선형 회귀(linear regression)
데이터 과학과 통계학의 핵심인 선형 회귀는 관측 데이터에 맞는 직선을 훈련하고, 이를 통해 변수 간의 선형 관계를 보여주고 새로운 데이터에 대한 예측을 만든다. 입력 변수가 하나일 경우 선형 회귀는 직선의 방정식을 훈련하고, 두 개면 평면의 방정식을, 세 개 이상이면 초평면의 방정식을 훈련한다.
- 회귀: 관측 데이터에서 어떤 함수를 훈련한 다음 새로운 데이터에 대한 예측을 만드는 방법.
기본 선형 회귀
간단한 데이터 셋으로 복잡한 기법을 이해할 수 있으면 복잡한 데이터 없이도 알고리즘의 강점과 한계를 파악할 수 있다.
선형 상관관계가 나타난다는 의미는,
변수 중 하나가 증가 (또는 감소)하면 다른 변수도 대략 이에 비례해 증가 (또는 감소) 한다는 것이고, 이런 상관관계를 점들을 통과하는 직선으로 그릴 수 있다.

[선형 회귀의 단점]
- 실제 데이터는 잡음이 많고 완벽하지 않다 (직선과 일치하지 않는다)
- 선형관계로 제한, 그들 사이에 직선 관계가 있다고 가정해서 때때로 올바르지 않음
- 종속 변수의 평균만 봄, 종속변수의 극단을 살펴볼 필요가 있을 때 어려움, 평균이 단일 변수에 대한 완전한 설명이 아닌 것처럼 선형 회귀는 변수 간의 관계에 대한 완전한 설명이 아님. 분위수 회귀를 사용해야 문제 해결 가능
- 특이치에 민감
- 선형회귀는 데이터가 독립적이라고 가정하지만 항상 합리적인 것은 아님. 다중 레벨 모델을 사용해서 해결 가능
- 계수의 값들이 왜 그런지 명확하지 않을 때가 있다. 특히 데이터셋의 특성이 서로 깊게 연간되어 있을 때 그러하다
[사이킷런을 이용한 선형 회귀]
사이킷런을 사용해 10마리의 강아지 데이터에서 검증을 고려하지 않는 기본 선형 회귀 수행
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
# 데이터 로드
df = pd.read_csv('http://bit.ly/3goOAnt', delimiter=',')
# 입력 변수 추출(마지막 열 제외)
X = df.values[:, :-1]
# 출력값(마지막 열) 추출
Y = df.values[:, -1]
# 해당 데이터로 선형 회귀 훈련
fit = LinearRegression().fit(X,Y)
m = fit.coef_.flatten()
b = fit.intercept_.flatten()
print("m = {0}".format(m))
print("b = {0}".format(b))
# 그래프 그리기
plt.plot(X, Y, 'o') #산점도
plt.plot(X, m*X+b) # 직선
plt.show()
| [코드 설명] - 깃허브에서 csv 데이터 가져옴 - 판다스의 열을 X와 Y 데이터셋으로 분리. - 입력 데이터 X와 출력 데이터 Y로 LinearRegression 모델의 fit() 메서드 호출 - 훈련된 모델에서 학습된 선형 함수의 계수 m과 b를 얻을 수 있음 |
★ 계수 m과 b는 각각β1 β0 (벡터)로 이름을 바꿔 표현하기도 한다.

