★ EDA의 4가지 주제에 대한 설명으로 가장 알맞지 않은 것은?
1. 저항성: 수집된 자료에 오류점, 이상값이 있을 때에도 영향을 적게 받는 성질
2. 잔차: 관찰 값들이 주 경향으로부터 얼마나 벗어난 정도
3. 자료의 재표현: 데이터 분석과 해석을 단순화할 수 있도록 원래 변수를 적당한 척도로 바꾸는 것
4. 현시성: 로그 변환, 제곱근 변환, 역수 변환 등을 통해 데이터 분석 결과를 쉽게 이해할 수 있도록 시각적으로 표현하고 전달하는 과정 ▶ 로그 변환, 제곱근 변환, 역수 변환 등은 자료의 재표현에 관한 내용
| 특징(주제) | 내용 |
| 저항성 (Resistance) | - 수집된 자료에 오류점, 이상값이 있을 때에도 영향을 적게 받는 성질 (탐색적 데이터 분석은 저항성이 큰 통계적 데이터 이용) |
| 잔차(Residual) 해석 | - 잔차를 구해봄으로써 데이터의 보통과 다른 특징 탐색 - 주 경향에서 벗어난 값이 왜 존재하는지에 대해 탐색하는 작업 (잔차: 관찰 값들이 주 경향으로부터 얼마나 벗어난 정도) |
| 자료 재표현 (Re-expression) | - 데이터 분석과 해석을 단순화할 수 있도록 원래 변수를 적당한 척도로 바꾸는 것 - 자료의 재표현을 통하여 분포의 대칭성, 분포의 선형성, 분산의 안정성 등 데이터 구조파악과 해석에 도움을 얻는 경우가 많음 - 로그 변환, 제곱근 변환, 역수 변환 등 |
| 현시성 (Graphic Representation) | - Display, Visualization, 데이터 시각화 - 데이터 분석 결과를 쉽게 이해할 수 있도록 시각적으로 표현하고 전달하는 과정 - 자료 안에 숨어있는 정보를 시각적으로 나타내줌으로써 자료의 구조를 효율적으로 파악 가능 |
★ 다음 중 정제 과정에서 수행하는 내용은?
1. 데이터의 결측값을 처리하고 데이터 탐색
2. 수집된 데이터 통합 ▶ 데이터 수집 단계
3. 데이터를 분석 목적에 맞게 데이터 검증 ▶ 분석 모형 평가 단계
4. ETL 프로그램 개발 ▶ 데이터 수집 단계
▶ 데이터 정제 과정에서는 결측값, 노이즈, 이상값인 오류 데이터값을 정확한 데이터로 수정하거나 삭제
[데이터 오류 원인]
결측값, 노이즈, 이상값
- 결측값: 필수적인 데이터가 입력되지 않고 누락된 값
- 노이즈: 실제는 입력되지 않았지만 입력되었다고 잘못 판단된 값
- 이상값: 데이터의 범위에서 많이 벗어난 아주 작은 값이나 아주 큰 값
★ 이상값을 찾는 방법으로 옳지 않은 것은?
1. 단변량이면 박스플롯(Boxplot)을, 다변량이면 산점도(Scatter Plot)를 이용하여 파악
2. 평균으로부터 3시그마 떨어진 곳의 값 파악
3. 물리적으로 불가능한 값이나 도메인의 범위를 이용해서 파악
4. 노이즈값을 계산하여 찾음
▶ 이상값은 시각화를 이용해 (단변량 - 박스플롯 / 다변량 - 산점도) 파악할 수 있고, 통계적 기법인 ESD(평균으로부터 3시그마 떨어진 값)로 파악 가능. 도메인의 범위를 벗어나거나 가능하지 않은 값도 이상값으로 판단 가능
★ 다음 중 이상값 검출 방법 중 평균이 μ이고, 표준편차가 σ인 정규분포를 따르는 관측치들이 자료의 중심(평균)에서 얼마나 떨어져 있는지를 나타냄으로써 이상값을 검출하는 방법은?
1. 카이제곱 검정을 활용한 방법
2. Z-점수를 활용한 방법
3. 사분위수를 활용한 방법
4. 통계적 가설검정을 활용한 방법
▶[통계 기법을 이용한 데이터 이상값 검출]
ESD, 기하평균, 사분위수, Z-점수, Q검정, T-검정, 카이제곱 검정, 마할라노비스 거리
★ ESD(Extreme Studentized Deviation)에 대한 설명으로 옳은 것은?
1. 평균(μ) 으로부터 3 표준 편차(σ) 떨어진 값(각 0.15%)을 이상값으로 판단
2. 기하평균으로부터 2.5 표준편차 (σ) 떨어진 값을 이상값으로 판단 ▶ 기하평균 활용한 방법
3. 제1 사분위, 제3 사분위를 기준으로 사분위간 범위(Q3 - Q1) 의 1.5배 이상 떨어진 값을 이상값으로 판단 ▶ 사분위수를 이용한 방법
4. 평균이 μ 이고, 표준편차가 σ 인 정규분포를 따르는 관측치들이자료의 중심(평균) 중심에서 얼마나 떨어져 있는지를 나타냄에 따라서 이상값 검출 ▶ Z-점수를 활용한 이상값 검출
- ESD: 평균(μ) 으로부터 3 표준 편차(σ) 떨어진 값(각 0.15%)을 이상값으로 판단
- 기하평균 활용한 방법: 기하평균으로부터 2.5 표준편차 (σ) 떨어진 값을 이상값으로 판단
- 사분위수를 이용한 방법: 제1 사분위, 제3 사분위를 기준으로 사분위간 범위(Q3 - Q1) 의 1.5배 이상 떨어진 값을 이상값으로 판단
- Z-점수 활용: 평균이 μ 이고, 표준편차가 σ 인 정규분포를 따르는 관측치들이자료의 중심(평균) 중심에서 얼마나 떨어져 있는지를 나타냄에 따라서 이상값 검출
- 딕슨의 Q 검정: 오름차순으로 정렬된 데이터에서 범위에 대한 관측치 간의 차이의 비율을 활용하여 이상값 여부를 검정
- 그럽스 T-검정: 정규분포를 만족하는 단변량 자료에서 이상값을 검정하는 방법
- 카이제곱 검정: 데이터가 정규분포를 만족하나, 자료의 수가 적은 경우에 이상값을 검정하는 방법
- 마할라노비스 거리 활용: 데이터의 분포를 고려한 거리 측도로, 관측치가 평균으로부터 벗어난 정도를 측정하는 통계량 기법
★ 다음이 설명하는 데이터 이상값 검출 방법은?
| 데이터의 분포를 고려한 거리 측도로, 관측치가 평균으로부터 벗어난 정도를 측정하는 통계량 기법 |
▶ 마할라노비스 거리 활용
| 개별 데이터 관찰 | - 전체 데이터의 추이나 특이 사항 관찰하여 이상값 검출 - 전체 데이터 중 무작위 표본추출 후 관찰하여 이상값 검출 |
| 통계값 | 통계 지표 데이터 (평균, 중위수, 최빈수)와 데이터 분산도(범위, 분산)를 활용한 이상값 검출 |
| 시각화 | 데이터 시각화를 통한 지표 확인으로 이상값 검출 |
| 머신러닝 기법 | 데이터 군집화를 통한 이상값 검출 |
| 마할라노비스 거리 활용 | 데이터의 분포를 고려한 거리 측도로, 관측치가 평균으로부터 벗어난 정도를 측정하는 통계량 기법 |
| LOF | 관측지 주변의 밀도와 근접한 관측지 주변의 밀도의 상대적인 비교를 통해 이상값 탐색 |
| iForest | 관측치 사이의 거리 또는 밀도에 의존하지 않고, 데이터 마이닝 기법인 의사결정나무를 이용하여 이상값 탐지 |
★ 결측값을 처리하는 단순 대치법의 종류에 해당하지 않는 것은?
