 데이터셋을 생성한다.
# 나이, 도시에 대한 범위 설정
ages = range(25, 66) # 나이 25세부터 65세
cities = range(0, 17) # 17개 도시
bools = [0, 1] # 이진값 (예/아니오, 남자/여자 등)
events = range(0, 7) # 이벤트 7개
channels = range(0, 12) # 유입경로 12개
weights = [0.7, 0.3] # 가중치
# 결과 저장할 리스트
raw_data = {
"age": [], # 나이
"gender": [], # 성별
"marriage": [], # 혼인여부
"city": [], # 도시
"channel": [], # 가입 경로
"before_ev": [], # 이벤트 참여전 구독 여부
"part_ev": [], # 참여 이벤트
"after_ev": [], # 참여후 구독 여부
}
# 함수 정의
def fake_register():
for _ in range(1000):
age = random.choice(ages)
gender = random.choice(bools)
marriage = random.choice(bools)
city = random.choice(cities)
channel = random.choice(channels)
before_ev = random.choice(bools)
part_ev = random.choice(events) # 1개 이상 7개 이하의 이벤트 선택
after_ev = random.choices(bools, weights=weights, k=1)[0] # 가중치 부여
# 데이터 추가
raw_data['age'].append(age)
raw_data['gender'].append(gender)
raw_data['marriage'].append(marriage)
raw_data['city'].append(city)
raw_data['channel'].append(channel)
raw_data['before_ev'].append(before_ev)
raw_data['part_ev'].append(part_ev)
raw_data['after_ev'].append(after_ev)
print("데이터가 생성되었습니다.")
# 데이터 생성 함수 호출
fake_register()
# DataFrame 생성
data = pd.DataFrame(raw_data)
# 데이터 미리 보기
data.head()※ 임의의 값을 생성 또는 선택 시에 가중치를 부여하면 특정 값이 더 잘 선택되도록 할 수 있다.
가상의 데이터이므로, 이벤트 참여 후 서비스 가입률이 상향됐다는 가정 하에 가입 값(0)에 더 높은 가중치를 부여한다.

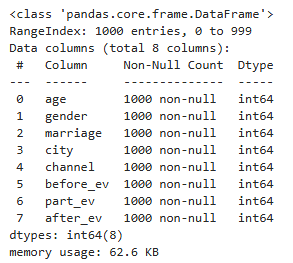
▶ CSV 파일로 잘 저장되었고, 이제 이를 Streamlit으로 띄워보는 작업을 진행한다. (멀티 페이지에 추가)
Streamlit에 데이터프레임 띄우기
pages 폴더 내에 새로운 파일을 만들고 숫자를 지정한 뒤

깃허브에 올려둔 csv raw 파일 경로를 복사한 뒤 st.dataframe으로 불러와 home.py 파일을 실행하면
import pandas as pd
# CSV 파일 경로 설정 (깃허브)
CSV_FILE_PATH = 'https://raw.githubusercontent.com/.../main/'
memeber_df = pd.read_csv(CSV_FILE_PATH + 'members_data.csv')
st.dataframe(memeber_df)
그러나, 출력 시에 모든 값이 숫자로 나오기 때문에 해당 값이 어떤 값을 의미하는지 모르겠으므로, 숫자와 값을 mapping하여 값이 문자로 나타나는 데이터프레임이 출력되도록 수정해주고, expander 버튼을 삽입하여 데이터프레임이 필요치 않을 때는 접히도록 한다.
