이전 내용
[개발자를 위한 수학] 로지스틱 회귀와 분류 - 1
로지스틱 회귀(logistic regression) 하나 이상의 독립 변수가 주어졌을 때 결과의 확률을 예측하는 알고리즘. 로지스틱은 선형 회귀와 유사하게 선형 방정식을 기반으로 하지만, 선형 회귀와는 달리
puppy-foot-it.tistory.com
다변수 로지스틱 회귀
여러 입력 변수에 대해 로지스틱 회귀를 사용하는 예제를 통해 로지스틱 회귀 분석 수행
예제 데이터는 고용 유지 데이터로 구성된 가상의 데이터셋이며, 54개의 표본이 있고, 이 데이터셋을 사용해 다른 직원의 퇴사 여부를 예측하는 데 로지스틱 회귀를 활용한다고 가정한다.

성별, 나이, 승진, 근무 연수에 대해 β 계수를 각각 만든다. 출력 변수 did_quit 는 0 또는 1이며, 이를 바탕으로 로지스틱 회귀의 예측 결과를 이끌어낸다.
[직원 데이터에 대한 다변수 로지스틱 회귀 분석 수행]
# 직원 데이터에 대한 다변수 로지스틱 회귀 분석 수행
import pandas as pd
from sklearn.linear_model import LogisticRegression
employee_data = pd.read_csv('https://tinyurl.com/y6r7qjrp')
# 독립 변수 열 추출
inputs = employee_data.iloc[:, :-1]
# 종속 변수인 'did_quit' 열 추출
outputs = employee_data.iloc[:, -1]
# 로지스틱 회귀 모델 만듦.
fit = LogisticRegression(penalty=None).fit(inputs, outputs)
# 모델 파라미터 출력
print('계수: {0}'.format(fit.coef_.flatten()))
print('절편: {0}'.format(fit.intercept_.flatten()))
# 새로운 직원 데이터로 테스트
def predict_employee_will_stay(sex, age, promotions, years_employed):
prediction = fit.predict([[sex, age, promotions, years_employed]])
probabilities = fit.predict_proba([[sex, age, promotions, years_employed]])
if prediction == [[1]]:
return "퇴사: {0}".format(probabilities)
else:
return "재직: {0}".format(probabilities)
# 예측 하기
while True:
n = input("직원이 떠날지 남을지 예측하기" +
"{sex},{age},{promotions},{years_employed}: ")
if n == "":
break
(sex, age, promotions, years_employed) = n.split(",")
print(predict_employee_will_stay(int(sex), int(age), int(promotions), int(years_employed)))
승진 1회, 근속 5년의 34세 직원의 값을 입력하면 퇴사로 출력한다.
| [코드 및 결과에 대한 설명] - predict_proba(): 0(거짓) 확률, 1(참) 확률 두 개의 값을 출력한다. - sex, age, promotions, years_employed 에 대한 계수가 순서대로 표시되며, 계수의 가중치를 보면 sex와 age가 예측의 거의 영향을 미치지 않는다. - 그러나 promotions와 years_employed 는 가중치가 꽤 크다는 것을 알 수 있다. |
그러나, 이 데이터셋에는 직원이 대략 2년마다 승진을 하지 않으면 그만두도록 조작했는데, 로지스틱 회귀 모델이 이런 패턴을 포착하여 다른 직원에게도 적용할 수 있다. 하지만 만약 3년 동안 승진하지 않은 70세 직원 등 훈련 데이터를 벗어난 데이터를 입력하면 해당 연령대의 데이터가 없기 때문에 예측이 빗나갈 가능성이 높다.
물론, 해당 모델을 현실에 실제로 적용하기에는 수 없는 변수들이 있어 현실성이 없다.
로그 오즈 이해하기
로짓 함수(logit function) 라고도 불리는 로그 오즈는 선형 함수를 취해 출력이 0과 1 사이가 되도록 스케일을 조정해 확률을 예측하는 목적을 위해 로지스틱 회귀에 적합하다.