1. 완전 분석법
2. 평균 대치법
3. 단순 확률 대치법
4. ESD ▶ ESD(Extreme Studentized Deviation) 은 이상값을 측정하기 위한 기법
▶
[결측값 처리 방법: 단순 대치법, 다중 대치법]
ㄱ. 단순 대치법
- 결측값을 그럴듯한 값으로 대체하는 통계적 기법
- 결측값을 가진 자료 분석에 사용하기가 쉽고, 통계적 추론에 사용된 통계량의 효율성 및 일치성 등의 문제를 부분적으로 보완
- 대체된 자료는 결측값 없이 완전한 형태
[종류]
- 완전 분석법: 불완전 자료는 모두 무시하고 완전하게 관측된 자료만 사용하여 분석
- 평균 대치법: 관측 또는 실험되어 얻어진 자료의 평균값으로 결측값을 대치해서 불완전한 자룔르 완전한 자료로 만드는 방법
- 단순 확률 대치법: 평균 대치법에서 관측된 자료를 토대로 추정된 통계량으로 결측값을 대치할 때 어떤 적절한 확률값을 부여한 후 대치하는 방법
[단순 확률 대치법 종류]
- 핫덱 대체: 무응답을 현재 진행 중인 연구에서 '비슷한' 성향을 가진 응답자의 자료로 대체 (표본조사에서 흔히 사용)
- 콜드덱 대체: 핫덱과 비슷하나 대체할 자료를 외부 출처 또는 이전의 비슷한 연구에서 가져오는 방법
- 혼합방법: 몇 가지 다른 방법을 혼합
ㄴ. 다중 대치법
- 단순 대치법을 한 번 하지 않고 m번 대치를 통해 m개의 가상적 완전한 자료를 만들어서 분석하는 방법
- 대치 → 분석 → 결합의 3단계
- 원 표본의 결측값을 한 번 이상 대치하여 여러 개의 대치된 표본을 구하는 방법
- D개의 대치된 표본을 만들어야 하므로 항상 같은 값으로 결측 자료를 대치할 수 없음
★ 스케일링에 대한 설명으로 틀린 것은?
1. 범주형에 대해 정규화 수행 가능
2. 최소-최대 정규화는 -1과 1사이의 값을 가짐
3. 평균이 0, 분산이 1인 Z-점수 정규화를 수행
4. 편향된 데이터에 대해 스케일링 가능
▶ 최소-최대 정규화는 변수의 값 범위를 모두 일정한 수준으로 맞춰주기 위해 모든 값을 0과 1 사이의 값으로 변환
★ 다음 중 불균형 데이터 처리 중 과소 표집에 대한 설명으로 틀린 것은?
1. 과소 표집은 다수 클래스의 데이터를 일부만 선택하여 데이터의 비율을 맞추는 방법
2. 토멕 링크 방법은 다수 클래스에 속한 토멕 링크를 제거하는 방법
3. CNN (Condensed Nearest Neighnor) 은 소수 클래스에서 중심이 되는 데이터와 주변 데이터 사이에 가상의 직선을 만든 후, 그 위에 데이터를 추가하는 방법 ▶다수 클래스에 밀집된 데이터가 없을 때까지 데이터를 제거하여 데이터 분포에서 대표적인 데이터만 남도록 하는 방법
4. ENN (Edited Nearest Neighbor) 은 소수 클래스 주위에 인접한 다수 클래스 데이터를 제거하여 데이터의 비율을 맞추는 방법
★ 각 클래스의 데이터에 불균형이 발생한 경우 학습 단계에서의 처리 방법으로 가장 옳지 않은 것은?
1. 과소 표집
2. 과대 표집
3. 임곗값 이동 ▶데이터가 많은 클래스로 임곗값을 이동시키는 방법 (학습 단계에서는 그대로 학습하고 테스트 단계에서 이동)
4. 가중치 적용
★ 정확한 데이터 분석을 위해서는 불균형 데이터 처리가 필요하다. 다음 중 불균형 데이터 처리에 대해 올바르지 않은 것은?1. 과소표집: 데이터양을 감소시켜서 불균형 데이터를 처리하는 방법, 과대표집: 데이터양을 증가시켜서 불균형 데이터를 처리하는 방법2. 앙상블 기법: 같거나 서로 다른 여러 가지 모형들이 예측/분류 결과를 종합하여 최종적인 의사 결정에 활용3. SMOTE : 소수 클래스에서 중심이 되는 데이터와 주변 데이터 사이에 가상의 직선을 만든 후, 그 위에 데이터를 추가
4. 임곗값 이동: 임곗값을 데이터가 많은 쪽으로 이동시키는 방법, 학습단계에서부터 임곗값 이동
▶ 학습 단계에서는 그대로 학습하고 테스트 단계에서 이동
★ 불균형 데이터 처리 방법으로 옳지 않은 것은?
1. 언더 샘플링 ▶ 과소 표집 (다수 클래스의 데이터 일부만 선택하여 데이터 비율 맞춤)
2. 경곗값 이동 ▶ 임곗값 이동 (임곗값을 데이터가 많은 쪽으로 이동)
3. 비용 민감 학습 ▶ 소수 클래스에 높은 가중치 부여
4, 정규화 ▶ 데이터를 특정 구간으로 바꾸는 척도법 (변수 변환에 해당)
★ 다음 중 불균형 데이터 처리에 대한 설명으로 올바르지 않은 것은?
1. 탐색하는 데이터의 타깃 수가 매우 극소수인 경우 사용
2. 불균형 데이터 처리를 수행하면 소수 클래스에 대한 정밀도 향상
3. 불필요한 변수를 제거하고 새로운 변수를 생성시키는 작업 ▶ 변수 변환 기법
4. 과소 표집이나 소수 클래스 데이터를 증가시키는 과대 표집 사용
[불균형 데이터 처리]
(1) 과소 표집 (Uunder-Sampling)
- 다수 클래스의 데이터를 일부만 선택하여 데이터의 비율을 맞추는 방법
- 데이터의 소실이 매우 크고, 때로는 중요한 정상 데이터를 잃을 수 있음
- 대표적인 기법: 랜덤 과소 표집, ENN, 토멕 링크 방법, CNN, OSS 등
| 기법 | 설명 |
| 랜덤 과소 표집 | 무작위로 클래스 데이터의 일부만 선택 |
| ENN (Edited Nearest Neighbor) | 소수 클래스 주위에 인접한 다수 클래스 데이터를 제거하여 데이터의 비율을 맞추는 방법 |
| 토멕 링크 방법 | 다수 클래스에 속한 토멕 링크를 제거하는 방법 (토멕 링크: 클래스를 구분하는 경계선 가까이에 존재하는 데이터) |
| CNN (Condensed Nearest Neighbor) | 다수 클래스에 밀집된 데이터가 없을 때까지 데이터를 제거하여 데이터 분포에서 대표적인 데이터만 남도록 하는 방법 |
| OSS (One Sided Selection) | 토멕 링크 방법과 CNN 기법의 장점을 섞은 방법 (다수 클래스의 데이터를 토멕 링크 방법으로 제거한 후 CNN을 이용하여 밀집된 데이터 제거) |
(2) 과대 표집(Over-Sampling)
- 소수 클래스의 데이터를 복제 또는 생성하여 데이터의 비율을 맞추는 방법
- 정보가 손실되지 않는다는 장점 / 과적합을 초래할 수 있다는 단점
- 알고리즘의 성능은 높으나 검증의 성능은 나빠질 수 있음
- 대표적인 기법: 랜덤 과대 표집, SMOTE, Borderline-SMOTE, ADASYN 등
| 기법 | 설명 |
| 랜덤 과대 표집 | 무작위로 소수 클래스 데이터를 복제하여 데이터의 비율을 맞추는 방법 |
| SMOTE (Synthetic Minority Over-Sampling Technique) | 소수 클래스에서 중심이 되는 데이터와 주변 데이터 사이에 가상의 직선을 만든 후, 그 위에 데이터를 추가하는 방법 |
| Borderline-SMOTE | 다수 클래스와 소수 클래스의 경게선에서 SMOTE 를 적용하는 방법 |
| ADASYN (ADAprtive SYNthetic) | 모든 소수 클래스에서 다수 클래스의 관측비율을 계산하여 SMOTE를 적용하는 방법 |
(3) 임곗값 이동
- 임곗값을 데이터가 많은 쪽으로 이동시키는 방법
- 학습 단계에서는 변화 없이 학습하고 테스트 단계에서 임곗값 이동
(4) 비용 민감 학습
- 소수 클래스에 높은 가중치를 부여하는 방법
- 과소 표집처럼 데이터를 일부만 선택하거나, 과대 표집처럼 데이터를 생성하지 않음
(5) 앙상블 기법
- 같거나 서로 다른 여러 가지 모형들의 예측/분류 결과를 종합하여 최종적인 의사 결정에 활용하는 기법
- 앙상블 알고리즘은 여러 개의 학습 모델을 훈련하고 투표 및 평균을 통해 최적화된 예측을 수행하고 결정
- 주어진 자료로부터 여러 개의 예측 모형을 만든 후 예측 모형들을 조합하여 하나의 최종 예측 모형을 만드는 방법
- 다중 모델 조합, 분류기 조합 등
- 과소 표집, 과대 표집, 임곗값 이동을 조합하여 앙상블 생성 가능
★ 차원 축소에 대한 설명으로 틀린것은?
1. 차원 축소의 방법에는 변수 선택과 변수 추출이 있다
2. 여러 변수의 정보를 최대한 유지하기 위해 데이터 세트 변수의 개수 유지
3. 차원 축소 후 학습할 경우, 회귀나 분류, 클러스터링 등의 머신러닝 알고리즘이 더 잘 작동
4. 새로운 저차원 변수 공간에서 시각화 용이
▶ 차원 축소는 분석 대상이 되는 여러 변수의 정보를 최대한 유지하면서 데이터 세트 변수의 개수를 줄이는 탐색적 분석 기법
★ 주성분 분석에 대한 설명으로 가장 올바르지 않은 것은?