print_df = memeber_df.rename(columns={
"age": "나이",
"gender": "성별",
"marriage": "혼인여부",
"city": "도시",
"channel": "가입경로",
"before_ev": "참여_전",
"part_ev": "참여이벤트",
"after_ev": "참여_후"
})
# 데이터값 변경
print_df['성별'] = print_df['성별'].map({0:'남자', 1:'여자'})
print_df['혼인여부'] = print_df['혼인여부'].map({0:'미혼', 1:'기혼'})
print_df['도시'] = print_df['도시'].map({0:'부산', 1:'대구', 2:'인천', 3:'대전', 4:'울산', 5:'광주', 6:'서울',
7:'경기', 8:'강원', 9:'충북', 10:'충남', 11:'전북', 12:'전남', 13:'경북', 14:'경남', 15:'세종', 16:'제주'})
print_df['가입경로'] = print_df['가입경로'].map({0:"직접 유입", 1:"키워드 검색", 2:"블로그", 3:"카페", 4:"이메일",
5:"카카오톡", 6:"메타", 7:"인스타그램", 8:"유튜브", 9:"배너 광고", 10:"트위터 X", 11:"기타 SNS"})
print_df['참여_전'] = print_df['참여_전'].map({0:'가입', 1:'미가입'})
print_df['참여이벤트'] = print_df['참여이벤트'].map({0:"워크숍 개최", 1:"재활용 품목 수집 이벤트", 2:"재활용 아트 전시",
3:"게임 및 퀴즈", 4:"커뮤니티 청소 활동", 5:"업사이클링 마켓", 6:"홍보 부스 운영"})
print_df['참여_후'] = print_df['참여_후'].map({0:'가입', 1:'미가입'})
with st.expander('회원 데이터'):
st.dataframe(print_df, use_container_width=True)
머신러닝 모델 구현
탭1. 서비스 가입 여부 예측
우선, 탭을 세 개 만들고 입력받은 정보를 토대로 세 가지의 기계학습을 실행하는 기능을 넣는다.
- 서비스가입 여부 예측
- 추천 캠페인
- 추천 채널
data = memeber_df[['age', 'gender', 'marriage', 'after_ev']]
tab1, tab2, tab3 = st.tabs(['서비스가입 예측', '추천 캠페인', '추천 채널'])
먼저, 첫번째 탭에는 나이, 성별, 혼인여부를 선택하면 랜덤포레스트를 통해 기존 데이터를 학습하여 입력된 정보에 따른 서비스 가입 여부를 예측한다.
from sklearn.model_selection import train_test_split, GridSearchCV, cross_val_score
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.metrics import accuracy_score, classification_report
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
with tab1:
first_column, second_column, thrid_columns = st.columns([6, 2, 2])
with first_column:
st.write("서비스가입 예측 모델입니다. 아래의 조건을 선택해 주세요.")
ages_1 = st.slider(
"연령대를 선택해 주세요.",
25, 65, (35, 45)
)
st.write(f"**선택 연령대: :red[{ages_1}]세**")
with second_column:
gender_1 = st.radio(
"성별을 선택해 주세요.",
["남자", "여자"],
index=1
)
with thrid_columns:
marriage_1 = st.radio(
"혼인여부를 선택해 주세요.",
["미혼", "기혼"],
index=1
)
# 예측 모델 학습 및 평가 함수
def service_predict(data):
# 데이터 전처리 및 파이프라인 설정
numeric_features = ['age']
categorical_features = ['gender', 'marriage']
preprocessor = ColumnTransformer(
transformers=[
('num', StandardScaler(), numeric_features),
('cat', OneHotEncoder(categories='auto'), categorical_features)
]
)
# 랜덤 포레스트 모델
model = Pipeline(steps=[
('preprocessor', preprocessor),
('classifier', RandomForestClassifier(random_state=42, n_jobs=-1)) # n_jobs=-1로 모든 코어 사용
])
# 데이터 분할
X = data.drop(columns=['after_ev'])
y = data['after_ev']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 하이퍼파라미터 튜닝을 위한 그리드 서치
param_grid = {
'classifier__n_estimators': [100, 200], # 늘리면 성능 향상 가능
'classifier__max_depth': [None, 10, 20],
'classifier__min_samples_split': [2, 5]
}
grid_search = GridSearchCV(estimator=model, param_grid=param_grid, cv=3, n_jobs=-1, verbose=2)
grid_search.fit(X_train, y_train)
# 최적의 모델로 예측 수행
y_pred = grid_search.predict(X_test)
# 성능 평가
accuracy = accuracy_score(y_test, y_pred)
st.write(f"이 모델의 테스트 정확도는 {accuracy * 100:.1f}% 입니다.")