잔차와 제곱 오차
[머신러닝 훈련의 기본이 되는 두 가지 사항]
- 최적을 정의하는 기준 ▶ 잔차(residual)를 제곱한 합을 최소화
- 최적에 도달하려면 어떻게 해야 하는가
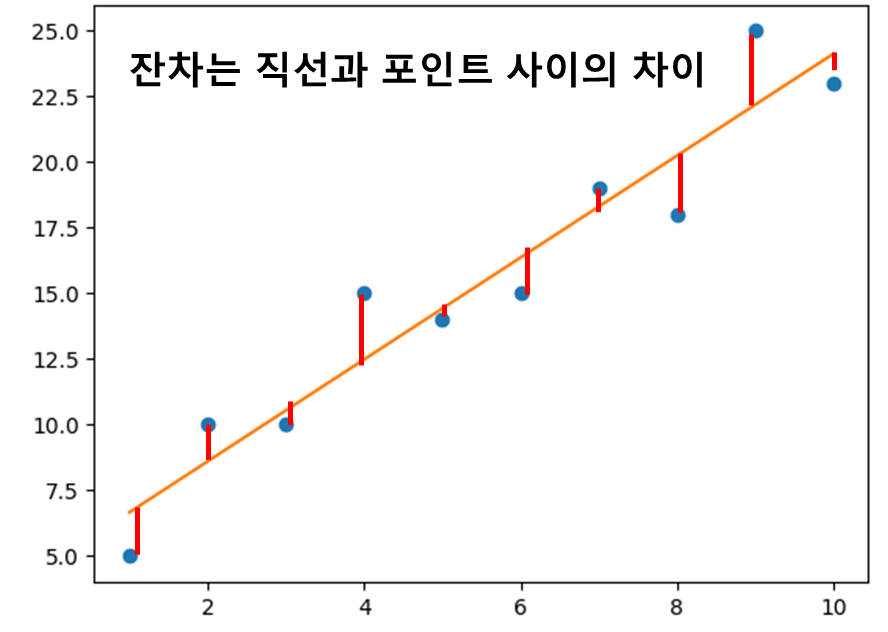
직선 위에 있는 포인트의 잔차는 양수이고 직선 아래에 있는 포인트의 잔차는 음수이다.
즉, (직선으로 구한) 예측한 y 값과 (데이터에 있는) 실제 y 값 사이의 차이를 뺀 값이다.
잔차가 데이터를 예측하는 데 직선이 얼마나 틀렸는지를 나타내기 때문에 오차(error) 라고도 부른다.
[주어진 라인 및 데이터에 대한 잔차 계산하기]
# 주어진 라인 및 데이터에 대한 잔차 계산하기
import pandas as pd
# 데이터 로드
points = pd.read_csv('http://bit.ly/3goOAnt', delimiter=',').itertuples()
# 직선 방정식의 계수
m = 1.93939
b = 4.73333
# 잔차 계산
for p in points:
y_actual = p.y # 실제 y 값
y_predict = m*p.x + b # y 예측값
residual = y_actual - y_predict # 잔차(오차) = 실제 값 - 예측 값
print(residual)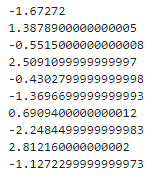
10개의 데이터 포인트를 통과하는 최적의 직선을 찾을 때 이런 잔차를 최소화하면 직선과 포인트 사이의 간격을 최소화 할 수 있다.
총 잔차의 값은 각 잔차의 제곱 합을 구하는 것이다. 즉, 각 잔차에 자기 자신을 곱한 다음 모두 더하면 되는데, 각 실제 y 값에서 직선으로 구한 예측 y 값을 뺀 다음, 그 차이를 제곱하고 모두 더하면 된다.
[직선과 데이터 포인터에 대한 잔차의 제곱 합 계산하기]
# 직선과 데이터 포인터에 대한 잔차의 제곱 합 계산하기
import pandas as pd
# 데이터 로드하기
points = pd.read_csv('http://bit.ly/2KF29Bd', delimiter=',').itertuples()
# 직선 방정식의 계수
m = 1.93939
b = 4.73333
sum_of_squares = 0.0
# 제곱 합 계산
for p in points:
y_actual = p.y # 실제 y 값
y_predict = m*p.x + b # y 예측값
residual_squared = (y_actual - y_predict)**2 #
sum_of_squares += residual_squared
print('제곱 합={}'.format(sum_of_squares))
제곱 합의 수치가 낮을수록 더 잘 맞는 직선이다.
최적의 직선 찾기
최소 제곱 합을 만드는 m과 b 값은 어떻게 찾을까?
- 무차별 대입(brute-force) 방식을 사용해 m과 b 값을 무작위로 수백만 개 생성한 후, 최소 제곱 합 만들기 ▶ 적절한 근삿값을 찾는 데 아주 많은 시간이 걸려 실용적이지 못함
- 닫힌 형식 방정식
- 역행렬
- 행렬 분해
- 경사 하강법
- 확률적 경사 하강법
최적의 회귀 직선을 찾는 과정은 머신러닝의 훈련에 해당한다.
