★ 다음 중 진단 분석에 대한 설명으로 가장 적합한 것은?
1. 과거에 어떤 일이 일어났고 현재는 무슨 일이 일어나고 있는지?
2. 데이터를 기반으로 왜 발생했는지?
3. 무슨 일이 일어날 것인지?
4. 어떤 대응을 해야 하는지?
▶ 진단 분석은 데이터를 기반으로 왜 발생했는지 이유를 확인하는 분석
(가트너의 분석 가치 에스컬레이터)
묘사 분석 - 진단 분석 - 예측 분석 - 처방 분석
★ 다음 중 머신러닝, 빅데이터 분석으로 미래 혹은 알려지지 않은 결과를 분석하는 기법으로 가장 알맞은 것은?
1. Prescriptive Analytics
2. Predictive Analytics
3. Descriptive Analytics
4. Diagnostic Analytics
▶
- 묘사분석 ( Descriptive Analytics): 분석의 가장 기본적인 지표 확인 단계. 과거에 무슨 일이 일어났고, 현재는 무슨 일이 일어나고 있는가?
- 진단 분석(Diagnostic Analytics): 데이터를 기반으로 왜 발생했는지 이유 확인
- 처방 분석(Prescriptive Analytics): 예측을 바탕으로 최적화 (무엇을 해야 할 것인지 확인)
★ 1제타바이트에 1 byte 에 아스키코드를 넣을 수 있는 수의 크기는?
1. 2의 10승
2. 2의 30승
3. 2의 50승
4. 2의 70승
▶

★ 다음 중 지식에 대한 예시로 가장 적절한 것은?
1. B 사이트의 USB 판매 가격이 A 사이트 보다 더 비싸다 (정보)
2. A 사이트는 1,000원에 B 사이트는 1,200원에 USB를 팔고 있다 (데이터)
3. B 사이트보다 가격이 상대적으로 저렴한 A 사이트에서 USB를 사야겠다.
4. A 사이트가 B 사이트 보다 다른 물건도 싸게 팔 것이다. (지혜)
★ 다음 중 사분면 분석 결과 중 기업에서 활용하는 분석 업무, 기법 등은 부족하지만 적용조직 등 준비도가 높아서 바로 도입할 수 있는 기업에 해당하는 유형은?
1. 정착형
2. 확산형
3. 준비형
4. 도입형
▶ 정착형: 준비도 낮음 / 성숙도 높음
확산형: 준비도 높음 / 성숙도 높음
준비형: 준비도 낮음 / 성숙도 낮음
도입형: 준비도 높음 / 성숙도 낮음
※ 준비도: 적용조직 등
※ 성숙도: 기업에서 활용하는 분석 업무, 기법 등
★ 조직 평가 위한 성숙도 단계는?
▶ 도입 단계 → 활용 단계 → 확산 단계 → 최적화 단계
★ 다음 중 빅데이터 시대에서 발생할 수 있는 '책임 원칙의 훼손' 에 대해 가장 올바른 사례는?
1. 범죄 예측 프로그램에 의해 범행이 발생하기 전 체포
2. 빅브라더가 개인의 일상을 전체적으로 감시
3. 여행 사실을 SNS에 올린 사람의 집에 강도 침입
4. 검색엔진의 차별적인 누락으로 매출액 감소
▶ 예측 기술과 빅데이터 분석기술이 발달하면서 분석 대상이 되는 사람들이 예측 알고리즘의 희생양이 될 가능성 존재
★ 목적 외로 활용된 개인정보가 포함된 데이터가 사생활 침해를 넘어 사회와 경제적 위협으로 확대되고 있다. 이에 대한 통제 방안으로 가장 옳은 것은?
1. '알고리즘에 대한 접근권' 을 통해 통제 (데이터 오용)
2. 알고리즈미스트라는 전문가를 통해 사생활 침해에 대해 통제 (데이터 오용)
3. 기존의 원칙 보강 및 강화와 예측 자료에 의한 불이익 가능성을 최소화하는 장치 마련 필요 (책임 원칙 훼손)
4. 개인정보를 사용하는 사용자의 '책임'을 통해 해결하는 방안 강구
★ 2018년 5월 25일부터 시행되는 EU의 개인정보보호 법령으로, 정보 주체의 권리와 기업의 책임성 강화, 개인정보의 EU 역외이전 요건 명확화 등을 주요 내용으로 하는 용어는?
▶ GDPR (General Data Protection Regulation)
★ 다음 중 개인정보에 대한 설명으로 가장 올바르지 않은 것은?
1. 개인정보는 개인을 알아볼 수 있는 정보
2. 단체, 기업에 대한 정보는 개인정보가 아님
3. 데이터 3법 개정을 통해 주소, 전화번호, 이메일 주소 등의 개인정보를 가명처리하여 통계 작성에 활용 시에 개인의 동의 필요 ▶ 개인의 동의 없이 통계 작성에 활용 가능
4. 개인정보의 처리 목적에 필요한 범위에서 최소한의 개인정보만을 적법하고 정당하게 수집할 수 있고 개인의 동의가 없어도 수집 목적의 범위에 이용 가능
★ 개인정보보호 관련 법령으로 가장 거리가 먼 것은?
1. 개인정보 보호법
2. 전자금융 거래법
3. 정보통신망법
4. 신용정보법
▶ 개인정보보호 관련 법령: 개인정보 보호법 / 정보통신망법 / 신용정보법 / 위치정보 보호법
★ 개인정보의 수집-이용을 위해 정보 주체의 동의를 받을 때 고지사항이 아닌 것은?
1. 개인정보의 수집-이용 목적
2. 수집하려는 개인정보의 항목
3. 개인정보를 제공받는 자
4. 개인정보의 보유 및 이용 기간
★ 다음 중 개인정보를 수집할 수 없는 경우는?