return grid_search.best_estimator_, grid_search.best_estimator_.named_steps['classifier'].feature_importances_
# 사용자가 입력한 값을 새로운 데이터로 변환
def pre_result(model, new_data):
prediction = model.predict(new_data)
st.write(f"**모델 예측 결과: :rainbow[{'가입' if prediction[0] == 0 else '미가입'}]**")
# 특성 중요도 시각화
def plot_feature_importance(importances, feature_names):
indices = np.argsort(importances)[::-1]
plt.figure(figsize=(2, 1))
plt.title("특성 중요도")
plt.barh(range(len(importances)), importances[indices], align="center")
plt.yticks(range(len(importances)), [feature_names[i] for i in indices])
plt.xlabel("중요도")
st.pyplot(plt)
# 예측하기 버튼 클릭에 따른 동작
if st.button("예측하기"):
# 기존 데이터로 모델 학습
model, feature_importances = service_predict(data)
# 입력된 값을 새로운 데이터 형식으로 변환
new_data = pd.DataFrame({
'age': [(ages_1[0] + ages_1[1]) / 2], # 나이의 중앙값
'gender': [1 if gender_1 == '여자' else 0], # 성별 인코딩
'marriage': [1 if marriage_1 == '기혼' else 0] # 혼인 여부 인코딩
})
# 예측 수행
pre_result(model, new_data)
# 특성 중요도 시각화
feature_names = ['age'] + list(model.named_steps['preprocessor'].transformers_[1][1].get_feature_names_out())
plot_feature_importance(feature_importances, feature_names)

▶ 모델 정확도가 65.5% 로 높지 않은 편인데, 모델 정확도를 높이기 위해 모델을 여럿 추가했으나 예측하는 데 시간이 너무 오래 걸려 랜덤포레스트 하나만 사용하기로 했다.
머신러닝 모델 구현
탭2. 캠페인 추천
이번에는 사용자 정보를 입력받으면, 해당 정보를 토대로 서비스 가입 확률을 높일 수 있는 캠페인을 추천해주는 모델을 구현해 본다.
데이터를 입력받는 방식은 탭1과 같다. 그러나, 슬라이더를 사용할 경우 그냥 사용해 버리면 중복 때문에 에러를 발생하므로, 꼭 매개변수에 key 값을 지정해줘야 한다.
ages_2 = st.slider(
"연령대를 선택해 주세요.",
25, 65, (35, 45),
key='slider_2'
)
st.write(f"**선택 연령대: :red[{ages_2}]세**")
현재 이벤트 변수(part_ev)는 모두 정수형 값으로 되어 있기 때문에, 추후 추천 서비스 추출 시 이벤트명이 출력될 수 있도록 각 숫자와 이름을 매핑해준다.
여기서도 마찬가지로 랜덤포레스트를 사용해 모델을 학습 및 예측한다.
그리고 효과적인 이벤트를 추천하는 버튼을 누르면 모델이 동작하며 가입 가능성이 가장 높은 이벤트를 반환하고 출력한다.
data_2 = memeber_df[['age', 'gender', 'marriage', 'part_ev', 'after_ev']]
# 참여 이벤트 매핑
event_mapping = {
0: "워크숍 개최",
1: "재활용 품목 수집 이벤트",
2: "재활용 아트 전시",
3: "게임 및 퀴즈",
4: "커뮤니티 청소 활동",
5: "업사이클링 마켓",
6: "홍보 부스 운영"
}
with tab2: # 캠페인 추천 모델
first_column, second_column, thrid_columns = st.columns([6, 2, 2])
with first_column:
st.write("캠페인 추천 모델입니다. 아래의 조건을 선택해 주세요.")