e의 지수인 이 선형 함수를 로그 오즈 함수라고 하며, 관심 있는 사건에 대한 오즈에 로그를 취한 것이다.
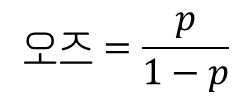
위의 공식은 확률에서 오즈를 계산하는 방법이며, 확률 함수를 자연로그(밑이 e인 로그)로 감싼 것을 로짓 함수라고 부르며, 오즈에 로그를 취하기 때문에 이 공식의 출력을 로그 오즈라고도 부른다.
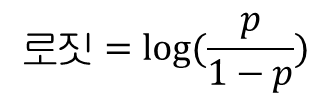
로그 오즈를 사용하면 다른 확률과 비교하기가 더 쉽다.
- 0보다 큰 값: 사건이 발생할 확률이 높다
- 0보다 작은 값: 사건이 발생하지 않을 확률이 높다.
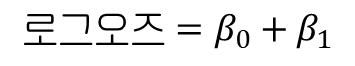
만약 로지스틱 회귀의 확률 p와 입력 변수 x가 주어지면 다음과 같다.
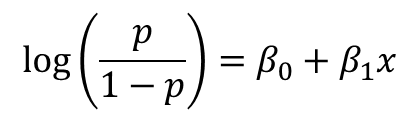
모든 로지스틱 회귀는 실제로 선형 함수에 의해 뒷받침되며, 이 선형 함수는 로그 오즈 함수이다. 예를들어 직선인 로그 오즈가 0.0이면 지스틱 함수의 확률은 0.5가 된다. 즉, 오즈가 1.0으로 사건이 일어날 확률과 그렇지 않을 확률이 같은 경우 로지스틱 회귀 확률은 0.5이고 로그 오즈는 0이다.
오즈 관점에서 로지스틱 회귀를 살펴볼 때 얻을 수 있는 또 다른 이점은 하나의 x값과 다른 x값 간의 효과를 비교할 수 있다.
만약 하나의 사건에 두 가지 조건이 있고, 그 사이에 오즈가 얼마나 변하는지를 파악하고 싶다면, 먼저 각 사건의 오즈를 구한 다음, 두 오즈를 서로 비교해 오즈 비(odds ratio)를 구한다. (이는 일반 오즈와는 다르다)
결정 계수
선형 회귀와 마찬가지로 로지스틱 회귀에도 결정 계수가 있다. 결정 계수는 주어진 독립 변수가 종속 변수를 얼마나 잘 설명하는지 나타낸다.

'훈련 전 로그 가능도'와 '훈련 후 로그 가능도'를 배우면 결정 계수를 계산할 수 있다.
[훈련 후 로그 가능도]
출력값을 로지스틱 곡선에 다시 투영하면 0.0에서 1.0 사이의 가능도를 얻을 수 있는데, 그다음 각 가능도에 로그를 취해 더하면 된다.
# 훈련 후 로그 가능도 계산
from math import log, exp
import pandas as pd
patient_data = pd.read_csv('http://bit.ly/33ebs2R', delimiter=',').itertuples()
b0 = -3.17576395
b1 = 0.69267212
def logistic_function(x):
p = 1.0 / (1.0 + math.exp(-(b0 + b1 * x)))
return p
# 로그 가능도 더하기
log_likelihood_fit = 0.0
for p in patient_data:
if p.y == 1.0:
log_likelihood_fit += log(logistic_function(p.x))
elif p.y == 0.0:
log_likelihood_fit += log(1.0 - logistic_function(p.x))
print(log_likelihood_fit)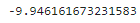
[훈련 전 로그 가능도]
입력 변수를 사용하지 않고 단순히 참(y = 1)인 표본의 수를 모든 표본의 개수로 나눈 값을 사용한다.
# 훈련 전 로그 가능도 계산
from math import log, exp
import pandas as pd
patient_data = list(pd.read_csv('http://bit.ly/33ebs2R', delimiter=',').itertuples())
likelihood = sum(p.y for p in patient_data) / len(patient_data)
log_likelihood = 0.0
for p in patient_data:
if p.y == 1.0:
log_likelihood += log(likelihood)
elif p.y == 0.0:
log_likelihood += log(1.0 - likelihood)
print(log_likelihood)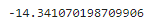
마지막으로 이 값을 사용해 결정 계수를 구한다.