1) 닫힌 형식 방정식
입력 변수가 하나인 단순 선형 회귀의 경우에만 활용 가능

[단순 선형 회귀에서 m과 b 계산하기]
# 단순 선형 회귀에서 m과 b 계산하기
import pandas as pd
# 데이터 로드하기
points = list(pd.read_csv('http://bit.ly/2KF29Bd', delimiter=',').itertuples())
n = len(points)
m = (n*sum(p.x*p.y for p in points) - sum(p.x for p in points) *
sum(p.y for p in points)) / (n*sum(p.x**2 for p in points) -
sum(p.x for p in points)**2)
b = (sum(p.y for p in points) / n) - m * sum(p.x for p in points) / n
print(m, b)
닫힌 형식 방정식은 대규모 데이터로 확장하기 어렵기 때문에 (계산 복잡도) 더 많은 양의 데이터를 다룰 수 있는 기법의 적용이 선호된다.
★ 계산 복잡도 이론: 입력의 크기가 커짐에 따라 알고리즘의 수행 시간을 측정한다.
2) 역행렬 기법
아래 식은 입력 변수 행렬 X와 출력 변수 벡터 y가 주어졌을 때 계수 벡터를 계산한다.
X 행렬에 대해 전치와 역행렬 연산이 수행되고 행렬 곱셉으로 결합된다.

[넘파이로 위의 공식을 수행하여 계수 m과 b 구하기]
# 역행렬과 전치 행렬 사용해 선형 회귀 풀기
import pandas as pd
from numpy.linalg import inv
import numpy as np
# 데이터 로드
df = pd.read_csv('http://bit.ly/3goOAnt', delimiter=',')
# 입력 변수 추출(마지막 열 제외)
X = df.values[:, :-1].flatten()
# 절편(intercept) 위해 '1'로 채워진 열 추가
X_1 = np.vstack([X, np.ones(len(X))]).T
# 출력값(마지막 열) 추출
Y = df.values[:, -1]
# 기울기와 절편 계수 계산
b = inv(X_1.transpose() @ X_1) @ (X_1.transpose() @ Y)
print(b)
# y값 예측
y_predict = X_1.dot(b)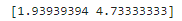
★ X에 1로 채워진 열을 추가하는 것은 절편 β0 에 곱해지는 가상의 입력값이며, 이는 입력과 계수의 곱을 하나의 행렬 곱셈으로 표현하기 위해서이다.
3) 행렬 분해 기법
데이터에 차원이 많으면 컴퓨터에 과부하가 걸려 불안정한 결과를 생성할 수 있기 때문에 행렬 분해를 사용하는 게 좋다.
이전처럼 절편 β0 를 위해 행렬 X에 1로 채워진 열을 추가하고, 두 개의 Q와 R로 분해한다.

위는 Q와 R을 사용해 베타 계수의 값을 구하는 식이고, 이를 이용해 넘파이로 선형 회귀를 수행하는 코드는 아래와 같다.
[QR 분해를 사용해 선형 회귀 수행하기]
# QR 분해를 사용해 선형 회귀 수행하기
import pandas as pd
from numpy.linalg import qr, inv
import numpy as np
# 데이터 로드
df = pd.read_csv('http://bit.ly/3goOAnt', delimiter=',')
# 입력 변수 추출(마지막 열 제외)
X = df.values[:, :-1].flatten()
# 절편(intercept) 위해 '1'로 채워진 열 추가
X_1 = np.vstack([X, np.ones(len(X))]).T
# 출력값(마지막 열) 추출
Y = df.values[:, -1]
# QR 분해를 사용해 기울기와 절편 계수 계산
Q, R = qr(X_1)
b = inv(R).dot(Q.transpose()).dot(Y)
print(b)
많은 데이터 과학 라이브러리에서 선형 회귀를 위해 QR 분해를 사용하는 이유는 대량의 데이터를 더 쉽게 다룰 수 있고 안정적이기 때문이다. 컴퓨터는 일정 소수점까지만 다룰 수 있으므로 근삿값을 구해야 하기 때문에 알고리즘이 근삿값에서 오차를 악화시키지 않는 것이 중요하다.
★ 수치적 안정성: 알고리즘이 근삿값에서 오류를 증폭시키지 않고 최소화하는 정도
경사 하강법(gradient descent)
경사하강법은 미분과 반복을 사용해 목적 함수에 대한 파라미터 집합을 최소화.최대화하는 최적화 기법이다.