1. 법률에 특별한 규정이 있거나 법령상 의무를 준수하기 위하여 불가피한 경우
2. 정보 주체와의 계약을 체결할 경우
3. 정보 주체 또는 그 법정대리인이 의사표시를 할 수 없는 상태에 있거나 주소불명 등으로 사전 동의를 받을 수 없는 경우
4. 제3자의 급박한 생명, 신체, 재산의 이익을 위하여 필요하다고 인정되는 경우
▶ 정보 주체와의 계약 체결 시 '불가피 하게 필요한 경우'에는 개인정보 수집 가능
★ 쏠림 공격, 유사성 공격을 보완하기 위해 제안된 프라이버시 보호 모델은?
▶ t- 근접성
동질 집합에서 특정 정보의 분포와 전체 데이터 집합에서 정보의 분포가 t 이하의 차이를 보여야 하는 모델
※ k-익명성: 주어진 데이터 집합에서 같은 값이 적어도 k개 이상 존재하도록 하여 쉽게 다른 정보로 결합할 수 없게 하는 모델
(공개된 데이터에 대한 연결 공격 취약점 방어)
※ l-다양성: 주어진 데이터 집합에서 함께 비식별 되는 레코드들은 적어도 l개의 서로 다른 민감한 정보를 가져야 하는 모델
(동질성 공격, 배경지식에 의한 공격 방어)
※ m-유일성: 원본 데이터와 동일한 속성 값의 조합이 비식별 결과 데이터에 최소 m개 이상 존재하도록 함
(재식별 가능성 위험 낮춤)
★ 가명 정보에 대한 설명으로 옳지 않은 것은?
1. 추가정보의 사용 없이는 특정 개인을 알아볼 수 없게 조치한 정보
2. 더 이상 개인을 알아볼 수 없게 복원 불가능한 정도로 조치한 정보
3. 통계작성을 위해 동의 없이 사용 가능 (상업적 목적 포함)
4. 공익적 기록보존 목적을 위해 동의 없이 사용 가능
▶ 2번은 익명 정보
★ 다음 중 동일한 확률적 정보를 가지는 변형된 값에 대하여 원래 데이터를 대처하는 기법은?
1. 가명
2. 일반화
3. 치환
4 섭동
▶
| 가명 (Pseudonym) |
개인 식별이 가능한 데이터에 대하여 직접 식별 할 수 없는 다른 값으로 대체하는 기법 |
| 일반화 (Generalization) |
더 일반화된 값으로 대체하는 것 숫자 데이터 ▶ 구간 범주화된 속성 ▶ 트리의 계층적 구조에 의해 대체 |
| 섭동 (Perturbation) |
동일한 확률적 정보를 가지는 변형된 값에 대하여 원래 데이터를 대체하는 기법 |
| 치환 (Permutation) |
속성 값을 수정하지 않고 레코드 간에 속성 값의 위치를 바꾸는 기법 |
★ 다음 중 빅데이터 분석 기획 단계에서 수행해야 하는 작업은?
1. 프로젝트 진행을 위해 비즈니스에 대한 충분한 이해와 도메인 이슈 도출
2. 정형/비정형/반정형 등의 모든 내/외부 데이터와 데이터 속성, 오너, 담당자 등을 포함하는 데이터 정의서 작성
3. 비즈니스 룰을 확인하여 분석용 데이터 셋을 준비
4. 테스트 데이터 세트를 이용하여 모델 검정 작섭 실시 후 보고서 작성
▶ 분석기획 단계에서 수행해야 하는 작업
- 비즈니스 이해 및 범위 설정
- 프로젝트 정의 및 계획수립
- 프로젝트 위험 계획 수립
★ 다음 중 데이터 거버넌스의 구성 요소가 아닌 것은?
1. Principle
2. Organization
3. System
4. Process
▶ 데이터 거버넌스의 구성 요소: 원칙(1), 조직(2), 프로세스(4)
★ 다음 중 데이터 분석 준비도 프레임워크에서 분석 업무 파악 항목으로 가장 부적절한 것은?
1. 업무별 적합한 분석 기법 사용
2. 예측 분석 업무
3. 발생한 사실 분석 업무
4. 최적화 분석 업무
▶ 1번은 분석 기법 영역

★빅데이터 조직 구조 설계의 요소에 대한 설명으로 옳지 않은 것은?
1. 업무 활동은 수직 업무 활동과 수평 업무 활동으로 구분
2. 수직 업무 활동은 업무 프로세스 절차별로 업무 배분
3. 부서화는 조직의 미션과 목적을 효율적으로 달성하기 위한 조직 구조 유형
4. 조직의 목표 달성을 위하여 업무 활동 및 부서의 보고 체계 설계
▶
수직업무: 경영 계획, 예산 할당 등 우선순위 결정
수평업무: 업무 프로세스 절차별로 업무 배분
부서화: 조직의 미션과 목적을 효율적으로 달성하기 위한 조직 구조 유형 설계 (집중 구조, 기능 구조, 분산 구조)
★ 조직 구조의 설계 특성 중 가장 옳지 않은 것은?
1. 공식화
2. 직무 전문화
3. 협업화
4. 통제 범위
▶ 조직 구조 설계 시 공식화, 분업화, 직무 전문성, 통제 범위, 의사소통 및 조정 등의 특성 고려
★ 다음 중 데이터 사이언티스트에서 인문학 열풍을 가져오게 한 외부환경 요소로 가장 올바르지 않은 것은?
1. 비즈니스 중심이 제품생산에서 서비스로 이동
2. 빅데이터 분석기법의 이해와 분석 방법론이 확대
3. 단순 세계화인 컨버전스에서 복잡한 세계화인 디버전스로 변화
4. 경제와 산업의 논리가 생산에서 시장 창조로 변화
★ 다음 중 가트너가 제시한 데이터 사이언티스트가 갖춰야할 역량으로 가장 올바르지 않은 것은?