1. 상관관계가 있는 고차원 자료를 자료의 변동을 최대한 보존하는 저차원 자료로 변환하는 차원 축소 방법
2. 변수들의 공분산 행렬이나 상관 행렬 이용
3. 행의 수와 열의 수가 같은 정방행렬에서만 사용
4. 다변량의 신호를 통계적으로 독립적인 하부 성분으로 분리하여 축소하는 기법 ▶ 독립성분 분석
[차원축소]
(1) 개념
- 분석대상이 되는 여러 변수의 정보를 최대한 유지하면서 데이터 세트 변수의 개수를 줄이는 탐색적 분석기법
- 원래의 데이터를 최대한 효가적으로 축약하기 위해 목표변수(y)는 사용하지 않고 특성 변수 (설명변수)만 사용하기 때문에 비지도 학습 머신러닝 기법
(2) 특징
- 정보유지: 차원축소를 수행할 때, 축약되는 변수 세트는 원래의 전체 데이터의 변수들의 정보를 최대한 유지
- 모델 학습의 용이: 고차원 변수보다 변환된 저차원으로 학습할 경우, 회귀나 분류, 클러스터링 등의 머신러닝 알고리즘이 더 잘 작동
- 결과 해석의 용이: 새로운 저차원 변수 공간에서 시각화하기도 쉬움
(3) 방법 - 변수 선택 / 변수 추출
- 변수 선택: 가지고 있는 변수들 중에 중요한 변수만 몇 개 고르고 나머지는 버리는 방법
- 변수 추출: 모든 변수를 조합하여 이 데이터를 잘 표현할 수 있는 중요 성분을 가진 새로운 변수 추출
(4) 기법
주성분 분석, 특이값 분해, 요인 분석, 독립 성분 분석, 다차원 척도법
- 주성분 분석: 원래 데이터 특징을 잘 설명해주는 성분을 추출하기 위하여 고차원 공간의 표본들을 선형 연관성이 없는 저차원 공간으로 변환하는 기법 (변수들의 공분산 행렬이나 상관행렬을 이용)
- 특이값 분해: M * N 차원의 행렬데이터에서 특이값을 추출하고 이를 통해 주어진 데이터 세트를 효과적으로 축약할 수 있는 기법
- 요인 분석: 모형을 세운 뒤 관찰 가능한 데이터를 이용하여 해당 잠재 요인을 도출하고 데이터 안의 구조를 해석하는 기법 (데이터 안에 관찰할 수 없는 잠재적인 변수가 존재한다고 가정, 주로 사회과학이나 설문 조사)
- 독립 성분 분석: 다변량의 신호를 통계적으로 독립적인 하부성분으로 분리하여 차원을 축소하는 기법
- 다차원 척도법: 개체들 사이의 유사성, 비유사성을 측정하여 2차원 또는 3차원 공간 상에 점으로 표현하여 개체들 사이의 집단화를 시각적으로 표현하는 분석 방법
(5) 주요 활용 분야
- 탐색적 데이터 분석
- 변수 집합에서 주요 특징을 추출하여 타 분석기법의 설명변수로 활용
- 텍스트 데이터에서 주제나 개념 추출
- 이미지 및 사운드 등의 비정형 데이터에서 특징 패턴 추출
- 기업의 판매데이터에서 상품 추천시스템 알고리즘 구현
- 다차원 공간의 정보를 저차원으로 시각화
- 공통 요인을 추출하여 잠재된 데이터 규칙 발견
★ 표준화에 대한 설명으로 옳은 것은?
1. 표준화는 입력값에서 평균을 뺀 값에 분산을 나눠 계산 ▶표준화는 입력값에서 평균을 뺀 값에 표준편차를 나눠 계산
2. 정규분포를 표준화하면 표준정규분포가 된다
3. 표준화의 최대값은 1
4. 표준화의 표준 편차는 0
★ 다음 중 아래에서 설명하고 있는 데이터 변환 기법은?
| - Feature의 값이 평균과 일치하면 0으로 정규화되고, 평균보다 작으면 음수, 크면 양수로 변환하는 방법 - 이상값 문제를 피하는 데이터 정규화로 이상값은 잘 처리하지만, 정확히 같은 척도로 정규화된 데이터를 생성하지는 못한다는 단점이 있음 |
1. 행렬 변환
2. 지수 변환
3. 최소-최대 정규화
4. Z-점수 정규화
▶ [정규화]
- 데이터를 특정 구간으로 바꾸는 척도법
- 최소-최대 정규화: 모든 변수에 대해 최솟값은 0, 최댓값은 1로, 최솟값 및 최댓값을 제외한 다른 값들은 0과 1 사이의 값으로 변환하는 방법 (모든 변수의 스케일이 같지만 이상값에 영향을 많이 받음)
- Z-점수 정규화: 변수의 값이 평균과 일치하면 0으로 정규화되고, 평균보다 작으면 음수, 크면 양수로 변환하는 방법 (이상값은 잘 처리하지만, 정확히 같은 척도로 정규화된 데이터를 생성하지 못함)
- 분위수 정규화: 여러 집단의 분포를 완전히 동일하게 만드는 방법 (비교하려는 샘플들의 분포를 완전히 동일하게 만들고 싶을 때 사용 / 고차원의 데이터를 분석할 때 사용 / 집단 간 같은 개수의 데이터를 가져야 함)
★ 아래의 변수 선택 기법 중 필터 기법으로 가장 적절하지 않은 것은?
1. 정보 이득
2. 카이제곱 검정
3. 피셔 스코어
4. 라쏘 ▶ 라쏘 기법은 임베디드 기법
★ 특정 모델링 기법에 의존하지 않고 데이터의 통계적 특성으로부터 변수를 택하는 기법은?
1. 필터 기법
2. 래퍼 기법 ▶ 변수의 일부만을 모델링에 사용하고 그 결과를 확인하는 작업을 반복하면서 변수를 택해나가는 기법
3. 임베디드 기법 ▶ 모델 체에 변수 선택이 포함된 기
4. 단순 기법
| 엠베디드 기법 | 설명 |
| 라쏘(LASSO; Least Absolute Shrinkage and Selection Operator) | -가중치의 절댓값의 합을 최소화하는 것을 추가적인 제약조건으로 하는 방법 - L1 노름 규제를 통해 제약을 주는 방법 (두 점 간 차의 절댓값을 합한 값) |
| 릿지(Ridge) | - 가중치들의 제곱 합을 최소화하는 것을 추가적인 제약조건으로 하는 방법 - L2 노름 규제를 통해 제약을 주는 방법 (두 점 간 차를 제곱하여 모두 더 한 값의 양의 제곱근한 값) |
| 엘라스틱 넷(Elastic Net) | - 가중치의 절댓값의 합과 제곱 합을 동시에 추가적인 제약조건으로 하는 방법 - 라쏘와 릿지 두 개를 선형 결합한 방법 |
| SelectFromModel | - 의사결정나무 기반 알고리즘에서 변수를 선택하는 방법 |
★ 파생변수(Derived Variance) 생성 방법에 대한 설명으로 옳지 않은 것은?
1. 주어진 변수의 단위를 변환하여 새로운 단위로 표현
2. 단순한 표현 방법으로 변환
3. 소수의 데이터를 복제한 변수
4. 다양한 함수 등 수학적 결합을 통해 새로운 변수를 정의
[파생변수 생성 방법]
| 단위 변환 | 주어진 변수의 단위 혹은 척도를 변환하여 새로운 단위로 표현하는 방법 |
| 표현 형식 변환 | 단순한 표현 방법으로 변환하는 방법 |
| 요약 통계량 변환 | 요약 통계량 등을 활용하여 생성하는 방법 |
| 정보 추출 | 하나의 변수에서 정보를 추출해서 새로운 변수를 생성 |
| 변수 결합 | - 다양한 함수 등 수학적 결합을 통해 새로운 변수를 정의 - 한 레코드의 값을 결합하여 파생변수 생성 |
| 조건문 이용 | 조건문을 이용해서 파생변수를 생성하는 방법 |
★ 다음 중 박스-콕스 변환에 대한 설명으로 올바르지 않은 것은?