# 로지스틱 회귀를 위한 결정 계수 계산
from math import log, exp
import pandas as pd
patient_data = list(pd.read_csv('http://bit.ly/33ebs2R', delimiter=',').itertuples())
# 훈련한 로지스틱 회귀 모델 계수
b0 = -3.17576395
b1 = 0.69267212
def logistic_function(x):
p = 1.0 / (1.0 + math.exp(-(b0 + b1 * x)))
return p
# 훈련 후 로그 가능도
log_likelihood_fit = sum(log(logistic_function(p.x)) * p.y + log(1.0 - logistic_function(p.x)) * (1.0 - p.y) for p in patient_data)
# 훈련 전 로그 가능도
log_likelihood = sum(p.y for p in patient_data) / len(patient_data)
log_likelihood = sum(log(likelihood) * p.y + log(1.0 - likelihood) * (1.0 - p.y) for p in patient_data)
# R2(결정 계수) 계산
r2 = (log_likelihood - log_likelihood_fit) / log_likelihood
print(r2)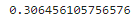
모델의 성능이 낮을수록 결정계수가 0.0에 가까워지고, 모델의 성능이 높을수록 1.0에 가까워진다.
p 값
결정 계수를 구한 다음에는 실제 연관성 때문이 아니라 우연히 이 데이터를 볼 가능성이 얼마나 되는지, 즉 p 값 구해 조사해야 한다. 이를 위해서는 확률 분포인 카이제곱 분포(chi-square distribution)을 알아야 하는데, 이 분포는 연속적이며 여러 통계 영역에서 사용된다.
표준 정규 분포(평균 0, 표준 편차 1)의 각 값을 제곱하면 자유도가 1인 카이제곱 분포가 된다.
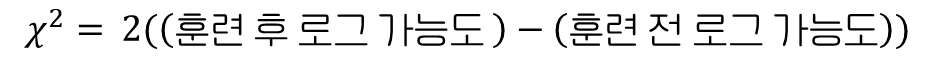
이를 사용해 카이제곱 분포로부터 어떤 값에 대한 확률을 얻을 수 있으며, 파이썬에서는 사이파이의 chi2 모듈을 사용한다.
# 로지스틱 회귀 모델의 p 값 계산하기
from math import log, exp
import pandas as pd
from scipy.stats import chi2
patient_data = list(pd.read_csv('http://bit.ly/33ebs2R', delimiter=',').itertuples())
n = 2
# 훈련한 로지스틱 회귀 모델 계수
b0 = -3.17576395
b1 = 0.69267212
def logistic_function(x):
p = 1.0 / (1.0 + math.exp(-(b0 + b1 * x)))
return p
# 훈련 후 로그 가능도
log_likelihood_fit = sum(log(logistic_function(p.x)) * p.y + log(1.0 - logistic_function(p.x)) * (1.0 - p.y) for p in patient_data)
# 훈련 전 로그 가능도
log_likelihood = sum(p.y for p in patient_data) / len(patient_data)
log_likelihood = sum(log(likelihood) * p.y + log(1.0 - likelihood) * (1.0 - p.y) for p in patient_data)
# p 값 계산하기
chi2_input = 2 * (log_likelihood_fit - log_likelihood)
p_value = chi2.pdf(chi2_input, n-1) # 자유도는 n-1
print(p_value)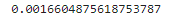
p값은 0.00166이며, 유의성 임곗값이 0.05이면 이 데이터는 통계적으로 유의미하며 무작위한 우연이 아니라고 평가한다.
훈련/테스트 분할
여러 개의 변수를 다룰 때에는 결정 계수와 p 값 같은 전통적인 통계 지표를 다루는 방법이 실용적이지 않기 때문에 훈련/테스트 분할이 유용하다.