1. 데이터 관리
2. 분석 모델링
3. 비즈니스 분석
4. 하드 스킬
▶ 하드 스킬이 아닌 소프트스킬 제시
★ 다음 중 빅데이터 플랫폼 계층 구조 중 자원 배치 모듈, 노드 관리 모듈, 데이터 관리 모듈, 자원 관리 모듈, 서비스 관리 모듈, 사용자 관리 모듈, 모니터링 모듈, 보안 모듈로 구성되어 있는 계층은?
1. 인프라 스트럭처 계층
2. 플랫폼 계층 ▶ 작업 스케줄링 모듈, 데이터 자원 및 할당 모듈, 프로파일링 모듈, 서비스 관리 모듈, 사용자 관리 모듈 등
3. 소프트웨어 계층 ▶ 데이터 처리 및 분석 엔진, 데이터 수집 및 정제 모듈, 서비스 관리 모듈, 보안 모듈 등
4. 자원관리 계층
★ 다음 중 하둡 프레임워크의 HDFS에 대한 설명으로 올바른 것은?
1. 복제의 횟수는 내부에서 결정
2. NTFS, FAT 파일 시스템과 연계
3. GFS와 동일한 함수 적용
4. 네임 노드는 삭제한 데이터 노드를 관리하는 기능
▶ HDFS는 수십 TB 또는 PB 이상의 대용량 파일을 분산된 서버에 저장하고, 저장된 데이터를 빠르게 처리할 수 있게 하는 분산 파일 시스템.
하나의 네임 노드와 하나 이상의 보조 네임 노드, 다수의 데이터 노드로 구성
★ 다음 중 하둡 에코시스템에 대한 설명으로 옳지 않은 것은?
1. Sqoop: 비정형 데이터를 수집하는 대용량 데이터 전송 솔루션
2. HDFS: 대용량 파일을 분산된 서버에 저장하고, 그 저장된 데이터를 빠르게 처리할 수 있게 하는 하둡 분산 파일 시스템
3. Map Reduce: 대용량 데이터 세트를 분산 병렬 컴퓨팅에서 처리하거나 생성하기 위한 목적으로 만들어진 소프트웨어 프레임워크
4. HBase: 컬럼 기반 저장소로 HDFS와 인터페이스 제공
▶ 스쿱(Sqoop) 은 정형 데이터 수집
★ 다양한 데이터 소스를 위한 하둡 기반의 ETL 기술을 이용해서 데이터 웨어하우스에 적재하는 시스템은?
1. HBase ▶ HDFS를 기반으로 구현된 컬럼 기반의 분산 데이터베이스
2. Tajo
3. Oozie ▶ 하둡 작업을 관리하는 워크플로우 및 코디네이터 시스템
4. Zookeeper ▶ 분산 환경에서 서버들 간에 사호 조정이 필요한 다양한 서비스를 제공하는 분산 코디네이션
★ 많은 양의 로그 데이터를 효율적으로 수집하고 스트리밍 데이터 흐름을 비동기 방식으로 처리하기 위해 사용 가능한 가장 적합한 기술은?
▶ Flume
★ 다음 중 데이터 수집 기술 중에서 아래에서 설명하는 것은?
| 커넥터를 사용하여 관계형 데이터베이스와 하둡 간 데이터 전송 기능을 제공하는 기술 |
1. 스쿱(Sqoop)
2. 스크래파이 (Scrapy)
3. 플럼(Flume)
4. 스크라이브 (Scribe)
★ 인 메모리 기반의 실시간 데이터 처리와 관련된 오픈 소스 프로젝트는?
1. 임팔라 ▶ 하둡 기반의 실시간 sql 질의 시스템
2. 스파크
3. 하이브 ▶ 하둡 기반의 DW 솔루션 (HiveQL 쿼리 제공 - SQL 과 유사)
4. 스크라이브 ▶ 다수의 서버로부터 실시간으로 스트리밍 되는 로그 데이터를 수집하여 분산 시스템에 데이터를 저장하는 대용량 실시간 로그 수집 기술
★ 대규모 데이터를 저장할 수 있고, HBase, Cassandra 등의 제품이 있는 저장 기술은?
1. Sqoop
2. NoSQL
3. HDFS
4. Scribe
스크래파이: 웹 사이트를 크롤링하고 구조화된 데이터를 수집하는 파이썬 기반의 애플리케이션 프레임워크. 데이터 마이닝, 정보 처리, 이력 기록 같은 다양한 애플리케이션에 사용되는 수집 기술
(주요 기능: Spider, Selector, Items, Pipelines, Settings)
스크라이브: 다수의 서버로부터 실시간으로 스트리밍 되는 로그 데이터를 수집하여 분산 시스템에 데이터를 저장하는 대용량 실시간 로그 수집 기술
★ 다음 중 빅데이터 처리 과정 중 저장 단계에 사용하는 기술은?
1. Map-Reduce
2. 가시화
3. 직렬화
4. NoSQL
▶ 빅데이터 저장 기술은 분산 파일 시스템, 데이터베이스 클러스터, NoSQL 등으로 구분.
분산 파일 시스템은 네트워크를 통해 공유하는 여러 호스트 컴퓨터의 파일에 접근할 수 있게 하는 파일 시스템.
| Map-Reduce | - 대용량 데이터 세트를 분산 병렬 컴퓨팅에서 처리하거나 생성하기 위한 목적으로 만들어진 소프트웨어 프레임워크 - 모든 데이터를 키-값(Key-Value) 쌍으로 구성, 데이터 분류 - 맵 ▶ 셔플 ▶ 리듀스 순으로 데이터 처리 |
| NoSQL | - 전통적인 RDBMS 와 다른 DBMS를 지칭하기 위한 용어 - 데이터 저장에 고정된 테이블 스키마 불필요 - 조인 연산 불가 - 수평적으로 확장 가능 - 구글 빅테이블, HBase, 아마존 Simple DB, MS 사의 SSDS 등 |
★ NoSQL의 특성 중 BASE가 있다. Base의 특성 중 Soft-State가 뜻하는 것은?