[보면 좋은 글]
[파이썬 머신러닝] 경사 하강법(GD, gradient descent)
경사하강법 경사하강법(GD, gradient descent)은 여러 종류의 문제에서 최적의 해법을 찾을 수 있는 일반적인 최적화 알고리즘이다. 경사 하강법의 기본 아이디어는 비용 함수를 최소화하기 위해 반
puppy-foot-it.tistory.com
[머신러닝 경사 하강법의 산악 지형 비유]
- 다양한 파라미터로 구성된 전체 제곱 합의 손실 ▶ 하나의 산악 지형
- 손실을 최소화 하기 위해 이 손실 지형을 탐색
- 편도함수 ▶ 모든 파라미터의 경사를 보여주는 손전등 역할
- 경사가 아래로 내려가는 방향으로 m과 b를 이동시킴
- 경사가 클수록 더 많이 이동, 경사가 작을수록 더 조금씩 이동
- 학습률 ▶ 경사 크기에 비례해 보폭의 크기 계산
- 학습률이 클수록 정확도를 희생하더라도 더 빠르게 수행
- 학습률이 작을수록 학습하는 데 시간이 오래 걸리고 더 많은 반복 필요
[학습률 비유]
- 개미: 학습률 작음(발걸음이 작음). 바닥에 도달하는 데 오랜 시간이 걸리나, 정확하게 내려갈 수 있음.
- 거인: 학슙률 빠름(발걸음이 큼). 최소한의 발걸음으로 개미가 아무리 걸어도 도달할 수 없는 지점까지 도달 가능.
- 인간: 학습률 보통(균형 잡힌 보폭 크기). 최솟값에 도달할 때 속도와 정확성 사이에서 적절한 균형을 유지.
[f(x) = (x-3)^2 + 4 함수가 최소가 되는 x 값 찾기]
먼저 도함수 dx_f(x)를 정의하고
도함수를 구한 뒤 경사 하강법 수행
# 경사 하강법
import random
def f(x):
return (x - 3)**2 + 4
def dx_f(x):
return 2*(x - 3)
# 학습률
L = 0.001
# 경사 하강법 수행할 반복 횟수
iterations = 100000
# 무작위한 x에서 시작
x = random.randint(-15, 15)
for i in range(iterations):
# 경사 구함
d_x = dx_f(x)
# 학습률 * slope 빼서 x 업데이트
x -= L * d_x
print(x, f(x))
▶ 함수의 최저점이 x=3 이 명확하게 나타난다.
◆ 경사 하강법과 선형 회귀
경사 하강법을 선형 회귀에 사용하려면 변수가 x가 아니라 m과 b 라는 점만 제외하면 동일하다. 왜냐하면 선형 회귀에서는 훈련 데이터로 제공되는 x 값과 y 값은 이미 알고 있기 때문이다.
선형 회귀가 풀어야 하는 변수는 파라미터 m과 b 이고, 이를 통해 x 값을 받아 새로운 y 값을 예측하는 최적의 직선을 찾을 수 있다.
m과 b의 기울기를 계산하기 위해서는 각 변수에 대한 편도함수가 필요하며, 제곱 합 손실을 최소화 하기 위해서 m과 b 에 대한 제곱 합 함수의 도함수를 구해야 한다.
[선형 회귀를 위한 경사 하강법 수행]
# 선형 회귀를 위한 경사 하강법 수행
import pandas as pd
# 데이터 로드하기
points = list(pd.read_csv('http://bit.ly/2KF29Bd', delimiter=',').itertuples())
# 계수 초기화
m = 0.0
b = 0.0
# 학습률
L = 0.001
# 경사 하강법 수행할 반복 횟수
iterations = 100000
n = float(len(points)) # x에 있는 원소 개수
# 경사 하강법 수행
for i in range(iterations):
# m에 대한 그래디언트
D_m = sum(2 * p.x * ((m* p.x + b) - p.y) for p in points)
# b에 대한 그래디언트
D_b = sum(2 * ((m* p.x + b) - p.y) for p in points)
# m과 b 업데이트
m -= L * D_m
b -= L * D_b
print("Y = {0}x + {1}".format(m, b))
[심파이를 사용해 최적의 직선을 찾는 방법]
# 심파이를 사용한 선형 회귀 경사 하강법
from sympy import *
m, b, i, n = symbols('m b i n')
x, y = symbols('x y', cls=Function)
sum_of_squares = Sum((m*x(i) + b - y(i)) ** 2, (i, 0, n))
d_m = diff(sum_of_squares, m)
d_b = diff(sum_of_squares, b)
print(d_m)
print(d_b)
m과 b에 대한 도함수가 각각 출력된다.