1. λ = 0 일때 멱 변환, λ ≠ 0 일 때 로그 변환 하는 기법 ▶λ = 0 일때 로그 변환, λ ≠ 0 일 때 멱 변환 하는 기법
2. 종속변수를 정규분포에 가깝게 만들기 위한 목적으로 사용하는 변환 방법
3. 로그 변환 포함
4. 제곱 루트 변환 포함
▶ 박스-콕스 변환은 정규성 가정이 성립한다고 보기 어려울 경우에 종속변수를 정규분포에 가깝게 변환시키기 위하여 사용하는 기법
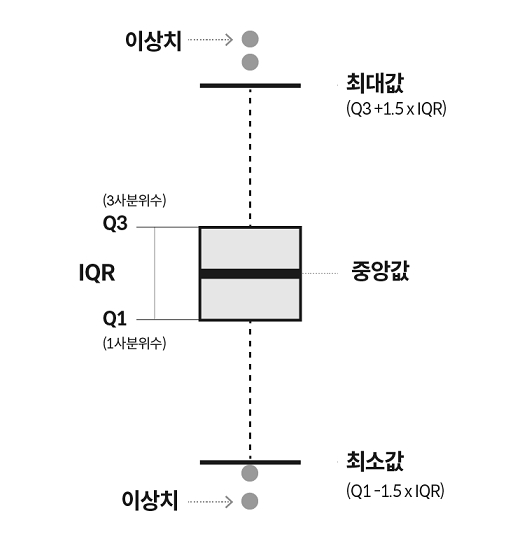
★ 시각적 데이터 탐색에서 자주 사용되는 박스플롯으로 알 수 없는 통계량은?
1. 평균
2. 분산
3. 이상값
4. 최대값
▶평균과 분산은 박스플롯으로 파악 불가
★ 다음 중 박스플롯에 대한 설명으로 가장 알맞지 않은 것은?
1. 많은 데이터를 그림을 이용하여 집합의 범위와 중위수 빠르게 확인 가능
2. 수염은 제1 사분위에서 1.5IQR을 뺀 위치 ▶ 수염은 Q1, Q3으로부터 IQR의 1.5배 내에 있는 가장 멀리 떨어진 데이터까지 이어진 선
3. 통게적으로 이상값이 있는지 빠르게 확인 가능
4. 상자 수염 그림이라고도 함
▶ 제1 사분위에서 1.5IQR을 뺀 위치는 하위 경계라고 함.
[박스플롯]
- 많은 데이터를 그림을 이용하여 집합의 범위와 중위수를 빠르게 확인 가능
- 통계적으로 이상값이 있는지 빠르게 확인 가능
- 상자수염 그림, 상자 그림 등 다양한 이름으로 불림
★ 다음 중 변수 유형의 관계가 잘못 짝지어진 것은?
1. 인과관계 - 독립변수, 종속변수
2. 변수 속성 - 범주형, 수치형
3. 범주형 - 등간형, 비율형
4. 수치형 - 이산형, 연속형
| 인과관계 | 독립변수, 종속변수 | |
| 변수 속성 | 범주형 | 명목형, 순서형 |
| 수치형 | 이산형, 연속형 | |
★ 데이터 탐색에서 개별 변수에 대한 탐색 방법의 설명으로 가장 옳지 않은 것은?
1. 질적 데이터는 명목 척도와 순위 척도에 대하여 데이터 탐색
2. 수치형 데이터는 빈도수, 최빈율, 비율, 백분율 등을 이용하여 데이터의 분포 특성을 중심성, 변동성, 정규성 측면에서 파악
3. 범주형 데이터의 시각화는 막대형 그래프를 주로 이용
4. 수치형 데이터의 시각화는 박스플롯이나 히스토그램을 주로 이용
▶ 개별 변수에 대한 탐색은 범주형, 수치형일 경우로 나누어 탐색
범주형 데이터는 빈도수, 최빈율, 비율, 백분율 등을 이용하여 데이터의 분포 특성을 중심성, 변동성, 정규성 측면에서 파악
★ 데이터 탐색에서 수치형-수치형 데이터 조합에 대한 탐색 방법의 설명으로 옳지 않은 것은?
1. 수치형 데이터 간에는 산점도와 기울기를 통하여 변수 간의 상관성 분석
2. 수치형 변수 간의 상관성과 추세성 여부는 산점도를 이용하여 시각화
3. 공분산을 통하여 방향성과 강도 파악 ▶ 공분산 통하여 강도 파악 불가
4. 피어슨 상관계수를 통하여 상관성 파악
★ 아래 주어진 데이터의 중위수는?
| 6, 7, 9, 15, 13, 20, 45, 15 |
[풀이]
1) 데이터를 오름차순으로 정렬 : 6, 7, 9, 13, 15, 15, 20, 45
2) 데이터의 개수가 짝수 (8개) 이므로, 8/2와 (8+2)/2번째 값의 평균을 구함 ▶ 8/2=4, (8+2)/2 = 5
3) 4번째 (13)와 5번째 (15)의 평균은 (13+15)/2 = 14
답은 14
★ 아래 주어진 데이터의 사분위수는?
| 1, 5, 8, 9, 13, 17, 19 |
[풀이]
1) 자료들을 오름차순으로 정렬: 이미 정렬 되어있음
2) 자료들의 중위수 구함: 데이터의 개수가 홀수 (7개) 이므로, (7+1)/2 = 4번째 (9)
3) 좌측 중위수, 우측 중위수 구함: 좌측 (1, 5, 8) 중 가운데 숫자인 5 / 우측 (13, 17, 19) 중 가운데 숫자인 17
4) IQR(사분위수): Q3 - Q1 = 17 - 5 = 12
★ 아래는 k고등학교 3학년 5반 5명의 키를 나타낸 것이다. 아래 5명의 키에 대한 평균, 중위수, 분산 값은?
| 170, 165, 180, 185, 175 |
[풀이]
1) 평균: (175+165+180+185+175)/5 = 175
2) 중위수: 해당 값을 오름차순으로 정렬하면 165, 170, 175, 180, 185 이며, 이 중 중위수는 175
3) 분산: (값-평균)^2 / n = {(165-175)^2 + (170-175)^2 + (175-175)^2 + (180-175)^2 + (185-175)^2} / 5 = 50
★ 다음 중 산포도 통계량으로 가장 알맞지 않은 것은?
1. 평균값 ▶ 평균값은 중심 경향성을 나타내는 통계량
2. 분산
3, 표준편차
4. 변동계수
★ 다음 중 분산에 대한 설명으로 가장 올바르지 않은 것은?
1. 평균으로부터 얼마나 떨어져 있는지를 나타내는 지표
2. 분산에는 표본의 분산, 모분산이 있음
3. 표본의 분산은 편차의 제곱을 한 값의 합을 구하고 n개로 나눈 값
4. 모집단에 대한 분산은 σ^2(제곱) 으로 표시
▶ 표본의 분산은 (n-1)개로 나눈다.
★ 평균이 100이고 분산이 25일 경우 변동계수 (Coefficient of Variation)은?
[풀이]
변동계수 (CV) = 표준편차 / 평균
문제에 분산으로 데이터가 주어졌으므로 표준편차로 반환하면 5 (분산의 루트값 = 표준편차)
따라서, 변동계수 = 5/100 = 0.05

s는 표준편차, n은 자료의 개수, xi는 i번째 자료, xˉ는 자료의 평균 (분산의 루트 값 = 표준 편차)
[표본표준편차]
- 표준편차는 분산의 양(+)의 제곱근의 값
- 분산은 편차의 제곱을 했기 때문에 원래의 수학적 단위와 차이가 발생하므로 제곱근을 취한 값을 표준편차로 함
- 표준편차를 통하여 평균에서 흩어진 정도를 나타냄
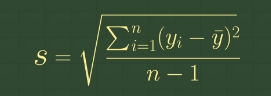
[중심 경향성의 통계량]
| 통계량 | 설명 |
| 평균값(Mean) | 자료를 모두 더한 후 자료 개수로 나눈 값 |
| 중위수(Median) | 모든 데이터값을 순서대로 배열하였을 때 중앙에 위치한 데이터 값 |
| 최빈수(Mode) | 데이터값 중에서 빈도수가 가장 높은 데이터 값 |
| 사분위수(Quartile) | 모든 데이터값을 순서대로 배열하였을 때 4등분한 지점에 있는 값 |
| 백분위수(Percentile) | 모든 데이터값을 순서대로 배열하였을 때 100등분한 지점에 있는 값 |
[산포도 통계량]
※ 산포도: 데이터의 흩어진 정도
| 통계량 | 설명 |
| 분산(Variance) | 평균으로부터 얼마나 떨어져 있는지를 나타내는 값 |
| 표준편차 (Standard Deviation) | 분산에 양의 제곱근을 취한 값 |
| 범위(Range) | 데이터값 중에서 최댓값과 최솟값의 차 |
| IQR(InterQuartile Range) | 3사분위수와 1사분위수의 차이 값 |
| 사분편차 (Quartile Deviation) | 3사분위수와 1사분위수 차이인 IQR의 절반 값 |
| 변동계수 (Coefficient of Variation) | 표준편차를 평균으로 나눈 값 |
[분포 통계량]
왜도와 첨도로 데이터의 분포 파악
※ 왜도: 데이터의 분포가 좌-우로 치우친 정도
※ 첨도: 정규분포보다 뾰족한 정도
★ 다음 중 도수분포표를 가로축에 계급, 세로축에 도수로 사상하여 나타낸 그래프로 가장 알맞은 것은?