1. 노드의 상태는 내부에 포함된 정보에 의해 결정되는 것이 아니라 외부에서 전송된 정보를 통해 결정되는 속성
2. 언제든지 데이터는 접근할 수 있어야 하는 속성 ▶ Basically Available
3. 일정 시간이 지나면 데이터의 일관성이 유지되는 속성 ▶ Eventually Consistency
4. 시스템에 장애가 발생하여 이용할 수 없을 경우 대체 시스템을 작동시키는 속성
▶
| Basically Available | 언제든지 데이터는 접근할 수 있어야 하는 속성 |
| Soft-State | 노드의 상태는 내부에 포함된 정보에 의해 결정되는 것이 아니라 외부에서 전송된 정보를 통해 결정되는 속성 |
| Eventually Consistency | 일정 시간이 지나면 데이터의 일관성이 유지되는 속성 |
★ 다음 중 NoSQL의 유형에 속하지 않는 것은?
1. Key-Value Store
2. Row Family Data Store
3. Document Store
4. Graph Store
▶ Row Family Data Store가 아닌, Column Family Data Store
★ 다음이 설명하는 빅데이터 플랫폼 구축 소프트웨어는?
| - 하둡 작업을 관리하는 워크플로우 및 코디네이터 시스템 - 맵리듀스나 피그와 같은 특화된 액션들로 구성된 워크폴로우 제어 |
1. R ▶ 통계 프로그래밍 언어인 S 언어를 기반으로 만들어진 오픈 소스 프로그래밍 언어
2. Oozie
3. Sqoop ▶ 커넥터를 이용하여 RDBMS에서 HDFS로 데이터를 수집하거나, HDFS에서 RDBMS로 데이터를 보내는 기능 수행
4. HBase ▶ 컬럼 기반 저장소로 HDFS와 인터페이스 제공(NoSQL)
★ 다음 중 하둡 에코시스템의 기능이 잘못 짝지어진 것은?
1. 비정형 데이터 수집: Chukwa, Flume, Scribe
2. 정형 데이터 수집: Sqoop
3. 분산 데이터 처리: HDFS ▶HDFS는 분산 데이터 저장 기술
4. 분산 데이터베이스: HBase
▶ 분산 데이터 처리는 Map Reduce 기술
★ 다음은 척와(Chukwa)의 주요 기능이다. 틀린 것은?
1. 에이전트: 데이터를 수집하는 기능 수행
2. 컬렉터: 에이전트로부터 수집된 데이터를 주기적으로 HDFS에 저장
3. 아카이빙: 컬렉터가 저장한 로그 파일에 대해 시간 순서로 동일한 그룹으로 묶는 작업 수행
4. 디먹스: 분산 처리를 통한 빠른 실시간 데이터 처리 수행
▶ 디먹스는 로그 레코드를 파싱해서 Key-Value 쌍으로 구성되는 척와 레코드를 만들고, 하둡 파일 시스템에 파일로 저장하는 기능
★ 빅데이터 분석 방법론의 분석 (기획) 절차는?
분석 기획 → 데이터 준비 → 데이터 분석 → 시스템 구현 → 평가 및 전개
★ CRISP-DM 분석 방법론의 분석 절차는?
업무 이해 → 데이터 이해 → 데이터 준비 → 모델링 → 평가 → 전개
▶ CRISP-DM:
비즈니스의 이해를 바탕으로 데이터 분석 목적의 6단계로 진행되는 데이터 마이닝 방법론
1996년 EU의 ESPRIT 프로젝트에서 시작한 방법론으로 1997년 SPSS 등이 참여하였으나 현재에는 중단
| 구성 | 설명 |
| 단계 | 최상위 레벨 |
| 일반화 태스크 | 데이터 마이닝의 단일 프로세스를 완전하게 수행하는 단위 |
| 세분화 태스크 | 일반화 태스크를 구체적으로 수행하는 레벨 |
| 프로세스 실행 | 데이터 마이닝을 위한 구체적인 실행 |
★ 다음 중 CRISP-DM 방법론의 모델링 단계에서 수행하는 태스크가 아닌 것은?
1. 모델 적용성 평가
2. 모델 테스트 계획 설계
3. 모델 평가
4. 모델링 기법 선택
▶ 모델 적용성 평가는 평가 단계에서 수행
★ CRISP-DM 분석 방법론에서 업무의 이해에 해당하는 태스크는 다음 중에 무엇인가?
1. 업무 목적 파악, 상황 파악, 데이터 마이닝 목표 설정, 프로젝트 계획 수립
2. 초기 데이터 수집, 데이터 기술 분석, 데이터 탐색, 데이터 품질 확인
3. 분석용 데이터 세트 선택, 데이터 정제, 데이터 통합, 학습/검증 데이터 분리
4. 모델링 기법 선택, 모델 테스트 계획 설계, 모델 작성, 모델 평가
▶

★ 분석 작업 WBS 설정 단계에 대한 설명으로 옳지 않은 것은?