ages_2 = st.slider(
"연령대를 선택해 주세요.",
25, 65, (35, 45),
key='slider_2'
)
st.write(f"**선택 연령대: :red[{ages_2}]세**")
with second_column:
gender_2 = st.radio(
"성별을 선택해 주세요.",
["남자", "여자"],
index=1,
key='radio2_1'
)
with thrid_columns:
marriage_2 = st.radio(
"혼인여부를 선택해 주세요.",
["미혼", "기혼"],
index=1,
key='radio2_2'
)
# 추천 모델 함수
def recommend_event(data_2):
# X, y 설정
X = data_2[['age', 'gender', 'marriage', 'part_ev']]
y = data_2['after_ev']
# 더미 변수 생성하여 참여 이벤트 인코딩
X = pd.get_dummies(X, columns=['part_ev'], drop_first=True)
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.2, random_state=42)
# 렌덤 포레스트 모델 정의 및 학습
model = RandomForestClassifier(random_state=42)
model.fit(X_train, y_train)
return model, X_train.columns # 모델과 피쳐 이름을 반환
# 사용자 정보 입력을 통한 추천 이벤트 평가
if st.button("효과적인 이벤트 추천하기"):
# 추천 모델 훈련
model, feature_names = recommend_event(data_2)
event_results = {}
# 각 이벤트에 대한 추천 가능성 평가
for event in range(7): # part_ev가 0에서 6까지의 숫자이므로, 7개의 이벤트에 대해 반복
# 새로운 사용자 정보 세팅
new_user_data = pd.DataFrame({
'age': [(ages_2[0] + ages_2[1]) / 2], # 연령대의 중앙값
'gender': [1 if gender_2 == '여자' else 0], # 성별 인코딩
'marriage': [1 if marriage_2 == '기혼' else 0], # 혼인 여부 인코딩
'part_ev': [event] # 번호로 매핑된 이벤트
})
# 더미 변수 생성
new_user_data = pd.get_dummies(new_user_data, columns=['part_ev'], drop_first=True)
# 피쳐 정렬
new_user_data = new_user_data.reindex(columns=feature_names, fill_value=0)
# 예측 수행
prediction = model.predict(new_user_data)
event_results[event] = prediction[0] # 가입 여부 저장 (0: 가입, 1: 미가입)
# 가입(0) 가능성이 높은 이벤트 중 가장 높은 것
possible_events = {event: result for event, result in event_results.items() if result == 0}
if possible_events:
best_event = max(possible_events, key=possible_events.get)
st.write(f"**추천 이벤트: :violet[{event_mapping[best_event]}] 👈 이벤트가 가장 효과적입니다!**")
else:
st.write("추천 이벤트: 가입 확률이 높지 않으므로 다른 캠페인을 고려해보세요.")
머신러닝 모델 구현
탭3. 온라인 마케팅 채널 추천
이번엔 같은 정보를 입력 받으면 해당 정보를 토대로 서비스 가입자수를 효과적으로 높일 수 있는 마케팅 채널을 추천해주는 모델을 만든다. 2번탭과 비슷한 맥락으로 진행하면 되는데, 여기서는 추천 채널을 3개로 늘리고, 직접 유입과 같은 일부 채널은 제외시키도록 한다.
data_3 = memeber_df[['age', 'gender', 'marriage', 'channel', 'after_ev']]
# 가입 시 유입경로 매핑
register_channel = {
0:"직접 유입",
1:"키워드 검색",
2:"블로그",
3:"카페",
4:"이메일",
5:"카카오톡",
6:"메타",
7:"인스타그램",
8:"유튜브",
9:"배너 광고",
10:"트위터 X",
11:"기타 SNS"
}
with tab3: # 마케팅 채널 추천 모델
col1, col2, col3 = st.columns([6, 2, 2])
with col1:
st.write("마케팅 채널 추천 모델입니다. 아래의 조건을 선택해 주세요")
ages_3 = st.slider(
"연령대를 선택해 주세요.",
25, 65, (35, 45),
key='slider_3'
)
st.write(f"**선택 연령대: :red[{ages_3}]세**")
with col2:
gender_3 = st.radio(
"성별을 선택해 주세요.",
["남자", "여자"],
index=1,
key='radio3_1'
)
with col3:
marriage_3 = st.radio(