아래는 앞서 진행했던 고용 유지 데이터셋에서 3-폴드 교차 검증으로 로지스틱 휘귀 모델을 훈련하는 코드이다.
그런 다음 1/3씩 테스트 데이터로 번갈아 사용하고 마지막으로 세 개의 정확도에 대한 평균 및 표준 편차를 계산한다.
# 3-폴드 교차 검증을 사용한 로지스틱 회귀 분석 수행
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import KFold, cross_val_score
# 데이터 로드
df = pd.read_csv("https://tinyurl.com/y6r7qjrp", delimiter=",")
X = df.values[:, :-1]
Y = df.values[:, -1]
# 랜덤 시드인 random_state 를 7로 설정
kfold = KFold(n_splits=3, random_state=7, shuffle=True)
model = LogisticRegression(penalty=None)
results = cross_val_score(model, X, Y, cv=kfold)
print("정확도 평균: {0:.3f} (표준 편차: {1:.3f})".format(results.mean(), results.std()))
오차 행렬(confusion matrix)
오차 행렬(또는 혼동 행렬)은 실제 결과에 대한 예측을 나누어
- 진짜 양성(TP, true positive)
- 진짜 음성(TN, true negative)
- 가짜 양성(FP, false positive)
- 가짜 음성(FN, false negative)
를 나타내는 표이다.
[참고하면 좋은 내용]
[파이썬] 성능 평가 지표 - 1 (정확도, 정밀도, 재현율, 오차 행렬)
시작에 앞서해당 내용은 ' 권철민 지음. 위키북스' 를 토대로 작성되었습니다. 보다 자세한 내용은 해당 서적에 상세히 나와있으니 서적을 참고해 주시기 바랍니다. 평가 머신러닝은 데이터 가
puppy-foot-it.tistory.com
[사이킷런에서 테스트 데이터셋에 대한 오차 행렬 만들기]
# 오차 행렬 만들기
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import train_test_split
# 데이터 로드
df = pd.read_csv("https://bit.ly/3cManTi", delimiter=",")
X = df.values[:, :-1]
Y = df.values[:, -1]
model = LogisticRegression(solver='liblinear')
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=.33, random_state=10)
model.fit(X_train, Y_train)
prediction = model.predict(X_test)
matrix = confusion_matrix(y_true=Y_test, y_pred=prediction)
print(matrix)
| 예측 false (Negative) |
예측 true (Positive) |
||
| 실제 false (Negative) |
6(TN) | 3 (FP) | 특이도 TN/(TN + FP) |
| 실제 true (Positive) |
4(FN) | 5 (TP) | 민감도(재현율) TP/(TP + FN) |
| 음성 예측도 TN / (TN + FN) |
정밀도 TP / (TP + FP) |
정확도 (TP + TN) / (TP + TN + FP + FN) |
[오차 행렬 + 성능 평가 지표]
# 로지스틱 회귀 기반 오차 행렬 + 평가 지표 계산 수행
# 오차 행렬 만들기
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix, accuracy_score, precision_score, recall_score
from sklearn.model_selection import train_test_split
# 데이터 로드
df = pd.read_csv("https://bit.ly/3cManTi", delimiter=",")
X = df.values[:, :-1]
Y = df.values[:, -1]
model = LogisticRegression(solver='liblinear')
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=.33, random_state=10)
model.fit(X_train, Y_train)
prediction = model.predict(X_test)
matrix = confusion_matrix(y_true=Y_test, y_pred=prediction)
# 평가지표 호출 함수
def get_clf_eval(Y_test, prediction):
accuracy = accuracy_score(Y_test, prediction)
precision = precision_score(Y_test, prediction)
recall = recall_score(Y_test, prediction)
print('정확도: {0:.1f}, 정밀도: {1:.1f}, 재현율: {2:.1f}'.format(accuracy, precision, recall))
print(matrix)
get_clf_eval(Y_test, prediction)
베이즈 정리
베이즈 정리를 사용해 외부 정보로부터 오차 행렬의 결과를 추가로 검증할 수 있다.