1. 데이터 분석 과제 정의: 분석목표 정의서를 기준으로 프로젝트 전체 일정에 맞게 사전 준비 하는 단계
2. 데이터 준비 및 탐색: 데이터 처리 엔지니어와 데이터 분석가의 역할을 구분하여 세부 일정이 만들어지는 단계
3. 데이터 분석 모델링 및 검증: 데이터 분석가가 분석에 필요한 데이터들로부터 변수 후보를 탐색하고 최종적으로 도출하는 일정 수립
4. 산출물 정리: 데이터 분석단계별 산출물을 정리하고, 분석 모델링 과정에서 개발된 분석 스크립트 등을 정리하여 최종 산출물로 정리하는 단계
▶ 데이터 분석 모델링 및 검증단계에서는 데이터 준비 및 탐색이 완료된 이후 데이터 분석 가설이 증명된 내용을 중심으로 데이터 분석 모델링을 진행하는 단계

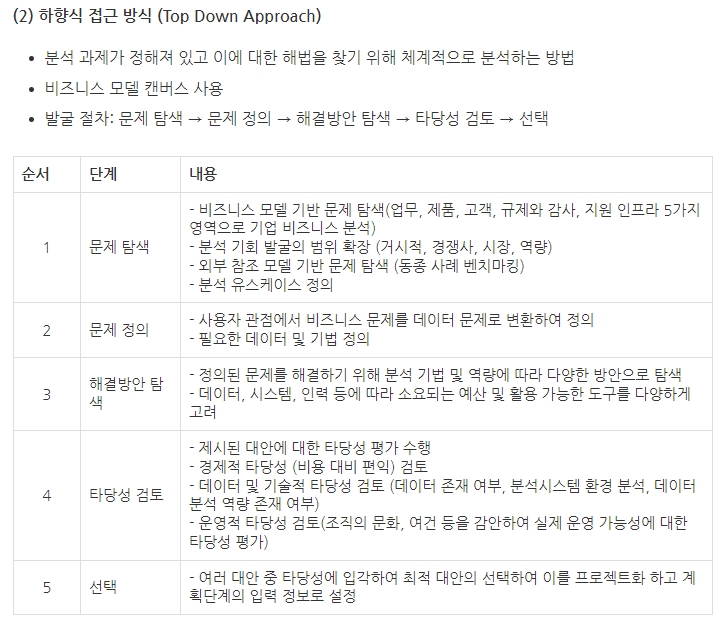
★ 하향식 접근 방식을 이용한 과제 발굴 절차는?
문제 탐색 → 문제 정의 → 해결방안 탐색 → 타당성 검토 → 선택
▶
| 상향식 접근 방식 | - 객관적인 데이터 그 자체를 관찰하고 실제적으로 행동에 옮겨 대상을 이해하는 방식 - 프로토타이핑, 디자인 사고 접근법 사용 - 문제 정의 자체가 어려운 경우 데이터를 기반으로 문제를 지속적으로 개선 |
| 하향식 접근 방식 | - 분석 과제가 정해져 있고 이에 대한 해법을 찾기 위해 체계적으로 분석 과제 발굴 |
★ 프로토타이핑 접근법에 대한 설명으로 알맞은 것은?
1. 상향식 접근 방법으로 신속하게 해결책이나 모형을 제시함으로써 이를 바탕으로 문제를 좀 더 명확하게 인식하고 필요한 데이터를 식별하여 구체화 가능
2. 문제가 정형화되어 있고 문제해결을 위한 데이터가 완벽하게 조직에 존재하는 경우 효과적
3. 문제가 주어지고 이에 대한 해법을 찾기 위하여 각 과정이 체계적으로 단계화되어 수행하는 방식
4. 문제 정의가 불명확하거나 이전에 접해보지 못한 새로운 문제일 경우 적용 어려움
▶ 프로토타이핑은 상향식 접근 방법
★ 인간에 대한 관찰과 공감을 바탕으로 다양한 대안을 찾는 확산적 사고와 주어진 상황에 대한 최선의 방법을 찾는 수렴적 사고의 반복을 통해 과제를 발굴하는 상향식 접근법은?
▶ 디자인 사고
★ 분석 마스터플랜 수립의 수립 기준이 아닌 것은?
1. 투입 비용 수준
2. 전략적 중요도
3. 실행 용이성
4. 비지니스 성과
▶

★ 다음 중 빅데이터 분석 방법론의 분석 기획 단계에서 수행하는 주요 과업으로 가장 부적절한 것은?
1. 위험 식별
2. 프로젝트 범위 설정
3. 프로젝트 정의
4. 필요 데이터의 정의
▶필요 데이터 정의는 데이터 준비 단계에서 수행
★ 다음이 설명하는 분석 방법론은?
| - 1996년 Frayyad 가 프로파일링 기술을 기반으로 통계적 패턴이나 지식을 찾기 위해 체계적으로 정리한 방법론 - 분석 절차는 데이터 세트 선택, 데이터 전처리, 데이터 변환, 데이터 마이닝, 데이터 마이닝 결과 평가의 5단계 |
▶ KDD
★ KDD 분석 방법론의 분석 절차는?
▶ 데이터 세트 선택 → 데이터 전처리 → 데이터 변환 → 데이터 마이닝 →데이터 마이닝 결과 평가
★ SEMMA 분석 방법론의 분석 절차는?
▶ 샘플링 → 탐색 → 수정 → 모델링 →검증

★ 데이터 분석 절차는?
▶ 문제 인식 → 연구 조사 → 모형화 → 자료 수집 → 자료 분석 → 분석 결과 공유
★ 다음 중 사용자 요구사항 수집 기법에 대한 설명으로 올바른 것은?