1. 막대그래프 ▶ 범주별 빈도를 요약해서 나타낸 그래프
2. 파레토 차트 ▶ 자료들이 어떤 범주에 속하는지를 나타내는 계수형 자료일 때 각 범주에 대한 빈도를 막대의 높이로 나타낸 차트
3. 히스토그램 ▶ 연속형 자료에 대한 도수분포표를 시각화한 그래프
4. 산점도 ▶ 관측된 자료를 직교 좌표계로 이용하여 두 변수 간의 관계를 나타내는 방법
★ 평균에 대한 설명으로 옳은 것은?
1. 제2 사분위수 (Q2) 와 같다 ▶ 중위수
2. 왜도가 0보다 클 때 평균은 중위수보다 작다 ▶ 왜도 > 0 일 때, 최빈수 < 중위수 < 평균
3. 평균과 관측치의 단위는 같다
4. 데이터값 중에서 빈도수가 가장 높은 데이터값이다. ▶ 최빈수
★ 다음 중 성격이 다른 지표는?
1. 평균
2. 범위
3. 중위수
4. 최빈수
| 대표값 | 평균값, 중위수, 최빈수, 사분위수 |
| 산포도 | 분산, 표준편차, 범위, IQR, 사분편차 |
★ 상관관계에 대한 설명으로 옳은 것은?
1. 범주형 값이어야 하고, -1 ~ 1의 값을 가짐 ▶ 상관관계는 수치형 데이터도 가능
2. 명목적 데이터 상관관계를 분석할 때는 피어슨 상관계수 이용 ▶ 명목적 데이터일 경우에는 카이제곱 검정
3. 상관계수의 절대값이 작을수록 강한 상관관계 가짐 ▶ 절대값이 클수록 강한 상관관계
4. 상관계수가 -1에 가까울수록 강한 음의 상관관계 가짐
★ 두 변수 간에 직선 관계가 있는지를 나타낼 때 가장 적절한 통계량은?
1. F-통계량
2. T-통계량
3. p-값
4. 표본상관계수
★ 오른쪽으로 꼬리가 길 때, 피어슨 왜도 계수와 평균, 중위값, 최빈수의 관계는?
1. 피어슨 왜도 계수 > 0, 평균 > 중위값 > 최빈수
2. 피어슨 왜도 계수 = 0, 평균 > 중위값 > 최빈수
3. 피어슨 왜도 계수 < 0, 평균 > 중위값 > 최빈수
4. 피어슨 왜도 계수 < 0, 평균 < 중위값 < 최빈수
▶ 왼쪽으로 꼬리가 길면, 왜도 < 0, 평균 < 중위값 < 최빈수
★ 왜도가 왼쪽 편포일 경우 왜도의 값의 범위는?
▶ 왜도 < 0
★ 왜도의 값이 0보다 클 경우 평균과 최빈수, 중위수 중에서 가장 작은 값은?
최빈수
▶ 왜도 > 0 일 때 (오른쪽으로 꼬리가 길 때), 평균 > 중위값 > 최빈수
왜도 < 0 일 때 (왼쪽으로 꼬리가 길 때), 평균 < 중위값 < 최빈수
왜도 = 0 일 때 (좌우대칭 일 때), 평균 = 중위값 = 최빈수
★ 상관 계수에 대한 설명으로 옳지 않은 것은?
1. 상관계수는 -1에서 1 사이의 값 가짐
2. 상관계수는 0에 가까우면 선형 관계 희미
3. 상관계수만으로 통계적 유의성을 알 수 있음 ▶ 알 수 없음
4. 산점도를 통해 상관 정도 파악 가능
▶ 상관계수는 두 변수 사이의 연관성을 수치상으로 객관화하여 두 변수 사이의 방향성과 강도를 표현하는 방법
( -1에서 1 사이의 값 가짐)
★ 상관 분석에 대한 설명으로 가장 올바르지 않은 것은?
1. 상관 분석은 변수 간의 연관성을 파악하기 위해 사용하는 분석기법 중 하나로 변수 간의 선형 관계 정도를 분석하는 통계기법
2. 상관 분석은 종속변수에 미치는 영향력의 크기를 파악하여 독립변수의 특정한 값에 대응하는 종속 변수값을 에측하는 선형모형을 산출하는 방법 ▶ 회귀분석에 대한 설명
3. 등간 척도 및 비율척도로 측정된 변수 간의 상관계수는 피어슨 상관계수로 측정
4. 서열 척도로 측정된 변수 간의 상관계수는 스피어만 상관계수로 측정
★ 아래는 특정 제품의 sales와 TV, Radio, Newspaper 광고 예산 간의 피어슨 상관계수 행렬이다. 설명이 알맞지 않은 것은?
| TV | Radio | Newspaper | Sales | |
| TV | 1.000 | 0.054 | 0.057 | 0.793 |
| Radio | 0.054 | 1.000 | 0.333 | 0.543 |
| Newspaper | 0.057 | 0.333 | 1.000 | 0.222 |
| Sales | 0.793 | 0.543 | 0.222 | 1.000 |
1. 3가지 매체의 광고예산은 Sales 와 양의 상관관계를 가짐
2. Newspaper 광고예산이 증가할 때 Radio 광고예산이 증가하는 경향
3. TV 광고예산을 늘릴 경우 Sales 가 증가하는 인과관계 가짐 ▶인과 관계는 상관 분석으로 알 수 없음
4. Sales 와 가장 상관관계가 높은 변수는 TV
▶ 상관관계 분석 값 (r) 을 구하여 그 수치가 갖는 의미 파악. r 값의 최대값은 1이고, 1에 가까워질 수록 두 변수가 갖는 관계가 매우 깊다. (상관계수는 -1 이상, 1 이하의 값 가짐)
[상관관계 분석]
(1) 개념
- 두 개 이상의 변수 사이에 존재하는 상호 연관성의 존재 여부와 연관성의 강도를 측정하여 분석하는 방법
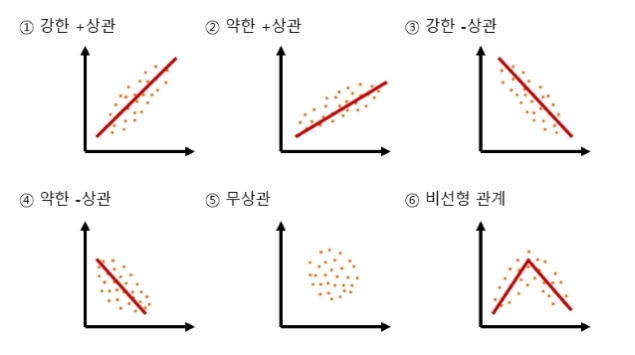
(2) 변수 사이의 상관관계 종류
| 종류 | 설명 |
| 양(+)의 상관관계 | - 한 변수의 값이 증가할 때 다른 변수의 값도 증가하는 경향을 보이는 상관관계 - 강도에 따라 강한 양의 상관관계, 약한 양의 상관관계 |
| 음(-)의 상관관계 | - 한 변수의 값이 증가할 때 다른 변수의 값은 반대로 감소하는 경향을 보이는 상관관계 - 강도에 다라 강한 음의 상관관계, 약한 음의 상관관계 |
| 상관관계 없음 | - 한 변수의 값의 변화에 무관하게 다른 변수의 값이 변하는 상관관계 |
(3) 표현 방법
산점도를 이용한 표현 방법
- 변수 사이의 관계를 산점도 그래프를 통하여 표현하는 방법
- 산점도는 직교 좌표계를 이용해 두 개 변수 간의 관계를 나타내는 방법
- 관계 시각화 기법에 해당
| +0.7 ~ +1.0 | 강한 양의 선형관계 |
| +0.3 ~ +0.7 | 뚜렷한 양의 선형관계 |
| +0.1 ~ +0.3 | 약한 양의 선형관계 |
| -0.1 ~ +0.1 | 거의 무시될 수 있는 선형관계 |
| -0.3 ~ -0.1 | 약한 음의 상관관계 |
| -0.7 ~ -0.3 | 뚜렷한 음의 상관관계 |
| -1.0 ~ -0.7 | 강한 음의 상관관계 |
★ 다음 중 3사분위수보다 항상 작은 값은?
1. 평균
2. 상위 80%에 위치한 값
3. 중위수
4. 최대값
▶ 상위 50%에 위치한 중위수는 3사분위수(상위 75%)에 위치한 값보다 작다
★ 다음 중에서 확률 및 확률분포에 대한 설명 중 가장 적절하지 못한 것은?