주어진 데이터셋에서 경사 하강법을 사용해 선형 회귀를 실행하려면 몇 가지 추가 단계를 수행해야 한다.
- d_m과 d_b 도함수를 구하기 위해 모든 데이터 포인트 반복- n, x(i), y(i) 값 대체▶ 경사 하강법을 사용해 최적의 값을 찾아야 하는 m과 b 변수만 남음.
[심파이를 사용해 선형 회귀 풀기]
# 심파이를 사용해 선형 회귀 풀기
import pandas as pd
from sympy import *
# 데이터 로드하기
points = list(pd.read_csv('http://bit.ly/2KF29Bd', delimiter=',').itertuples())
m, b, i, n = symbols('m b i n')
x, y = symbols('x y', cls=Function)
sum_of_squares = Sum((m*x(i) + b - y(i)) ** 2, (i, 0, n))
d_m = diff(sum_of_squares, m).subs(n, len(points) - 1).doit().replace(x, lambda i: points[i].x).replace(y, lambda i: points[i].y)
d_b = diff(sum_of_squares, b).subs(n, len(points) - 1).doit().replace(x, lambda i: points[i].x).replace(y, lambda i: points[i].y)
# 계산 속도 향상을 위해 lambdify 로 컴파일
d_m = lambdify([m, b], d_m)
d_b = lambdify([m, b], d_b)
# 모델 계수 초기화
m = 0.0
b = 0.0
# 학습률
L = 0.001
# 반복 횟수
iterations = 100000
# 경사 하강법 수행
for i in range(iterations):
# m과 b 업데이트
m -= d_m(m,b) * L
b -= d_b(m,b) * L
print("y = {0}x + {1}".format(m, b))
★ 두 편도함수를 lambdify()를 호출해 심파이 표현식을 최적화된 파이썬 함수로 변환하는 것이 좋다. 이렇게 하면 경사 하강법을 수행할 때 훨씬 더 빠르게 계산된다.
[선형 회귀의 손실 함수 그리기]
# 선형 회귀의 손실 함수 그리기
import pandas as pd
from sympy.plotting import plot3d
from sympy import *
points = list(pd.read_csv('http://bit.ly/2KF29Bd', delimiter=',').itertuples())
m, b, i, n = symbols('m b i n')
x, y = symbols('x y', cls=Function)
sum_of_squares = Sum((m*x(i) + b - y(i)) ** 2, (i, 0, n)).subs(n, len(points) - 1).doit().replace(x, lambda i: points[i].x).replace(y, lambda i: points[i].y)
plot3d(sum_of_squares)
다음 내용
[개발자를 위한 수학] 선형 회귀 - 2
이전 내용 [개발자를 위한 수학] 선형회귀 - 1선형 회귀(linear regression) 데이터 과학과 통계학의 핵심인 선형 회귀는 관측 데이터에 맞는 직선을 훈련하고, 이를 통해 변수 간의 선형 관계를 보
puppy-foot-it.tistory.com
[출처]
개발자를 위한 필수 수학
위키백과
jesuiszoe.log
'[파이썬 Projects] > <파이썬 - 수학 | 통계학>' 카테고리의 다른 글
| [개발자를 위한 수학] 선형 회귀 - 3 (7) | 2024.10.17 |
|---|---|
| [개발자를 위한 수학] 선형 회귀 - 2 (3) | 2024.10.16 |
| [파이썬+통계학] 현대통계학 연습문제 파이썬 구현(ch.8)-3 (4) | 2024.10.13 |
| [파이썬+통계학] 현대통계학 연습문제 파이썬 구현(ch.8)-2 (1) | 2024.10.13 |
| [파이썬+통계학] 현대통계학 연습문제 파이썬 구현(ch.8)-1 (2) | 2024.10.11 |