1. 브레인스토밍: 이해관계자와 직접 대화를 통해 정보를 구하는 공식적, 비공식적 정보 수집 방법
2. 인터뷰: 설문지 또는 여론조사 등을 이용해 많은 사람에게 간접적으로 정보 수집
3. 포커스 그룹 인터뷰: 일정한 자격 기준에 따라 6~12명 정도 선발 하여 한 장소에 모이게 한 후, 요구사항과 관련된 토론을 함으로써 자료 수집
4. 스캠퍼: 말을 꺼내기 쉬운 분위기로 만들어, 회의 참석자들이 내놓은 아이디어들을 비판 없이 수용할 수 있도록 하는 회의 기법
▶
브레인스토밍: 말을 꺼내기 쉬운 분위기로 만들어, 회의 참석자들이 내놓은 아이디어들을 비판 없이 수용할 수 있도록 하는 회의 기법
인터뷰: 이해관계자와 직접 대화를 통해 정보를 구하는 공식적, 비공식적 정보 수집 방법
스캠퍼: 사고의 영역을 7개의 키워드로 정해 놓고 이에 맞는 새로운 아이디어를 생성한 뒤 실행 가능한 최적의 대안 선택
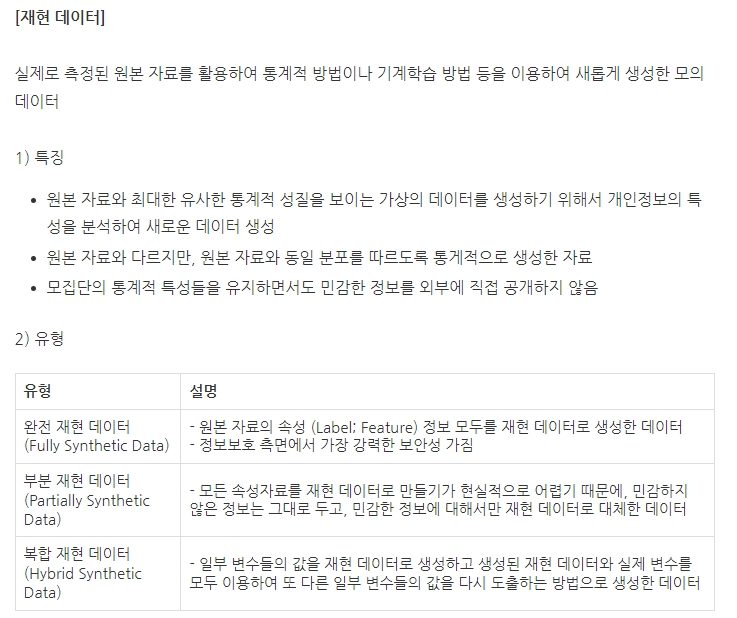
★ 다음 중 재현 데이터 (Synthetic Data)에 대한 설명으로 올바른 것은?
1. 재현하는 데이터에는 원 데이터의 속성을 포함해야 함
2. 재현 데이터는 기존 변수에 특정 조건 혹은 함수 등을 사용하여 새롭게 재정의한 파생 변수이다
3. 재현 데이터 중 완전 재현 데이터(Fully Synthetic Data)는 민감하지 않은 정보는 그대로 두고, 민감한 정보에 대해서만 재현 데이터로 대체한 데이터이다
4. 생성하는 방법은 단위 변환, 표현형식 변환, 요약 통계량 변환, 정보 추출, 변수 결합, 조건문 이용 등
★ 다음 중 일부 변수들의 값을 재현 데이터로 생성하고 생성된 재현 데이터와 실제 변수를 모두 이용하여 또 다른 일부 변수들의 값을 다시 도출하는 방법으로 생성하는 재현 데이터는?
1. Fully Synthetic Data
2. Partially Synthetic Data
3. Complete Synthetic Data
4. Hybrid Synthetic Data
▶
★ 데이터의 적절성, 정확성, 상호 운용성 등 명시된 요구와 내재된 요구를 만족하는 데이터 품질 기준은?
▶ 데이터 기능성
★ 수집된 정형 데이터 품질 보증을 위한 방법으로 적합하지 않은 것은?
1. 데이터 프로파일링: 정의된 표준 도메인에 맞는지 검증
2. 메타데이터 분석: 실제 운영 중인 데이터베이스의 테이블명-컬럼명-자료명-도메인-제약조건 등이며 데이터베이스 설계에는 반영되지 않은 한글 메타데이터-도메인 정보-엔터티 관계-코드 정의 등도 검증
3. 데이터 표준: 데이터 표준 준수 진단, 논리/물리 모델 표준에 맞는지 검증
4. 비업무 규칙 적용: 업무 규칙에 정의되어 있지 않는 값 검증
▶ 업무에 정의된 값이 업무 규칙으로 저장되어 있는지 검증
★ 다음 중 빅데이터 품질 기준 중 정형 데이터에 대한 품질 기준이 아닌 것은?
1. 완전성
2, 이식성
3, 유일성
4, 유효성
▶
| 완전성 | 필수 항목에 누락이 없어야 하는 성질 |
| 유일성 | 데이터 항목은 유일해야 하며 중복되어서는 안되는 성질 |
| 유효성 | 데이터 항목은 정해진 데이터 유효 범위 및 도메인을 충족해야 하는 성질 |
| 일관성 | 데이터가 지켜야할 구조, 값, 표현되는 형태가 일관되게 정의되고, 서로 일치하는 성질 |
| 정확성 | 실세계에 존재하는 객체의 표현 값이 정확히 반영되어야 하는 성질 |
★ 다음 중 빅데이터 품질 기준 중 비정형 데이터에 대한 품질 기준이 아닌 것은?
1. 기능성
2. 신뢰성
3. 유일성
4. 이식성
▶ 그 외에도 사용성, 효율성 있음
★ 다음 중 데이터 수집 방법으로 올바르지 않은 것은?
1. 크롤링: 웹 문서 수집
2. RSS: 여러 이벤트 소스로부터 발생한 실시간 이벤트
3. FTP: 대용량 파일 수집
4.Open API: 실시간 데이터 수집
▶ RSS: 블로그, 뉴스, 쇼핑몰 등의 웹 사이트에 게시된 새로운 글을 수집하여 공유하기 위해서 사용
여러 이벤트 소스로부터 발생한 실시간 이벤트를 수집하는 방법은 CEP
★ 다음 중 데이터 비식별화 기법에 대한 설명으로 틀린 것은?