1. 확률변수 x가 구간 또는 구간들의 모임인 숫자 값을 갖는 확률분포 함수를 이산형 확률 질량 함수라 한다
2. 모든 확률변수는 0과 1 사이의 값을 가진다
3. 확률함수는 확률변수에 의해 정의된 실수를 확률에 대응시키는 함수이다
4. 서로 배반인 사건에 대한 합집합의 확률을 각 사건에 대한 확률의 합이 된다
▶ 확률변수 x가 구간 또는 구간들의 모임인 숫자 값을 갖는 확률분포 함수는 연속형 확률 밀도 함수
★ 평균이 100 이고 분산이 16인 정규 모집단에서 크기가 4인 표본을 추출하였을 경우 표본 평균의 표준편차는?
[풀이]
1) 표본 평균의 표준편차는 표준오차
2) n=4, σ = √ ̄16 = 4 이므로,
3) 표준 오차는 σ/ √ ̄n = 4/ √ ̄4 = 2
★ 평균 키가 173cm, 표준편차가 16인 고등학교 남학생 중에서 임의로 추출한 고등학교 남학생 100명의 평균키의 표준오차는?
[풀이]
1) σ/ √ ̄n = 16/ √ ̄100
2) 16/10 = 1.6
★ 정규분포에 대한 섦영으로 옳지 않은 것은?
1. 정규분포를 나타내기 위해 평균과 분산 사용
2. 분포 형태가 종 모양
3. 왜도는 3이고, 첨도는 0
4. 표준정규분포는 평균이 0, 표준편차가 1
▶ 정규분포는 좌우 대칭의 특성을 갖는 분포. 왜도가 0이 아닌 값이면 좌우 대칭이 되지 않음.
★ 초기하분포에 대한 설명으로 옳지 않은 것은?
1. 초기하분포는 특정 그룹에서 뽑힌 표본의 수에 대한 확률 분포이다
2. 초기하분포는 시행마다 성공 확률이 일정하지 않다
3. 초기하분포는 시행은 독립적이다 ▶ 초기하분포는 비복원 추출로 성공 확률이 일정하지 않기 때문에 각각의 시행은 독립적이지 않음.
4. 초기하분포는 이산확률분포를 가진다
▶ n번의 시행 중 각각의 시행이 독립적인 것은 이항분포
※ 초기하분포: 비복원추출에서 N개 중에 r개가 특정 그룹이고, n번 추출했을 때 특정 그룹에서 x개가 뽑힐 확률의 분포
★ 다음 중 확률분포 및 확률변수에 대한 설명으로 잘못된 것은?
1. 이산확률변수는 셀 수 있는 값들을 변수로 갖는 확률 변수
2. 이항분포는 이산확률분포
3. 연속확률분포에는 초기하분포, 지수분포, 감마분포 등
4. 정규분포는 연속확률분포
| 이산확률분포 | - 이산확률변수 X가 가지는 확률분포 - 확률변수 X가 0,1,2,3,... 같이 하나씩 셀 수 있는 값 취함 | 포아송분포, 베르누이분포, 이항분포, 초기하분포 |
| 연속확률분포 | - 확률변수 X가 실수와 같이 연속적인 값을 취할 때 이를 연속확률변수라 하고, 이러한 연속확률변수 X가 가지는 확률분포 | 정규분포, 감마분포, 지수분포, 카이제곱분포 |
★ 베르누이 시행에 대한 설명으로 옳지 않은 것은?
1. 특정 실험의 결과가 성공 또는 실패로 두 가지의 결과 중 하나를 얻는 분포
2. 확률 P는 p이다
3. 기대값 E(X)는 p^2이다 ▶ 기대값 E(X)는 p이다
4. 분산은 p(1-p) 이다
★ 복원 추출 했을 때 표본 추출에 대한 설명으로 옳지 않은 것은?
1. 표본의 개수가 많아지면 표본오차가 줄어듦
2. 표본의 크기가 커질수록 정규분포 따름
3. 복원 추출에 의해 추출한 데이터는 크기가 커져도 중심 극한 정리는 성립 하지 않음 ▶ 중심 극한 정리에 의해 데이터의 크기가 커지면 최종적으로 정규분포 따름
4. 표본의 크기가 증가할수록 표본의 평균과 표준편차가 모집단의 평균과 표준편차에 가까워짐
★ 다음 중 층화추출에 대한 설명으로 가장 올바르지 않은 것은?
1. 모집단을 여러 계층으로 나누고, 계층별로 무작위 추출을 수행하는 방식
2. 모집단을 일정한 간격으로 추출하는 방식 ▶ 계통 추출
3. 층내는 동질적, 층간은 이질적
4. 사례로 지역별 여론 조사를 위해 조사 지역을 도별로 나누고, 각 도에서 무작위로 100명씩 선발
★ 다음 중 층화 추출법에 대한 설명으로 올바르지 않은 것은?
1. 모집단의 각 게층에 대한 정확한 정보 필요
2. 각 계층으로부터 표본 추출
3. 각 계층은 내부적으로 이질적, 외부적으로는 동질적 ▶층화 추출의 각 계층은 내부적(층내)으로 동질적, 외부적(층간)으로는 이질적
4. 확률 표본 추출 방법
▶ 층화 추출법은 모집단을 동질적인 여러 개의 계층으로 나눈 후, 각 계층으로부터 표본을 추출하는 확룔 표본 방법으로 모집단의 각 계층에 대한 정확한 정보 필요
★ 확률 변수 X의 분산은 2이고, 확률변수 Y = 2 + 5 X 일 때, 확률변수 Y의 분산은?
▶ V(ax+b) = a^2V(x) → a: 5, V(x): 2 = 5^2 * 2 = 50
★ 확률 변수 X의 기대값은 2이고, 확률변수 Y= 3 + 2 X 일 때, 확률변수 Y의 기대값은?
▶ Y = 3 + 2X → X: 2 = 3 + 2*2 = 7
★ 육면체 주사위 한 개를 한 번 던졌을 때, 윗면에 나타난 수를 X라고 할 경우, X의 기대값은?
[풀이]
| X | 1 | 2 | 3 | 4 | 5 | 6 |
| 확률 P(X) | 1/6 | 1/6 | 1/6 | 1/6 | 1/6 | 1/6 |
▶ (1*1/6) + (2*1/6) + (3*1/6) + (4*1/6) + (5*1/6) + (6*1/6)
= 3.5
★ 확률변수 X와 확률 질량 함수 P(X)가 다음과 같이 주어질 때, 확률변수 X의 분산은?
| X | 1 | 2 | 3 | 4 |
| 확률 P(X) | 1/6 | 1/6 | 1/6 | 3/6 |
▶ V(X) = E(X^2) - [E(X)^2]
E(X) = (1*1/6) + (2*1/6) + (3*1/6) + (4*3/6) = 3
E(X^2) = (1^2*1/6) + (2^2*1/6) + (3^2*1/6) + (4^2*3/6) = 62/6
V(X) = E(X^2) - [E(X)^2] → 62/6 - 3^2 = 8/6 = 4/3
★ 연속형 확률변수의 분포 중에서 정규분포의 평균을 측정할 때 주로 사용되고 두 집단 간 평균의 차이 검정 등에 활용되는 분포는?
1. F-분포 ▶ 두 표본의 분산을 비교하는 데 많이 이용되는 분포 (F-검정과 분산분석-ANOVA 에서 주로 사용)
2. 카이제곱 분포 ▶ 표준정규분포의 확률변수를 제곱합 한 분포 (신뢰구간, 가설검정, 독립성 검정 등에서 자주 사용)
3. 포아송분포 ▶ 이산형 확률분포 중 주어진 시간 또는 영역에서 어떤 사건의 발생 횟수를 나타내는 확률 분포
4. T-분포
★ 표본 통계량이 표본분산일 때 표본분포로 가장 알맞은 것은?
▶ 카이제곱 분포
★ 독립적인 x^2 분포가 있을 때, 두 확률변수의 비로 가장 알맞은 것은?
▶ F-분포
★ 다음 중 표본의 개수가 커지면 모집단의 분포와 상관 없이 표본분포는 저규분포에 근사한다는 법칙은?
1. 큰 수의 법칙
2. 중심극한정리
3. 전체 확률의 법칙
4. 오차의 법칙 ▶ 가우스가 제시한 3가지 법칙
1) +오차와 -오차가 나올 가능성은 같다
2) 작은 오차가 나올 가능성이 큰 오차가 나올 가능성보다 크다
3) 오차는 2번 미분 가능하고 전체 확률은 1
★ 수집된 자료를 토대로 모집단의 특성을 추정하게 되는데, 이때 조사하는 모집단의 일부를 표본(Sample) 이라 한다. 다음 중 표본조사에 대한 설명으로 가장 올바르지 않은 것은?
