★ 시작에 앞서 ★
해당 내용은 '<현대통계학-제6판>, 다산출판사, 2024' 에 나와있는 챕터별 연습문제를 교재를 응용하여 풀이하고, 수학적인 문제에 대한 답변을 파이썬으로 구현해보기 위해 작성하는 글이다.
해당 답변을 구현하는 방식은 답안지 없이 필자가 스스로 구현하는 것이므로, 정확한 (혹은 가장 효과적인) 답변이 아닐 수 있다. 이 글의 목적은 통계학 공부와 파이썬 프로그래밍 언어 공부를 동시에 하고자 함이며, 통계학을 공부하고 싶으신 분들은 해당 교재를 구매하는 것을 추천한다.
또한, 연습문제 번호 및 문제 내용은 필자가 임의대로 작성하였으며, 교재와는 다를 수 있다.
잘못된 부분이 있다면 언제든 피드백 부탁 드립니다! 감사합니다
이전 내용
[파이썬+통계학] 현대통계학 연습문제 파이썬 구현(ch.9)-1
★ 시작에 앞서 ★ 해당 내용은 ', 다산출판사, 2024' 에 나와있는 챕터별 연습문제를 교재를 응용하여 풀이하고, 수학적인 문제에 대한 답변을 파이썬으로 구현해보기 위해 작성하는 글이다.해
puppy-foot-it.tistory.com
챕터 9 주요 내용: 추론통계학, 점추정, 구간추정, 신뢰도, 신뢰구간,
챕터 9 연습문제1
Q. 어느 전자회사가 일주일 동안 제작한 스마트폰 중에서 200개를 뽑아서 두께를 재어 보니 평균이 0.824cm 이고 표준 편차는 0.042cm 였다. 이 전자회사가 제작하는 전체 스마트폰의 평균 두께에 대한 90% 신뢰구간을 구하라.
# 스마트폰 평균 두께
import numpy as np
import scipy.stats as stats
# 주어진 데이터
mean = 0.824
s = 0.042 # 표본 표준편차
n = 200 # 표본 크기
# 신뢰수준 설정
confidence_level = 0.90
# z 값 계산
z_score = stats.norm.ppf(1 - (1 - confidence_level) / 2)
# 신뢰구간 계산
margin_of_error = z_score * (s / np.sqrt(n)) # z 값에 대한 신뢰구간
confidence_interval = (mean - margin_of_error, mean + margin_of_error)
# 출력
print(f"{int(confidence_level * 100)}% 신뢰구간: {confidence_interval[0]:,.3f}cm ~ {confidence_interval[1]:,.3f}cm")
챕터 9 연습문제2
Q. 어느 대학교에서 임의로 100명을 뽑아 키를 쟀더니 평균이 168cm 였다고 한다. 지금까지의 연구결과로 보아서는 전체 학생들 키의 표준편차는 10cm 였다. 이 대학교 전체 학새의 평균 키에 대한 95%와 99%의 신뢰구간을 구하라.
# 대학교 학생 평균 키
import numpy as np
import scipy.stats as stats
# 주어진 데이터
mean = 168 # 표본 평균
std_dev = 10 # 모집단 표준편차
n = 100 # 표본 크기
# 신뢰수준 설정
confidence_levels = [0.95, 0.99]
# 결과 출력
for confidence in confidence_levels:
# Z 값 계산 (신뢰구간의 양 끝에서 Z값을 계산)
z_score = stats.norm.ppf(1 - (1 - confidence) / 2)
# 신뢰구간 계산
margin_of_error = z_score * (std_dev / np.sqrt(n))
confidence_interval = (mean - margin_of_error, mean + margin_of_error)
# 출력
print(f"{int(confidence * 100)}% 신뢰구간: {confidence_interval[0]:,.1f}cm ~ {confidence_interval[1]:,.1f}cm")챕터9 연습문제 3
Q. 다이어트 약의 효과를 알아보기 위해 임의로 12명의 사람을 뽑아 다이어트 약을 복용하게 하고 일정시간이 지난 후의 감량된 몸무게를 재어 보니 평균이 7.38kg 이었고 표준편차는 1.24kg 이었다. 이 다이어트 약을 먹고 감량할 수 있는 몸무게에 대한 95% 신뢰구간을 정하라.
# 다이어트 약- 감량 몸무게
import numpy as np
from scipy.stats import t
# 주어진 데이터
mean = 7.38
s = 1.24 # 표본 표준편차
n = 12 # 표본 크기
# 신뢰수준 설정
confidence_level = 0.95
# t값 계산
t_score = t.ppf(1 - (1 - confidence_level) / 2, df=n-1)
# 신뢰구간 계산
margin_of_error = t_score * (s / np.sqrt(n))
confidence_interval = (mean - margin_of_error, mean + margin_of_error)
# 출력
print(f"{int(confidence_level * 100)}% 신뢰구간: {confidence_interval[0]:,.2f}kg ~ {confidence_interval[1]:,.2f}kg")주어진 표본 크기가 30 미만이므로 t-분포를 사용하여 신뢰구간 계산
챕터9 연습문제4
Q. 어느 심리학자가 반응시간(reaction time)의 평균을 측정하는 데 표준편차가 0.05초 라는 것을 알았다. 오차의 허용범위가 ±0.01초를 초과하지 않고 95%의 신뢰도를 가지기 위해서는 표본의 크기를 얼마로 해야 하는가?