1. 가명처리: 개인이 식별 가능한 데이터에 대하여 직접 식별할 수 없는 다른 값으로 대체하는 기법
2. 총계처리: 개인정보에 대하여 통곗값을 적용하여 특정 개인을 판단할 수 없도록 하는 기법
3. 범주화: 단일 식별 정보를 해당 그룹의 대푯값으로 변환하거나 구간 값으로 변환하여 고유 정보 추적 및 식별 방지 기법
4. 데이터값 삭제: 개인정보 식별이 가능한 특정 데이터값 대체 기법
▶데이터값 삭제는 개인정보 식별이 가능한 특정 데이터값을 삭제 처리하는 기법
★ 다음 중 데이터 변환 기술에 대한 설명으로 틀린 것은?
1. 정규화: 데이터를 특정 구간으로 바꾸는 방법
2. 일반화: 특정 구간에 분포하는 값으로 스케일을 변화시키는 방법
3. 집계: 다양한 차원의 방법으로 데이터를 요약하는 방법
4. 평활화: 주어진 여러 데이터 분포를 대표할 수 있는 새로운 속성이나 특징을 만드는 방법
▶ 평활화는 데이터로부터 잡음(노이즈)을 제거하기 위해 데이터 추세에서 벗어나는 값들을 변환하는 방법
| 평활화 | - 데이터로부터 잡음을 제거하기 위해 데이터 추세에 벗어나는 값들을 변환하는 기법 |
| 집계 | - 다양한 차원의 방법으로 데이터 요약 - 복수 개의 속성을 하나로 줄이거나 유사한 데이터 객체를 줄이고, 스케일을 변경하는 기법 |
| 일반화 | - 특정 구간에 분포하는 값으로 스케일을 변화시키는 기법 |
| 정규화 | - 데이터를 정해진 구간 내에 들도록 하는 기법 - 데이터에 대한 최소-최대 정규화, Z-점수 정규화, 소수 스케일링 등 통계적 기법 적용 |
| 속성/생성 | - 주어진 여러 데이터 분포를 대표할 수 있는 새로운 속성-특징 활용 기법 |
★ 계획 수립, 정의, 측정, 분석, 개선 단계로 되어 있는 데이터 품질 진단 절차 중 품질을 측정하고 분석, 품질지수가 도출되는 단계는?
▶ 데이터 품질 측정
데이터 품질 진단 절차
| 품질 진단 계획 수립 |
프로젝트 정의, 조직 정의 및 편성, 품질진단 절차 정의, 세부 시행 계획 확정, 품질 기준 및 진단 대상 정의 |
| 품질 기준 및 진단 대상 정의 |
품질 기준 선정, 품질 이슈 조사, 데이터 관리 문서 수집, 대상 중요도 평가, 진단 대상 선정, 핵심 데이터 항목 정의, 데이터 프로파일링, 업무규칙 정의 |
| 데이터 품질측정 |
- 품질측정계획 수립, 품질측정 체크리스트 준비, 데이터 품질측정 수행, 데이터 품질측정 결과 보고 - 도출된 업무규칙과 측정항목에 대해 실 운영시스템에 적용하여 품질수준을 측정하고 품질지수 산출 |
| 품질측정 결과 분석 |
- 오류가 발견된 컬럼 또는 측정항목에 대해 품질 기준별, 발생 유형별 오류 원인 분석, 주요 발생 사례 정리 - 주요 오류 원인별 개선 방안 도출 - 각 업무 분야별 변경영향도 분석 수행하여 시급성과 우선 순위 부여 |
| 데이터 품질 개선 |
- 도출된 개선안과 우선순위에 따라 세부 수행 일정과 책임 소재, 관련 조직 및 업무 관련자에 대한 공지 계획 등이 포함된 품질개선 계획 수립 - 수립된 품질개선 계획에 따라 개선 활동을 수행 - 품질 담당자는 개선 진행 상황 모니터링하여 전체적인 조율 및 진행 관리 - 오류 원인별 개선 수행 내역과 결과를 요약 보고 |
★ 기업의 내부 데이터로써 소비자들을 자신의 고객으로 만들고, 이를 장기간 유지하고자 내부 정보를 분석하고 저장하는 데 사용하는 정보시스템은?
▶ CRM (Customer Relationship Management, 고객 관계 관리)
★ 다음 중 데이터 백업이나 통합 작업을 할 경우 최근 변경된 데이터들을 대상으로 다른 시스템으로 이동하는 처리기술은?
1. CEP
2. CDC
3. RSS
4. EAI
▶ CEP: 여러 이벤트 소스로부터 발생한 이벤트를 실시간으로 추출하여 대응되는 액션 수행
RSS: 블로그, 웹사이트, 뉴스 등의 웹 사이트에 게시된 새로운 글을 공유하기 위해 XML 기반으로 정보를 배포하는 프로토콜을 활용하여 데이터 수집 기술
EAI: 기업에서 운영되는 서로 다른 플랫폼 및 애플리케이션들간의 정보 전달, 연계, 통합을 가능하게 해주는 연계 기술
★ 다음 중 데이터 웨어하우스(DW)에 저장되어 있는 데이터베이스의 특징으로 틀린 것은?
1. 소멸적
2. 시간에 따라 변화
3. 주제 지향적
4. 통합적
▶ 데이터 웨어하우스의 특징
| 주제 지향적 | 기능이나 업무가 아닌 주제 중심적으로 구성 |
| 통합적 | 데이터의 일관성을 유지하면서 전사적 관점에서 하나로 통합 |
| 시간에 따라 변화 | 시간에 따른 변경을 항상 반영 |
| 비휘발적 | 적재가 완료되면 읽기 전용 형태의 스냅 샷 형태로 존재 |
★ 다음 중 사용자의 의사결정에 도움을 주기 위하여, 기간 시스템의 데이터베이스에 축적된 데이터를 공통 형식으로 변환해서 관리하는 데이터베이스는?