1. 비표본오차: 표본오차를 제외한 모든 오차로 조사 과정에서 발생하는 모든 부주의나 실수, 알 수 없는 원인 등의 모든 오차 의미. 조사대상이 증가한다고 하여 오차가 커지지 않음. ▶ 조사대상이 증가하면 오차 커짐
2. 표본오차: 모집단의 일부인 표본에서 얻은 자료를 통해 모집단 전체의 특성을 추론함으로써 생기는 오차
3. 표본편의: 확률화에 의해 최소화 가능. 확률화란 모집단으로부터 편의 되지 않은 표본을 추출하는 절차. 확률화 절차에 의해 추출된 표본은 확률포본
4. 표본 편의: 모수를 작게 또는 크게 할 때 추정하는 것과 같이 표본추출 방법에서 기인하는 오차
★ 점 추정 조건에 대한 설명 중 올바르지 않은 것은?
1. 불편성: 추정량의 기대값이 모집단의 모수와 차이가 없는 특성
2. 효율성: 추정량의 분산이 작은 특성
3. 일치성: 표본의 크기가 커지면 추정량이 모수와 거의 같아지는 특성
4. 편의성: 모수를 추정할 때 복잡한 정도를 나타내는 특성
▶ 점추정 조건에는 불편성, 효율성, 일치성, 충족성이 있음
★ A고등학교 남학생 25명의 키를 측정하였더니 평균 키는 170cm 이고, 분산이 25이다. A고등학교 남학생의 평균 키에 대한 95% 신뢰구간은? (Z0.05 = 1.711, Z0.025 = 2.064) ▶ t-분포표 상 자유도는 25-1: 24, 꼬리확률 q = a/2 = 0.025가 교차하는 지점
[풀이]
1) 표본의 크기가 30보다 작은 소표본 : 자유도가 n-1인 t-분포
2) 표본평균 -x = 170, 표본분산 s^2 = 25, 자유도 = 24(n-1)
3) 95% 신뢰구간 a=0.05, a/2 = 0.025 (Z.0.025 = 2.064)
4) 170 - 2.064 ≤ 키 ≤ 170+2.064
▶ 167.936 ≤ 키 ≤ 172.064
★ 모표준편차 σ = 8인 정규분포를 따르는 모집단에서 표본의 크기가 25인 표본을 추출하였을 때 표본평균(-x)는 90.
모평균 μ에 대한 90% 신뢰구간은? (Z0.05 = 1.645, Z0.1 = 1.282)
[풀이]
1) 정규분포를 따르는 모집단에서 모표준편차가 알려져 있으므로 Z-분포 이용
2) 90% 신뢰구간이므로, a=0.1, a/2= 0.05
3) 90-1.645*8/√ ̄25 ≤ μ ≤ 90+1.645* 8/√ ̄25
4) 90-2.632 ≤ μ ≤ 90+2.632
▶ 87.368 ≤ μ ≤ 92.632
★ 전구를 대량 생산하는 전기회사가 있다. 전구의 평균 수명을 측정하기 위하여 100개의 전구를 표본추출하여 평균 수명을 측정하였더니 600 시간, 표준편차는 20시간이었다. 이 회사에서 생산되는 전구의 평균 수명에 대한 95% 신뢰구간은?
(Z0.025 = 1.96, Z0.05 = 1.645)
[풀이]
1) 표본평균 = 600, 표본의 크기는 = 100
2) 95% 신뢰 구간이므로, a= 0.05, a/2 = 0.025 (1.96), 표준편차 = 20
3) 600 - 1.96 * 20/ √ ̄100 ≤ μ ≤ 600 + 1.96 * 20/ √ ̄100
4) 600 - 3.92 ≤ μ ≤ 600 + 3.92
5) 596.08 ≤ μ ≤ 603.92
★ 동일 집단에 대해 처치 전과 후를 비교할 때 평균 추정에 대한 설명으로 옳은 것은?
1. 처치 전과 후의 평균에 대한 차이를 추정
2. 표본의 크기가 30 이상이면 T-분포를, 30 미만이면 Z-분포 이용
3. 처치 전과 후를 추정할 때 표본표준편차는 표본의 개수와 비례
4. 표본표준편차는 처치 전의 표준편차와 처치 후의 표준편차를 합해서 계산
▶ 표본의 크기가 30 이상(대표본) → Z-분포 / 표본의 크기가 30 미만 (소표본) → T-분포
★ 다음 중 비모수 통계에 대한 설명으로 가장 알맞지 않은 것은?
1. 모집단의 분포에 대한 가정의 불만족으로 인한 오류의 가능성 큼 ▶ 가능성 작음
2. 모수적 방법에 비해 통계량의 계산이 간편하여 직관적으로 이해하기 쉬움
3. 이상값으로 인한 영향이 적음
4. 검정 통계량의 신뢰성 부족
★ 10명의 혈당을 측정하여 측정 전과 측정 후의 짝을 이룬 표본에 대한 비모수 검정으로 가장 알맞은 것은?
1. 윌콕슨 부호 순위 검정
2. 윌콕슨 순위 합 검정
3. T-검정
4. 크수스칼 왈리스 검정
★ 윌콕슨 부호 순위 검정, 윌콕슨 순위 합 검정에 대한 설명으로 올바르지 않은 것은?
1. 윌콕슨 부호 순위 검정은 단일 표본 검정 기법
2. 윌콕슨 순위 합 검정은 이변수 검정 기법
3. 윌콕슨 순위 합 검정은 자료의 분포에 대한 대칭성 가정 필요
4. 윌콕슨 순위 합 검정은 모수 분포를 가정한 방법 ▶ 비모수적 방법
★ 다음 비모수 검정 방법 중에서 관측된 표본이 어떤 패턴이나 경향이 없이 랜덤하게 추출되었다는 가설을 검정하는 방법은?
1. 부호 검정
2. 만-위트니의 U검정
3. 런 검정
4. 윌콕슨 순위 합 검정
★ 동전의 앞을 1, 뒤를 0 으로 하였을 경우 10번 동전을 던졌을 때의 결과는 아래와 같다. 이때 런의 총 횟수는?
| 1, 0, 0, 1, 0, 1, 1, 1, 0, 1 |
▶ 1 / 0 0 / 1/ 0 / 1 1 1 / 0 / 1 → 총 7회
| 단일표본 | 부호 검정 / 윌콕슨 부호 순위 검정 | 단일 표본 T-검정 |
| 두 표본 | 윌콕슨 순위 합 테스트 | 독립 표본 T-검정 |
| 부호 검정 / 윌콕슨 부호 순위 검정 | 대응 표본 T-검정 | |
| 분산 분석 | 크루스칼-왈리스 검정 | ANOVA (분산 분석) |
| 무작위성 | 런 검정 | 없음 |
| 상관 분석 | 스피어만 순위 상관계수 | 피어슨 상관계수 |
[비모수 통계]
- 평균이나 분산 같은 모집단의 분포에 대한 모수성을 가정하지 않고 분석하는 통계적 방법
- 데이터가 모수적 분석 방법이 가정한 특성을 만족하지 못할 때는 비모수 통계분석 방법 사용
- 빈도, 부호, 순위 등의 통계량 사용
- 순위와 부호에 기초한 방법 위주로 이상값으로 인한 영향 적음
- 데이터가 모수적 분석 방법이 가정한 특성을 만족하지 못할 때는 비모수 통계분석 방법 사용
| 장점 | 단점 |
| - 모집단의 분포에 대한 가정의 불만족으로 인한 오류의 가능성 적음 - 모수적 방법에 비해 통계량의 계산이 간편하고 직관적으로 이해하기 쉬움 - 모집단의 분포에 무관하게 사용 - 추출된 샘플의 개수가 10개 미만으로 작을 경우에도 사용 -이상값으로 인한 영향 적음 | - 모수 통계로 검정이 가능한 데이터를 비모수 통계를 이용하면 효율성 저하 - 검정통계량의 신뢰성 부족 - 자료의 수가 많은 경우 모수적 통게에 비해 오히려 계산 절차 복잡 |
■ 비모수 통계 검정 방법의 종류
- 단일 표본: 부호 검정, 월콕슨 부호 순위 검정
- 두 표본: 월콕슨 순위 합 테스트 / 부호 검정, 월콕슨 부호 순위 검정
- 분산분석: 크루스칼-왈리스 검정
- 무작위성: 런 검정
- 상관 분석: 스피어만 순위 상관계수
★ 다음이 설명하는 용어는?
| 모집단에 대한 통계적 가설을 세우고 표본을 추출한 다음, 그 표본을 통해 얻은 정보를 이용하여 통계적 가설의 진위를 판단하는 과정 |
▶ 가설검정
★ 유의 확률에 대한 설명으로 옳은 것은?
1. 유의 확률이 유의 수준보다 크면 H0 을 채택
2. 1종 오류를 범할 최대 허용 확률 ▶ 유의수준
3. 2종 오류를 범할 최대 허용 확률 ▶ 베타 수준
4. 가설검정의 대상이 되는 모수를 추론하기 위해 사용되는 표본 통계량 ▶ 검정량
▶ p-값 (p-Value) = 유의확률, 귀무가설이 참이라는 전제하에 실제 표본에서 구한 표본 통계량의 값보다 더 극단적인 값이 나올 확률
★ 다음 중 추정과 가설검정에 대한 설명으로 가장 알맞지 않은 것은?