# 심리학자의 반응시간 측정
import numpy as np
import scipy.stats as stats
import math
# 신뢰 수준 설정
confidence_level = 0.95
# z 값 계산
z_score = stats.norm.ppf(1 - (1 - confidence_level) / 2)
# 표준 편차
s = 0.05
# 오차의 크기
e = 0.01
# 표본크기
n = ((z_score * s) / e) **2
print(f'표본크기: {math.ceil(n)}명') # 표본의 크기는 올림챕터9 연습문제5
Q. 화장지 도매업자가 새로 1,000개의 화장지를 들여와서 화장지의 평균 길이를 알아보기 위해 20개의 표본을 뽑아 길이를 재어 보았더니 평균 길이가 98.5m이고 표준편차는 3m 였다. 화장지 1,000개의 평균 길이에 대한 99% 신뢰구간을 설정하라.
# 화장지 평균 길이
import numpy as np
import scipy.stats as stats
# 주어진 데이터
mean = 98.5
s = 3 # 표본 표준편차
n = 20 # 표본 크기
# 신뢰수준 설정
confidence_level = 0.99
# t값 계산
t_score = t.ppf(1 - (1 - confidence_level) / 2, df=n-1)
# 신뢰구간 계산
margin_of_error = t_score * (s / np.sqrt(n))
confidence_interval = (mean - margin_of_error, mean + margin_of_error)
# 출력
print(f"{int(confidence_level * 100)}% 신뢰구간: {confidence_interval[0]:,.1f}m ~ {confidence_interval[1]:,.1f}m")
주어진 표본 데이터로부터 99% 신뢰구간을 계산하기 위해, t-분포를 사용하여 신뢰구간을 구할 수 있다.
99% 신뢰구간을 구하기 위해서는 t-값을 계산해야 합니다. 자유도는 n−1=19이며, 99% 신뢰수준에 해당하는 t-값을 구한 후 신뢰구간을 계산할 수 있다.
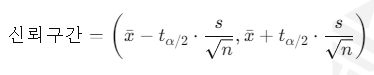
챕터9 연습문제6
Q. 어느 OTT 동영상 서비스를 구독하는 150명을 조사하여 보았더니 20대 구독자의 비율이 30%였다. 전체 구독자 중 20대 구독자의 비율에 대한 95% 신뢰구간을 구하라.
# OTT 서비스 구독자 중 20대 비율
import numpy as np
import scipy.stats as stats
total = 150 # 전체 조사대상
ott_20 = int(total * 0.3) # 20대 구독자 수
# 표본 비율
p = ott_20 / total # 30%
# 표본 표준 편차
Sp = ((p * (1 - p)) / total) ** 0.5
# 신뢰 수준 설정
confidence_level = 0.95
# z 값 계산
z_score = stats.norm.ppf(1 - (1 - confidence_level) / 2)
# 신뢰구간 계산
margin_of_error = z_score * Sp
confidence_interval = (p - margin_of_error, p + margin_of_error)
# 출력
print(f'표본 표준 편차: {Sp:.4f}')
print(f'Z값: {z_score:.2f}')
print(f"{int(confidence_level * 100)}% 신뢰구간: {confidence_interval[0]*100:,.2f}% ~ {confidence_interval[1]*100:,.2f}%")
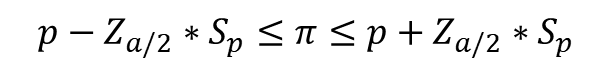
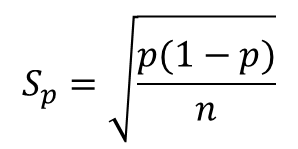
다음 내용
[파이썬+통계학] 현대통계학 연습문제 파이썬 구현(ch.10)
★ 시작에 앞서 ★ 해당 내용은 ', 다산출판사, 2024' 에 나와있는 챕터별 연습문제를 교재를 응용하여 풀이하고, 수학적인 문제에 대한 답변을 파이썬으로 구현해보기 위해 작성하는 글이다.해
puppy-foot-it.tistory.com
'[파이썬 Projects] > <파이썬 - 수학 | 통계학>' 카테고리의 다른 글
| [개발자를 위한 수학] 로지스틱 회귀와 분류 - 2 (0) | 2024.10.18 |
|---|---|
| [개발자를 위한 수학] 로지스틱 회귀와 분류 - 1 (3) | 2024.10.18 |
| [파이썬+통계학] 현대통계학 연습문제 파이썬 구현(ch.9)-1 (2) | 2024.10.17 |
| [개발자를 위한 수학] 선형 회귀 - 3 (7) | 2024.10.17 |
| [개발자를 위한 수학] 선형 회귀 - 2 (3) | 2024.10.16 |