"혼인여부를 선택해 주세요.",
["미혼", "기혼"],
index=1,
key='radio3_2'
)
# 추천 모델 함수
def recommend_channel(data_3):
# X, y 설정
X = data_3[['age', 'gender', 'marriage', 'channel']]
y = data_3['after_ev']
# 더미 변수 생성하여 유입 채널 인코딩
X = pd.get_dummies(X, columns=['channel'], drop_first=True)
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.2, random_state=42)
# 렌덤 포레스트 모델 정의 및 학습
model = RandomForestClassifier(random_state=42)
model.fit(X_train, y_train)
return model, X_train.columns # 모델과 피쳐 이름을 반환
# 사용자 정보 입력을 통한 추천 이벤트 평가
if st.button("효과적인 마케팅 채널 추천받기"):
# 추천 모델 훈련
model, feature_names = recommend_channel(data_3)
channel_results = {}
# 각 이벤트에 대한 추천 가능성 평가
for channel in range(12): # part_ev가 0에서 12까지의 숫자이므로, 12개의 이벤트에 대해 반복
if channel in (0,1): # 직접 유입과 키워드 검색 채널 제외
continue
# 새로운 사용자 정보 세팅
new_user_data = pd.DataFrame({
'age': [(ages_2[0] + ages_2[1]) / 2], # 연령대의 중앙값
'gender': [1 if gender_2 == '여자' else 0], # 성별 인코딩
'marriage': [1 if marriage_2 == '기혼' else 0], # 혼인 여부 인코딩
'channel': [channel] # 번호로 매핑된 채널
})
# 더미 변수 생성
new_user_data = pd.get_dummies(new_user_data, columns=['channel'], drop_first=True)
# 피쳐 정렬
new_user_data = new_user_data.reindex(columns=feature_names, fill_value=0)
# 예측 수행
prediction = model.predict(new_user_data)
channel_results[channel] = prediction[0] # 가입 여부 저장 (0: 가입, 1: 미가입)
# 가입(0) 가능성이 높은 채널 중 가장 높은 것 3개
possible_channels = {channel: result for channel, result in channel_results.items() if result == 0}
if possible_channels:
best_channels = sorted(possible_channels.keys(), key=lambda x: possible_channels[x])[:3] # 가장 좋은 3개 채널
recommended_channels = [register_channel[ch] for ch in best_channels]
st.write(f"**추천 마케팅 채널:** :violet[{', '.join(recommended_channels)}] 👈 이 채널들이 가장 효과적입니다!")
else:
st.write("추천 마케팅 채널: 가입 확률이 높지 않으므로 다른 채널을 고려해보세요.")
이제 깃허브에 들어가서 새로운 파일을 포함하여 전체 파일을 다시 한 번 업로드해 준다.

Streamlit에서 적용이 잘 된다.

이제 어제 해결하지 못한 Streamlit 클라우드에 DB 연동을 해결해 볼 차례다.
▶ 교수님이 알려주시기로는 Streamlit 클라우드에서 무료로 서버를 사용할 수 있다고 했는데, 잘못 알려주신 거 같다. AWS의 RDS를 이용하면 DB를 사용할 수 있으나, 해당 프로젝트는 제출용이므로 작업 시에는 파일을 DB로 불러오지 않고 CSV로 받아오는 형식으로 바꿔서 진행하기로 변경하였다.
다음 내용
[파이썬] 프로젝트 : 웹 페이지 구축 - 12(보완 및 재배포)
이전 내용 [파이썬] 프로젝트 : 웹 페이지 구축 - 11(ML 모델 구현)이전 내용 [파이썬] 프로젝트 : 대시보드 웹 페이지 구축하기 - 10이전 내용 [파이썬] 프로젝트 : 대시보드 웹 페이지 구축하기 - 9
puppy-foot-it.tistory.com
'[파이썬 Projects] > <파이썬 머신러닝>' 카테고리의 다른 글
| [파이썬] 프로젝트 : 웹 페이지 구축 - 12(보완 및 재배포) (1) | 2025.03.26 |
|---|---|
| [파이썬] 프로젝트 : 웹 페이지 구축 - 5 (머신러닝) (0) | 2025.03.20 |
| [머신러닝] UCI Wholesale Dataset: KMeans 군집 분석 (0) | 2025.02.16 |
| [머신러닝]텐서플로 모델 훈련과 배포: 버텍스 AI (실패 및 보류) (0) | 2024.12.07 |
| [머신러닝] 도커(Docker) 설치하기 (1) | 2024.12.07 |