1. 구간 추정이란 일정한 크기의 신뢰구간으로 모수가 특정한 구간에 있을 것이라고 추정하는 것으로 구해진 구간을 신뢰구간이라 한다.
2. 점 추정은 표본의 정보로부터 모집단의 모수가 특정한 값일 것이라고 추정하는 것
3. 기각역은 귀무가설을 기각시키는 검정통계량의 범위
4. p-값은 귀무가설이 참이라는 가정에 따라 주어진 표본 데이터를 평균값으로 얻을 확률
▶p-값은 귀무가설이 참이라는 가정에 따라 주어진 표본 데이터를 희소 또는 극한값으로 얻을 확률 값 (유의확률)
| ※ 귀무가설(H0): 현재까지 주장되어 온 것이거나 기존과 비교하여 변화 혹은 차이가 없음을 나타내는 가설 | |
| 귀무가설 채택 | p-값 > 유의수준 |
| 귀무가설 기각 | p-값 < 유의수준 |
| ※ 대립가설(H1): 표본을 통해 확실한 근거를 가지고 입증하고자 하는 가설 (연구가설) | |
★ 제2종 오류를 범할 최대 허용확률을 의미하는 값은?
▶ 베타 수준 (β)
| 유의수준 | 제1종 오류를 범할 최대 허용확률 |
| 신뢰수준 | 귀무가설이 참일 때 이를 참이라고 판단하는 확률 (1-α) |
| 베타 수준 | 제2종 오류를 범할 최대 허용 확률 (β) |
| 검정력 | 귀무가설이 참이 아닌 경우 이를 기각할 수 있는 확률(1- β) |
| 제1종 오류 | 귀무가설이 참인데 잘못하여 이를 기각하게 되는 오류 |
| 제2종 오류 | 귀무가설이 거짓인데 잘못하여 이를 채택하게 되는 오류 |
★ 혈당을 낮추는 약을 개발했을 때 혈당을 낮추는 약이 효과가 있는지 검정을 할 때 사용하는 가설검정은?
1. 단일 모평균의 단측 검정
2. 단일 모평균의 양측 검정
3. 대응 표본(쌍체 표본) 단측 검정 ▶모수에 대해 표본자료를 바탕으로 모수가 특정 값과 통계적으로 큰지 작은지 여부 판단
4. 대응 표본(쌍체 표본) 양측 검정 ▶ 모수에 대해 표본자료를 바탕으로 모수가 특정 값과 통계적으로 같은지 여부 판단
★ 다음 중 아래 사례를 분석할 때 사용할 수 있는 검정 방법은?
| A집단(단일표본)에게 술을 먹였을 때와 안 먹였을 때의 민첩성을 측정(=사전-사후 검사)할 때 사용 |
1. 단일표본 T-검정
2. 대응표본 T-검정
3. 분산표본 T-검정
4. 독립표본 T-검정
▶ 대응표본 T-검정은 동일한 집단의 처치 전후 차이를 알아보기 위해 사용하는 검정 방법 (표본이 하나, 독립변수 1개일 때 사용)
★ 크기가 1000인 표본으로 95% 신뢰수준을 가지도록 모평균을 추정하였는데 신뢰구간의 길이가 10이었다. 동일한 조건에서 크기가 250인 표본으로 95% 신뢰수준을 가지도록 모평균을 추정할 경우에 표본의 길이는?
▶ [풀이] 모평균 추정 시 신뢰구간의 길이는 표준오차에 비례, 표본의 크기의 제곱근에 반비례
1) 표본의 크기: 1000에서 250으로 1/4 감소
2) 신뢰구간의 길이는 표본 크기의 제곱근에 반비례 하므로, √ ̄4 =2 배 증가
3) 신뢰구간의 길이는 10*2 = 20
★ 다음 중 구간 추정 방법과 신뢰구간에 대한 설명으로 올바르지 않은 것은?
1. 일정한 크기의 신뢰수준으로 모수가 특정한 구간에 있을 것이라고 선언하는 것
2. 95% 신뢰구간은 '주어진 한 개의 신뢰구간에 미지의 모수가 포함될 확률이 5%다' 라는 의미
▶ 95% 신뢰구간은 '주어진 한 개의 신뢰구간에 미지의 모수가 포함될 확률이 95%다' 라는 의미
3. 신뢰수준이 높아지면 신뢰구간의 길이는 길어진다
4. 표본의 수가 많아지면 신뢰구간의 길이는 짧아진다
★ 모평균을 추정하는데 표본의 크기를 4배 증가시킬 경우 신뢰구간의 길이 변화는?
▶ 신뢰구간의 길이는 표본의 크기의 제곱근에 반비례
4배 증가시킬 경우, 1/ √ ̄4 배 감소 → 1/2배 감소
★ 크기가 100인 표본으로부터 구한 모평균에 대한 90% 신뢰구간의 오차의 한계가 5라고 한다. 동일한 신뢰구간에서 오차의 한계가 최소 2.5를 넘지 않도록 하려면 표본의 크기가 최소한 얼마 이상이 되어야 하는가?
[풀이]
1) 표본의 크기는 허용 오차(오차의 한계)의 제곱에 반비례
2) 오차의 한계를 1/2 감소시키기 위해서는 표본의 크기는 4배 증가시켜야 함
3) 크기가 100인 표본의 4배인 400 이상이 되어야 함
[통계 공식 관련 도움되는 글]
분산 공식 (중3, 확률과 통계)
평균과 분산, 표준편차에 대한 내용은 중학교 3학년 2학기 과정에서 처음 배웁니다. 중3 과정의 기초적인 ...
blog.naver.com
[내용 정리]
[빅데이터 분석기사] 2과목 빅데이터 탐색(1-1)
[목차] [빅데이터 분석기사] 시험 과목 및 주요 내용 (필기) 빅데이터 분석기사 (필기) 시험 과목 및 주요 내용 출처: 데이터자격검정 (dataq.or.kr) 필기과목명 주요항목 세부항목 세세항목 빅데이터
puppy-foot-it.tistory.com
[빅데이터 분석기사] 2과목 빅데이터 탐색(1-2)
[목차] [빅데이터 분석기사] 시험 과목 및 주요 내용 (필기) 빅데이터 분석기사 (필기) 시험 과목 및 주요 내용 출처: 데이터자격검정 (dataq.or.kr) 필기과목명 주요항목 세부항목 세세항목 빅데이터
puppy-foot-it.tistory.com
[빅데이터 분석기사] 2과목 빅데이터 탐색(2-1-1)
[목차] [빅데이터 분석기사] 시험 과목 및 주요 내용 (필기) 빅데이터 분석기사 (필기) 시험 과목 및 주요 내용 출처: 데이터자격검정 (dataq.or.kr) 필기과목명 주요항목 세부항목 세세항목 빅데이터
puppy-foot-it.tistory.com
[빅데이터 분석기사] 2과목 빅데이터 탐색(2-1-2)
[목차] [빅데이터 분석기사] 시험 과목 및 주요 내용 (필기) 빅데이터 분석기사 (필기) 시험 과목 및 주요 내용 출처: 데이터자격검정 (dataq.or.kr) 필기과목명 주요항목 세부항목 세세항목 빅데이터
puppy-foot-it.tistory.com
[빅데이터 분석기사] 2과목 빅데이터 탐색(2-2-1)
[목차] [빅데이터 분석기사] 시험 과목 및 주요 내용 (필기) 빅데이터 분석기사 (필기) 시험 과목 및 주요 내용 출처: 데이터자격검정 (dataq.or.kr) 필기과목명 주요항목 세부항목 세세항목 빅데이터
puppy-foot-it.tistory.com
[빅데이터 분석기사] 2과목 빅데이터 탐색(2-2-2)
[목차] [빅데이터 분석기사] 시험 과목 및 주요 내용 (필기) 빅데이터 분석기사 (필기) 시험 과목 및 주요 내용 출처: 데이터자격검정 (dataq.or.kr) 필기과목명 주요항목 세부항목 세세항목 빅데이터
puppy-foot-it.tistory.com
'자격증 > 빅데이터분석기사' 카테고리의 다른 글
| [빅데이터 분석기사] 1과목 기출 문제 (1) | 2024.03.29 |
|---|---|
| [빅데이터 분석기사] 3과목 기출문제 오답노트 (1) | 2024.03.24 |
| [빅데이터 분석기사] 4과목 기출문제 오답노트 (0) | 2024.03.19 |
| [빅데이터 분석기사] 1과목 기출 문제 오답노트 (0) | 2024.03.16 |
| [빅데이터 분석기사] 4과목 빅데이터 결과 해석(2) (0) | 2024.03.16 |