예를 들어, 아래와 같은 질병 검사를 받은 환자 1,000명의 오차 행렬 데이터가 있다고 하자.
| 테스트 결과: 양성 | 테스트 결과: 음성 | |
| 질병에 걸린 환자 | 198 | 2 |
| 질병에 걸리지 않은 환자 | 50 | 750 |
민감도 : 질병에 걸린 환자 중 성공적으로 식별한 정도
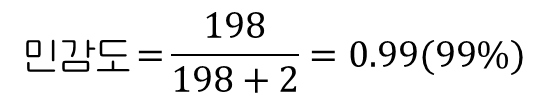
정밀도: 양성 판정을 받은 사람 중 실제로 질병에 걸린 사람의 비율
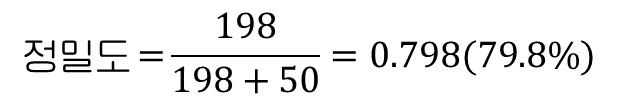
만약 실제로 인구의 1%가 이 질병에 걸렸다고 한다면, 실제로 질병을 앓고 있는 인구의 비율을 파악해 오차 행렬 결과에 반영하고, 이를 통해 중요한 사실을 발견할 수 있다.

※ 양성 예측 0.248은 전체 환자 중 테스트 결과가 양성인 환자의 비율이며,
테스트 결과 양성(198+50)/전체 환자(1000) 으로 구할 수 있다.
따라서, 진짜 양성을 성공적으로 식별할 확률이 3.39%에 불과하다면 이 테스트는 사용하지 않는 것이 좋다.
ROC 곡선과 AUC
다양한 머신러닝 모델을 평가할 때 수십, 수백 또는 수천 개의 오차 행렬이 만들어질 수 있어 이러한 행렬을 검토할 때는 ROC 곡선(receiver operator characteristic curve)으로 행렬을 요약할 수 있다.
또한 머신러닝 모델마다 별도의 ROC 곡선을 생성해 비교할 수도 있다.
AUC(area under curve)는 어떤 모델을 사용할지 선택하는 데 좋은 지표이다.
[ROC 커브와 AUC 관련 글]
[파이썬] 성능 평가 지표 - 3 (F1 스코어, ROC 곡선, AUC)
시작에 앞서해당 내용은 ' 권철민 지음. 위키북스' 를 토대로 작성되었습니다. 보다 자세한 내용은 해당 서적에 상세히 나와있으니 서적을 참고해 주시기 바랍니다. 이전 내용 [파이썬] 성능 평
puppy-foot-it.tistory.com
# 로지스틱 회귀 기반 오차 행렬 + 평가 지표 계산 수행 + roc_auc
# 오차 행렬 만들기
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix, accuracy_score, precision_score, recall_score, roc_auc_score, roc_curve
from sklearn.model_selection import train_test_split
import numpy as np
import matplotlib.pyplot as plt
# 데이터 로드
df = pd.read_csv("https://bit.ly/3cManTi", delimiter=",")
X = df.values[:, :-1]
Y = df.values[:, -1]
model = LogisticRegression(solver='liblinear')
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=.33, random_state=10)
model.fit(X_train, y_train)
prediction = model.predict(X_test)
matrix = confusion_matrix(y_true=Y_test, y_pred=prediction)
# 평가지표 호출 함수
def get_clf_eval(y_test, prediction):
accuracy = accuracy_score(y_test, prediction)
precision = precision_score(y_test, prediction)
recall = recall_score(y_test, prediction)
roc_auc = roc_auc_score(y_test, prediction)