1. 데이터 웨어하우스
2. 데이터 레이크
3. 메타데이터
4. 마이 데이터
▶
| 데이터 레이크 | 정형, 반정형, 비정형 데이터를 비롯한 모든 가공되지 않은 다양한 종류의 데이터를 저장할 수 있는 시스템 또는 중앙 집중식 데이터 저장소 |
| 메타데이터 | - 데이터에 관관한 구조화된 데이터 - 다른 데이터를 설명해주는 데이터 |
| 마이 데이터 | - 개인이 자신의 정보를 관리, 통제할 뿐만 아니라 이러한 정보를 신용이나 자산관리 등에 능동적으로 활용하는 일련의 과정 |
★ 분석 대상별 분석 기획 유형에 해당하지 않는 것은?
1. 최적화
2. 문제 정의
3. 통찰
4. 발견
▶ 최적화, 솔루션, 통찰, 발견
★ CAP 이론에 대한 설명으로 틀린 것은?
1. 분산 컴퓨터 환경은 Consitency, Availability, Partiton Tolerance 3가지 특징을 가지고 있으며, 이 중 두 가지만 만족할 수 있다는 이론
2. Consitency: 모든 사용자가 같은 시간에 같은 데이터가 보여야 한다는 특성
3. Availability: 모든 클라이언트가 읽기 및 쓰기 가능해야 한다는 특성
4. Partition Tolerance: 데이터가 각각의 저장소에 고립된 상태로 저장되어야 한다는 특성
▶ Partiton Tolerance: 물리적 네트워크 분산 환경에서 시스템이 원활하게 동작해야 한다는 특성
★ 다음이 설명하는 용어는?
| <키-값> 으로 이루어진 데이터 오브젝트를 전달하기 위해 텍스트를 사용하는 개방형 표준 포맷 |
▶ JSON
★ 다음 중 정규표현식 기호에서 0개 이상의 문자열 매칭 기호는?
1. + ▶ 1개 이상의 문자열 매칭
2. ^ ▶ 시작 문자열
3. *
4. $ ▶ 종료 문자열
[정리 내용 보기]
[빅데이터분석기사] 1과목 - 빅데이터 분석 기획 (1-1)
[목차] [빅데이터 분석기사] 시험 과목 및 주요 내용 (필기) 빅데이터 분석기사 (필기) 시험 과목 및 주요 내용 출처: 데이터자격검정 (dataq.or.kr) 필기과목명 주요항목 세부항목 세세항목 빅데이터
puppy-foot-it.tistory.com
[빅데이터 분석기사] 1과목 빅데이터 분석 기획 (1-2)
[목차] [빅데이터 분석기사] 시험 과목 및 주요 내용 (필기) 빅데이터 분석기사 (필기) 시험 과목 및 주요 내용 출처: 데이터자격검정 (dataq.or.kr) 필기과목명 주요항목 세부항목 세세항목 빅데이터
puppy-foot-it.tistory.com
[빅데이터 분석기사] 1과목 빅데이터 분석 기획 (2-1)
[목차] [빅데이터 분석기사] 시험 과목 및 주요 내용 (필기) 빅데이터 분석기사 (필기) 시험 과목 및 주요 내용 출처: 데이터자격검정 (dataq.or.kr) 필기과목명 주요항목 세부항목 세세항목 빅데이터
puppy-foot-it.tistory.com
[빅데이터 분석기사] 1과목 빅데이터 분석 기획 (2-2)
[목차] [빅데이터 분석기사] 시험 과목 및 주요 내용 (필기) 빅데이터 분석기사 (필기) 시험 과목 및 주요 내용 출처: 데이터자격검정 (dataq.or.kr) 필기과목명 주요항목 세부항목 세세항목 빅데이터
puppy-foot-it.tistory.com
[빅데이터 분석기사] 1과목 빅데이터 분석 기획 (3-1-1)
[목차] [빅데이터 분석기사] 시험 과목 및 주요 내용 (필기) 빅데이터 분석기사 (필기) 시험 과목 및 주요 내용 출처: 데이터자격검정 (dataq.or.kr) 필기과목명 주요항목 세부항목 세세항목 빅데이터
puppy-foot-it.tistory.com
[빅데이터 분석기사] 1과목 빅데이터 분석 기획 (3-1-2)
[목차] [빅데이터 분석기사] 시험 과목 및 주요 내용 (필기) 빅데이터 분석기사 (필기) 시험 과목 및 주요 내용 출처: 데이터자격검정 (dataq.or.kr) 필기과목명 주요항목 세부항목 세세항목 빅데이터
puppy-foot-it.tistory.com
[빅데이터 분석기사] 1과목 빅데이터 분석 기획 (3-1-3)
[목차] [빅데이터 분석기사] 시험 과목 및 주요 내용 (필기) 빅데이터 분석기사 (필기) 시험 과목 및 주요 내용 출처: 데이터자격검정 (dataq.or.kr) 필기과목명 주요항목 세부항목 세세항목 빅데이터
puppy-foot-it.tistory.com
[빅데이터 분석기사] 1과목 빅데이터 분석 기획 (3-2)
[목차] [빅데이터 분석기사] 시험 과목 및 주요 내용 (필기) 빅데이터 분석기사 (필기) 시험 과목 및 주요 내용 출처: 데이터자격검정 (dataq.or.kr) 필기과목명 주요항목 세부항목 세세항목 빅데이터
puppy-foot-it.tistory.com
'자격증 > 빅데이터분석기사' 카테고리의 다른 글
| [빅데이터 분석기사] 2과목 기출문제 오답노트 (1) | 2024.03.23 |
|---|---|
| [빅데이터 분석기사] 4과목 기출문제 오답노트 (0) | 2024.03.19 |
| [빅데이터 분석기사] 4과목 빅데이터 결과 해석(2) (0) | 2024.03.16 |
| [빅데이터 분석기사] 4과목 빅데이터 결과 해석(1) (0) | 2024.03.15 |
| [빅데이터 분석기사] 3과목 빅데이터 모델링(3-2-2) (0) | 2024.03.14 |