print('정확도: {0:.1f}, 정밀도: {1:.1f}, 재현율: {2:.1f}, AUC: {3:.1f}'.format(accuracy, precision, recall, roc_auc))
pred_proba = model.predict_proba(X_test)
# 레이블 값이 1일 때의 예측 확률 추출
pred_proba_c1 = model.predict_proba(X_test)[:, 1]
# ROC 곡선
def roc_curve_plot(y_test, pred_proba_c1):
#임곗값에 따른 FPR, TPR 반환
fprs, tprs, threasholds = roc_curve(y_test, pred_proba_c1)
# ROC 곡선을 그래프 곡선으로 그림
plt.plot(fprs, tprs, label='ROC')
# 가운데 대각선 직선 그림
plt.plot([0, 1], [0, 1], 'k--', label='Random')
# FPR X측의 Scale을 0.1 단위로 변경, X, Y 축이름 설정
start, end = plt.xlim()
plt.xticks(np.round(np.arange(start, end, 0.1), 2))
plt.xlim(0, 1); plt.ylim(0, 1)
plt.xlabel('FPR(1- Specificity )'); plt.ylabel('TPR( Recall )')
plt.legend()
roc_curve_plot(y_test, pred_proba[:, 1])
print(matrix)
get_clf_eval(y_test, prediction)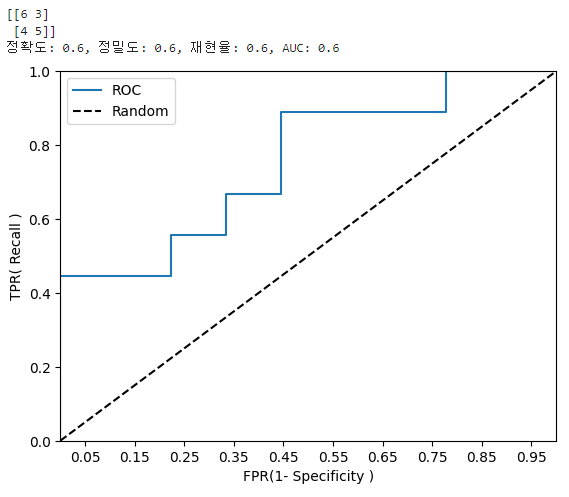
클래스 불균형
모든 출력 클래스에 걸쳐 데이터가 균등하게 표현되지 않을 때 발생하는 클래스 불균형은 머신러닝의 한 문제이며, 여러 문제에서 클래스 불균형이 발생된다.
클래스 불균형을 해결하기 위해 시도해볼 만한 몇 가지 방법들이 있다.
- 더 많은 데이터 수집
- 다른 모델 시도
- 오차 행렬 사용
- 클래스 비율이 동일하게 될 때까지 부족한 샘플 복제
- 크기가 작은 클래스의 표본을 합성하는 SMOTE 알고리즘 사용
- 희소한 사건을 찾도록 설계된 이상치 탐지 모델 사용(이상치를 찾으며, 비지도 알고리즘이라 분류 작업은 아님)
이 모든 것들이 잘못된 예측을 추적하고 사전에 오류를 포착하는 데 도움이 된다.
특히, 클래스의 비율이 동일하게 될 때까지 부족한 샘플을 복제하는 방법은
statify 매개변수에 클래스 값이 포함된 열을 전달하면 클래스 비율이 동일하도록 훈련/테스트 분할을 만든다.
X, Y = ...
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=.33, stratify=y)다음 내용
[개발자를 위한 수학] 신경망 - 1
신경망(neural network) 신경망은 입력 변수와 출력 변수 사이에 가중치, 편향, 비선형 함수로 이루어진 층을 쌓아 구성한다.딥러닝(Deep learning)은 신경망의 한 종류이며, 가중치와 편향을 가진 노드(
puppy-foot-it.tistory.com
[출처]
개발자를 위한 필수 수학
파이썬 머신러닝 완벽 가이드
'[파이썬 Projects] > <파이썬 - 수학 | 통계학>' 카테고리의 다른 글
| [개발자를 위한 수학] 신경망 - 2 (5) | 2024.10.20 |
|---|---|
| [개발자를 위한 수학] 신경망 - 1 (3) | 2024.10.20 |
| [개발자를 위한 수학] 로지스틱 회귀와 분류 - 1 (3) | 2024.10.18 |
| [파이썬+통계학] 현대통계학 연습문제 파이썬 구현(ch.9)-2 (6) | 2024.10.18 |
| [파이썬+통계학] 현대통계학 연습문제 파이썬 구현(ch.9)-1 (2) | 2024.10.17 |



